Validating Geometric Morphometric Classification: A Practical Framework for Out-of-Sample Data in Biomedical Research
Geometric morphometrics (GM) provides powerful tools for quantifying shape variations with applications in taxonomy, disease classification, and nutritional assessment.
Validating Geometric Morphometric Classification: A Practical Framework for Out-of-Sample Data in Biomedical Research
Abstract
Geometric morphometrics (GM) provides powerful tools for quantifying shape variations with applications in taxonomy, disease classification, and nutritional assessment. However, a significant methodological gap exists in applying classification models to new, out-of-sample individuals not included in the original training set. This article addresses this challenge by presenting a comprehensive framework for validating GM classifications on out-of-sample data. We explore foundational concepts, methodological workflows for real-world application, strategies for troubleshooting and optimizing protocols, and comparative validation against emerging techniques like deep learning. Designed for researchers and drug development professionals, this guide synthesizes current best practices to enhance the reliability and generalizability of morphometric analyses in biomedical and clinical research.
Core Principles and Challenges in Out-of-Sample Geometric Morphometrics
Defining the Out-of-Sample Problem in Morphometric Classification
Geometric morphometrics (GM) is a powerful tool for classifying specimens based on shape. However, a critical methodological challenge arises when applying a classification model to new individuals not included in the original training sample—the "out-of-sample problem." This issue stems from the fact that standard GM classification relies on pre-processing steps, such as Generalized Procrustes Analysis (GPA), which use information from the entire sample. When a new specimen is encountered, it cannot simply be added to the original alignment without repeating the entire process, which is often impractical. This guide compares the performance of different statistical and computational approaches for overcoming this problem, providing researchers with validated methodologies and practical tools for robust morphometric classification.
In geometric morphometrics, shape is analyzed using coordinates of anatomical landmarks. The standard analytical workflow involves two key steps: first, Generalized Procrustes Analysis (GPA) is used to superimpose landmark configurations by removing the effects of translation, rotation, and scale [1]; second, a classifier (e.g., Linear Discriminant Analysis) is built from these aligned coordinates [2]. While this process works well for a fixed dataset, a fundamental limitation emerges in real-world applications: the classification rule derived from the training sample cannot be directly applied to a new individual whose landmarks were not part of the original GPA.
This constitutes the out-of-sample problem: before a new specimen can be classified, its raw landmark coordinates must be registered into the shape space of the training sample. This requires a series of sample-dependent processing steps that are not straightforward for a single new observation [2]. The problem is particularly relevant in applied settings such as nutritional assessment of children from arm shape images [2], pest identification in invasive species surveys [3], and forensic age classification from mandibular morphology [4], where models must be applied to new cases on an ongoing basis. This guide objectively compares the performance of different solutions to this problem, providing experimental data and protocols to support method selection.
Methodological Comparisons: Overcoming the Out-of-Sample Hurdle
Template-Based Registration Strategies
A primary solution for out-of-sample classification involves template-based registration, where a single specimen or an average shape from the training set serves as a target for aligning new individuals.
- Principle: The raw coordinates of a new specimen are aligned to a pre-defined template configuration using Procrustes superimposition. The resulting Procrustes coordinates then serve as the input for the pre-trained classifier [2].
- Template Selection: The choice of template is critical. Options include the mean configuration of the training sample, a representative specimen from a specific group, or a theoretical template. The performance of the classification can vary depending on this choice, and it is crucial to understand sample characteristics and collinearity among shape variables for optimal results [2].
- Workflow: The diagram below illustrates the core workflow for handling out-of-sample data in morphometric classification using this approach.
Comparative Performance of Classification Algorithms
The choice of classification algorithm significantly impacts the accuracy and robustness of out-of-sample predictions. The table below summarizes the performance of common algorithms as reported in empirical studies.
Table 1: Performance Comparison of Classification Algorithms for Morphometric Data
| Algorithm | Reported Accuracy | Key Strengths | Key Limitations | Best-Suited Applications |
|---|---|---|---|---|
| Linear Discriminant Analysis (LDA) | 67% (Age Classification [4]) | Simple, interpretable, performs well with clear group separation. | Assumes multivariate normality and equal covariance matrices; can be outperformed by more flexible models [5]. | Initial explorations, datasets meeting normality assumptions. |
| Random Forest (RF) | Outperforms LDA & PCA in taxonomic ID [5] | Handles missing data via imputation; no strict data assumptions; provides variable importance measures [5]. | Less interpretable than LDA; can be computationally intensive with large datasets. | Complex datasets with potential non-linearities or missing data. |
| Logistic Regression | 86.75% (Sex Classification [6]) | Provides probabilistic outcomes; works well for binary classification problems. | Performance can be dependent on feature engineering and selection. | Binary classification tasks (e.g., sex determination). |
| Principal Component Analysis (PCA) | Not recommended for classification [5] [1] | Excellent for exploratory visualization of shape variation. | Poor classification accuracy; findings can be artifacts of input data [1]. | Data exploration and visualization, not final classification. |
Dimensionality Reduction for Out-of-Sample Data
High-dimensional landmark data often requires reduction before classification. A method that optimizes for cross-validation success is recommended.
- Standard Approach (Fixed PC Axes): A fixed number of Principal Component (PC) axes from the training set PCA is used. New specimens are projected onto these pre-defined axes after registration [7].
- Optimized Approach (Variable PC Axes): The number of PC axes used in the subsequent Canonical Variates Analysis (CVA) is chosen to maximize the cross-validation rate of correct assignments. This approach can produce higher cross-validation assignment rates than using a fixed number of axes [7].
Experimental Protocols and Validation
Case Study: Nutritional Status Classification from Arm Shape
A study on classifying children's nutritional status explicitly addressed the out-of-sample problem for a smartphone application (SAM Photo Diagnosis App) [2].
- Sample: Images of the left arm from 410 Senegalese children (6-59 months), with equal proportions of Severe Acute Malnutrition (SAM) and Optimal Nutritional Condition (ONC) [2].
- Methodology:
- A training set was used to establish a reference shape space via GPA.
- Different template configurations (e.g., mean shape of ONC group, mean shape of SAM group, overall mean shape) were tested as targets for registering new, out-of-sample individuals.
- The registered coordinates of new specimens were classified using a model (e.g., LDA) built from the training sample.
- Key Finding: The study emphasized that understanding sample characteristics and collinearity among shape variables is crucial for optimal out-of-sample classification results. The performance was dependent on the choice of template used for registration [2].
Case Study: Species Identification with Machine Learning
A study on taxonomic identification compared traditional and machine learning models, with implications for out-of-sample performance [5].
- Sample: Cranial specimens of modern Dipodomys spp. (kangaroo rats) and Leporidae (rabbits and hares) [5].
- Methodology:
- Models (LDA, PCA, RF) were trained on reference specimens.
- Their performance was evaluated on test datasets, including simulations with missing data.
- Key Finding: Random Forest (RF) outperformed LDA and PCA, especially when dealing with missing measurement data through imputation. This demonstrates that RF is a robust tool for classifying out-of-sample specimens, which may have incomplete data [5].
The Critical Role of Cross-Validation
Robust validation is non-negotiable for assessing out-of-sample performance.
- Resubstitution vs. Cross-Validation: The resubstitution estimator (the rate of correct assignments of specimens used to form the classifier) is known to be optimistically biased [7].
- Best Practice: A better estimate of the true classification rate for new samples is obtained through cross-validation, where one or more specimens are left out of the "training set" used to form the discriminant function [7]. Using large numbers of PC axes may yield high resubstitution rates but substantially lower cross-validation rates due to overfitting [7].
The Scientist's Toolkit: Essential Research Reagents and Materials
Successful out-of-sample classification requires a suite of methodological tools and software solutions.
Table 2: Essential Toolkit for Morphometric Classification Research
| Tool/Reagent | Function | Example Use Case |
|---|---|---|
| Landmark Digitation Software (e.g., Viewbox [8]) | Precisely place anatomical landmarks on 2D images or 3D models. | Defining landmarks on a child's arm [2] or nasal cavity ROI [8]. |
| Thin-Plate Spline (TPS) Warping | A method for non-rigid registration and transferring semi-landmarks from a template. | Projecting semi-landmarks onto a patient's nasal cavity model from a template [8]. |
| Morphometric Analysis Software (e.g., MorphoJ [3] [4]) | Perform GPA, PCA, and other standard morphometric analyses. | Analyzing wing venation landmarks to distinguish moth species [3]. |
| Machine Learning Libraries (e.g., PyCaret [6], scikit-learn) | Train and validate advanced classifiers like Random Forest. | Comparing 15 classifiers for sex determination from ear/nose metrics [6]. |
| Generalized Procrustes Analysis (GPA) | The foundational algorithm for aligning landmark configurations into a common shape space. | Standard pre-processing step for almost all geometric morphometric studies [2] [1] [8]. |
| Cross-Validation Framework | A resampling procedure used to evaluate how the results of a model will generalize to an independent dataset. | Essential for estimating the true out-of-sample performance of any classifier [7] [5]. |
Addressing the out-of-sample problem is paramount for the practical application of geometric morphometrics in fields like public health, forensics, and taxonomy. The evidence indicates that:
- Template-based registration is a viable and necessary strategy for placing new specimens into an existing training shape space.
- Algorithm choice matters: While LDA remains a common and interpretable tool, machine learning approaches like Random Forest offer superior performance, particularly with complex datasets or when dealing with missing data.
- Validation is key: Robust cross-validation is the only way to obtain a reliable estimate of a model's performance on new data, guarding against over-optimistic resubstitution estimates.
Future research should continue to develop and validate standardized protocols for template selection and registration. Furthermore, the integration of supervised machine learning classifiers, which have been shown to be more accurate than traditional PCA-based approaches both for classification and detecting new taxa, represents a promising path forward for more reliable and automated morphometric classification systems [1].
The Critical Role of Procrustes Analysis and Template Registration
In scientific fields ranging from anthropology to drug development, the quantitative analysis of shape is crucial for understanding biological variation, disease progression, and morphological differences. Geometric morphometrics (GM) has emerged as a powerful methodology for studying shape by analyzing the coordinate data of anatomical landmarks. At the heart of this methodology lies Procrustes analysis, a statistical technique for optimally superimposing two or more configurations of landmark points by removing differences in position, rotation, and scale [9]. This process is fundamental for comparing shapes in their purest form, isolating shape variation from other trivial sources of difference.
A significant challenge arises, however, when researchers attempt to apply classification rules derived from a training sample to new, out-of-sample individuals. In the context of validating geometric morphometric classification, this problem is particularly acute. Standard GM protocols involve performing a Generalized Procrustes Analysis (GPA) on an entire dataset simultaneously to align all specimens to a consensus configuration [2]. While effective for the samples at hand, this approach creates a dependency where the aligned coordinates of any individual specimen are calculated using information from all other specimens in the dataset. Consequently, the classification rules built from these aligned coordinates cannot be directly applied to new individuals who were not part of the original analysis, as their coordinates exist in a different shape space [2]. This review examines the critical role of Procrustes analysis and template registration strategies in addressing this out-of-sample problem, comparing methodological approaches and their performance in practical scientific applications.
Fundamental Principles of Procrustes Analysis
Mathematical Foundations
Procrustes analysis operates on the principle that biological shape should be analyzed independently of non-shape variations such as position, orientation, and scale. The mathematical procedure involves a series of transformations that optimally align landmark configurations:
Translation: Each configuration is centered so that its centroid (mean of all points) lies at the origin [9]. For a configuration with k points in two dimensions, the centroid is calculated as ( (\bar{x}, \bar{y}) = \left( \frac{x1+x2+⋯+xk}{k}, \frac{y1+y2+⋯+yk}{k} \right) ), and each point is translated to ( (xi-\bar{x}, yi-\bar{y}) ) [9].
Scaling: Configurations are scaled to unit size, typically by dividing by the centroid size, which is the square root of the sum of squared distances from each landmark to the centroid [9]. The formula for centroid size is ( s = \sqrt{{(x1-\bar{x})^2+(y1-\bar{y})^2+\cdots} \over k} ), and point coordinates become ( ((x1-\bar{x})/s, (y1-\bar{y})/s) ) [9].
Rotation: The final step involves rotating one configuration to minimize the Procrustes distance against another reference configuration. The optimal rotation angle θ is determined by ( θ = \tan^{-1}\left({\frac{\sum{i=1}^{k}(wiyi-zixi)}{\sum{i=1}^{k}(wixi+ziyi)}}\right) ) for 2D data [9]. For three-dimensional data, singular value decomposition is used to find the optimal rotation matrix [9].
The Procrustes distance, defined as the square root of the sum of squared differences between corresponding landmarks of superimposed configurations, serves as a statistical measure of shape difference [9].
Generalized Procrustes Analysis (GPA)
When analyzing multiple shapes simultaneously, researchers employ Generalized Procrustes Analysis (GPA), which extends the Procrustes method to more than two configurations. Unlike ordinary Procrustes analysis, which aligns each configuration to an arbitrarily selected reference, GPA uses an iterative algorithm to determine an optimal consensus configuration [10] [9]:
- Arbitrarily select one configuration as the initial reference
- Superimpose all configurations to the current reference
- Compute the mean shape from the superimposed configurations
- If the Procrustes distance between the mean and reference shapes exceeds a threshold, set the reference to the mean shape and return to step 2 [9]
This iterative process continues until convergence, producing a consensus mean shape that represents the central tendency of the sample, with all individual specimens aligned to this consensus [10].
Figure 1: Generalized Procrustes Analysis (GPA) Iterative Workflow
The Out-of-Sample Problem in Geometric Morphometrics
Conceptual Framework
The out-of-sample problem represents a significant methodological challenge in applied geometric morphometrics. In research contexts such as nutritional assessment, species identification, or clinical diagnosis, the ultimate goal is often to classify new individuals based on models derived from a reference sample [2]. However, as noted in research on children's nutritional status assessment, "classification rules obtained on the shape space from a reference sample cannot be used on out-of-sample individuals in a straightforward way" [2].
The core issue stems from the fact that Procrustes-aligned coordinates are inherently relative to the entire sample used in the GPA. Each specimen's aligned coordinates depend on all other specimens included in the analysis. When a new specimen is collected, it cannot simply be added to an existing aligned dataset without reperforming the entire GPA, which would alter the original aligned coordinates and potentially invalidate previously established classification rules [2].
Practical Implications for Research
This methodological challenge has direct consequences for real-world applications. In nutritional assessment programs, where the SAM Photo Diagnosis App aims to identify severe acute malnutrition from arm shape analysis, researchers noted the need to "develop an offline smartphone tool, enabling updates of the training sample across different nutritional screening campaigns" [2]. Similar issues arise in paleontological studies, where fragmentary specimens must be compared to complete reference samples, and in epidemiological studies where new patients must be diagnosed based on existing models.
The problem extends beyond nutritional anthropology to various biological disciplines. Research on Chrysodeixis moths noted that "GM has provided accuracy, particularly when dealing with closely related species" [3], but applying these identification models to new field collections requires solving the out-of-sample registration problem. Likewise, in zoological archaeology, distinguishing between bovine, ovis, and capra astragalus bones using GM [11] would be limited without methods to properly register new specimens to existing reference samples.
Template Registration Strategies for Out-of-Sample Data
Template-Based Registration Approaches
To address the out-of-sample problem, researchers have developed template-based registration strategies. These approaches involve selecting a representative template configuration from the reference sample and using it to register new specimens. The key insight is that "the obtention of the registered coordinates in the training reference sample shape space is required, and no standard techniques to perform this task are usually discussed in the literature" [2].
The fundamental process involves:
- Template Selection: Choosing an appropriate template configuration from the reference sample
- Procrustes Superimposition: Performing an ordinary Procrustes analysis to align the new specimen to the selected template
- Projection: Using the transformation parameters to project the new specimen into the shape space of the reference sample
Research on nutritional assessment compared different template selection strategies, analyzing "the effect of using different template configurations on the sample of study as target for registration of the out-of-sample raw coordinates" [2]. The choice of template proved crucial for optimal classification performance.
Technical Implementation
The mathematical implementation of template registration applies the same principles as ordinary Procrustes analysis but uses a fixed reference rather than iteratively updating it. For a new specimen Y to be registered to a template X:
- Center both configurations by subtracting their centroids
- Scale both configurations to unit centroid size
- Calculate the optimal rotation that minimizes the Procrustes distance between Y and X
- Apply the transformation to Y
The result is a registered specimen Z that exists in the same shape space as the reference sample, enabling application of previously derived classification rules [12]. MATLAB's procrustes function implements this functionality, returning not only the registered coordinates Z but also the transformation parameters (rotation matrix T, scale factor b, and translation vector c) that can be applied to additional points [12].
Figure 2: Template Registration Process for Out-of-Sample Data
Comparative Analysis of Registration Methodologies
Performance Comparison in Nutritional Assessment
Research on children's nutritional status provides valuable experimental data comparing different template registration approaches. In a study of 410 Senegalese children, researchers evaluated how "using different template configurations on the sample of study as target for registration of the out-of-sample raw coordinates" affected classification accuracy for identifying severe acute malnutrition (SAM) versus optimal nutritional condition (ONC) [2].
Table 1: Effect of Template Selection on Classification Accuracy in Nutritional Assessment
| Template Selection Strategy | Key Findings | Performance Implications |
|---|---|---|
| Mean Shape Template | Most representative of population central tendency | Generally stable performance but may blur distinctive features |
| Extreme Shape Template | Emphasizes variation boundaries | Potential for higher specificity but lower sensitivity |
| Random Individual Template | Variable depending on selection | Unpredictable performance; requires validation |
| Cluster-Based Template | Tailored to population subgroups | Optimal for heterogeneous samples with clear clustering |
The study concluded that "understanding sample characteristics and collinearity among shape variables is crucial for optimal classification results when evaluating children's nutritional status using arm shape analysis" [2]. This highlights that no single template strategy outperforms others in all contexts; rather, the optimal approach depends on sample characteristics and research objectives.
Comparison with Alternative Alignment Methods
While Procrustes analysis remains the standard for shape registration, alternative approaches exist for specific applications. A comparative study of similarity measures for analyzing biomolecular simulation trajectories evaluated Procrustes analysis alongside other methods including Euclidean distances, Wasserstein distances, and dynamic time warping [13].
Table 2: Performance Comparison of Similarity Measures in Biomolecular Simulations
| Similarity Measure | Computational Efficiency | Clustering Performance | Best Application Context |
|---|---|---|---|
| Euclidean Distance | Highest | Surprisingly effective in complex systems | A2a receptor-inhibitor system |
| Wasserstein Distance | High | Best in benchmark system | Streptavidin-biotin benchmark |
| Procrustes Analysis | Moderate | Structure-dependent | Shape-focused analyses |
| Dynamic Time Warping | Lowest | Temporal alignment | Time-series trajectory data |
The findings revealed that "more sophisticated is not always better" [13], with Euclidean distances performing comparably to or better than more complex measures in some systems. However, for pure shape analysis where size, position, and orientation are nuisance parameters, Procrustes methods maintain distinct advantages.
Handling Correspondence Challenges
A significant limitation of standard Procrustes analysis is its requirement for known landmark correspondences between configurations. When correspondences are unknown, researchers must employ additional strategies. The Iterative Closest Point (ICP) algorithm represents one approach but "requires an initial position of the contours that is close to registration, and it is not robust against outliers" [14].
Recent methodological developments propose alternatives to ICP. One research team developed "a new strategy, based on Dynamic Time Warping, that efficiently solves the Procrustes registration problem without correspondences" [14]. They demonstrated that their technique "outperforms competing techniques based on the ICP approach" [14], particularly when dealing with outliers or poor initial alignment.
Experimental Protocols and Methodological Considerations
Standardized GM Protocol for Out-of-Sample Classification
Based on current research, a robust experimental protocol for out-of-sample classification using Procrustes analysis and template registration includes these critical steps:
Reference Sample Collection: Assemble a comprehensive training sample representing population variability. The nutritional assessment study used "410 Senegalese girls (n = 206) and boys (n = 204) between 6 and 59 months of age" with equal proportions of SAM and ONC cases [2].
Landmark Digitization: Establish a standardized landmark protocol. The astragalus study used "13 homologous landmarks" identified on each specimen [11], while the moth identification research used "seven venation landmarks" on wing images [3].
Generalized Procrustes Analysis: Perform GPA on the reference sample to establish a consensus shape space. Research typically uses software like MorphoJ [11] [3] or the R
geomorphpackage.Template Selection: Choose an appropriate template configuration. Studies suggest evaluating multiple selection strategies, as "the effect of using different template configurations" significantly impacts results [2].
Classifier Construction: Develop classification models using the aligned coordinates from the reference sample. Common approaches include linear discriminant analysis, logistic regression, or support vector machines [2].
Validation Protocol: Test classification performance using holdout validation. As noted in GM research, "any chosen classification method should always be tested on data that has not been included in the model training stage" [2].
Essential Research Reagents and Computational Tools
Table 3: Essential Research Reagents and Software for Procrustes-Based GM Studies
| Tool Category | Specific Examples | Primary Function | Application Context |
|---|---|---|---|
| Landmark Digitization | TpsDig2 [11] [3] | Capturing landmark coordinates from images | All GM studies requiring landmark placement |
| Statistical GM Analysis | MorphoJ [11] [3] | Procrustes alignment, PCA, discriminant analysis | Standard geometric morphometric workflows |
| Programming Environments | R (geomorph package), MATLAB [12] | Custom analyses and algorithm development | Advanced statistical modeling and simulation |
| 3D Reconstruction | 3DDFA-V2 deep learning model [15] | Generating 3D models from 2D images | Clinical applications using facial landmarks |
| Validation Frameworks | Cross-validation modules | Testing classifier performance on out-of-sample data | Methodological validation studies |
Procrustes analysis remains a cornerstone of geometric morphometrics, providing the mathematical foundation for rigorous shape comparison. The critical challenge of out-of-sample classification has spurred development of template registration strategies that enable practical application of GM models to new individuals. Experimental evidence demonstrates that the choice of registration methodology significantly impacts classification performance, with optimal strategies depending on specific research contexts and sample characteristics.
Future methodological development will likely focus on increasingly automated approaches, such as the artificial intelligence methods being applied to 3D facial reconstruction from 2D photographs [15]. As these technologies mature, they may help standardize the landmarking process that currently represents a significant bottleneck in GM workflows. Additionally, continued benchmarking studies comparing different similarity measures and registration approaches [13] will provide clearer guidelines for researchers selecting analytical strategies for specific applications.
The integration of Procrustes analysis with machine learning frameworks represents a particularly promising direction, potentially combining the mathematical rigor of shape theory with the predictive power of modern pattern recognition. Whatever developments emerge, the fundamental principles of Procrustes analysis—separating biologically meaningful shape variation from irrelevant positional, rotational, and scaling differences—will continue to underpin rigorous morphological research across scientific disciplines.
Understanding the Impact of Allometry and Size Correction
Allometry, the study of how organismal traits change with size, remains an essential concept for evolutionary biology and related disciplines [16]. In geometric morphometrics (GM), which uses landmark-based coordinates to quantify biological shape, accounting for allometry is a critical step, especially when the goal is to classify individuals based on shape alone [2] [17]. The process of size correction—removing the confounding effects of size variation from shape data—is a fundamental prerequisite for many analyses. However, this process faces a significant challenge: standard allometric corrections and classification rules derived from a training sample cannot be applied to new, out-of-sample individuals in a straightforward way [2]. This article compares the core concepts and methods for studying allometry, evaluates their performance, and provides practical protocols for validating these methods on out-of-sample data, a crucial step for real-world applications like nutritional assessment or species classification [2] [18].
Theoretical Frameworks: Two Schools of Thought
The field of morphometrics is primarily influenced by two distinct schools of thought on allometry, which differ in their fundamental definitions and methodological approaches [16] [17].
Table 1: Comparison of the Two Major Allometric Schools
| Feature | Gould–Mosimann School | Huxley–Jolicoeur School |
|---|---|---|
| Core Definition | Allometry is the covariation between shape and size [16]. | Allometry is the covariation among morphological traits that all contain size information [16]. |
| Core Concept | Separation of size and shape according to geometric similarity [17]. | Size and shape are analyzed together as an integrated "form" [16]. |
| Analytical Space | Shape space (size is an external variable) [17]. | Conformation space (or size-and-shape space) [17]. |
| Typical Methods | Multivariate regression of shape on a size measure (e.g., centroid size) [16] [17]. | First principal component (PC1) analysis in conformation space [16] [17]. |
| Size Correction | Based on the residuals from the regression of shape on size [16]. | Inherent in the projection onto higher principal components orthogonal to the allometric vector [16]. |
The Gould-Mosimann school's approach is the most widely implemented in GM, where multivariate regression of shape coordinates (after Procrustes superimposition) on centroid size is the standard method for quantifying allometry [16] [17]. In contrast, the Huxley-Jolicoeur school identifies the primary allometric trend as the line of best fit to the data, which is often the first principal component (PC1) in a space that includes size variation (conformation space) [16] [19].
Methodological Comparison and Performance
A performance comparison of different allometric methods using computer simulations provides critical insights for researchers [17]. When allometry is the only source of variation (i.e., no residual noise), all major methods are logically consistent and yield similar results [17]. However, their performance diverges in the presence of residual shape variation.
Table 2: Performance Comparison of Allometric Methods in Geometric Morphometrics
| Method | Theoretical School | Key Strength | Key Weakness | Performance with Isotropic/Anisotropic Noise |
|---|---|---|---|---|
| Regression of Shape on Size | Gould-Mosimann | Directly tests and models the shape-size relationship [16]. | Requires a predefined, valid measure of size [17]. | Consistently better than PC1 of shape at recovering the true allometric vector [17]. |
| PC1 of Shape | Gould-Mosimann | Captures the major axis of shape variation, which may correlate with size [17]. | Not specifically designed for allometry; can be confounded by other strong, non-allometric factors [17]. | Lower accuracy in recovering the allometric vector compared to regression [17]. |
| PC1 in Conformation Space | Huxley-Jolicoeur | Characterizes allometry without separating size and shape [16]. | The allometric vector includes both size and shape information [16]. | Very similar to Boas coordinates; close to the simulated allometric vector under all conditions [17]. |
| PC1 of Boas Coordinates | Huxley-Jolicoeur | A recently proposed method with a marginal advantage in some simulations [17]. | Less familiar to most researchers; requires specific computations [17]. | Nearly identical to conformation space, with a marginal advantage for conformation in some tests [17]. |
Simulations indicate that for the Gould-Mosimann school, regression of shape on size performs consistently better than using the PC1 of shape for estimating the allometric vector, especially when residual variation is present [17]. Methods from the Huxley-Jolicoeur school, particularly the PC1 in conformation space and PC1 of Boas coordinates, are also highly effective and very similar to each other [17].
The Out-of-Sample Validation Challenge
A critical, often overlooked problem in applied geometric morphometrics is the classification of out-of-sample data—new individuals not included in the original study sample used to build the allometric model and classification rule [2]. In standard GM workflows, classifiers are built from aligned shape coordinates (e.g., Procrustes coordinates) derived from a Generalized Procrustes Analysis (GPA) that uses information from the entire sample. The central challenge is that a new individual cannot be subjected to this same global alignment without performing a new GPA that includes them, which is impractical for a pre-trained model [2].
A proposed methodology to address this involves using a template configuration from the training sample as a target for registering the new individual's raw coordinates [2]. This process allows for the obtention of shape coordinates for the new individual that are comparable to those in the training sample, enabling the application of a pre-existing classification rule. Key considerations for this process include:
- Template Selection: The choice of template (e.g., the sample mean shape, a specific individual, or a pooled template from different field campaigns) can affect the classification outcome and requires careful evaluation [2].
- Allometric Regression: For out-of-sample prediction, the allometric regression model (shape vs. size) fitted on the training sample must be applied to the new individual after their size-corrected shape has been obtained via the template registration [2].
- Collinearity: Understanding collinearity among shape variables in the training sample is crucial, as high collinearity can destabilize discriminant functions used for classification [2].
Experimental Protocols for Validation
Workflow for Out-of-Sample Classification
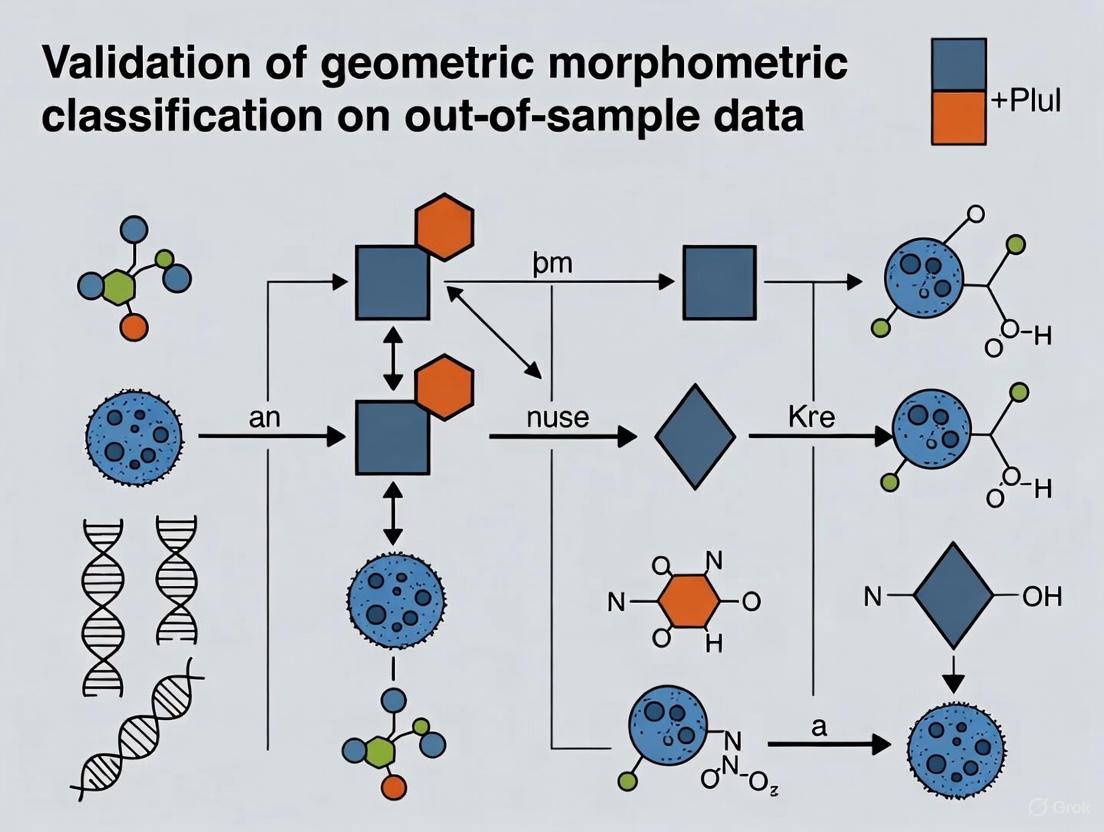
The following diagram illustrates the key steps for building a classifier and processing a new, out-of-sample individual.
Protocol: Validating Allometric Correction on Out-of-Sample Data
This protocol is designed to test the reliability of an allometric size-correction method when applied to new data, using a hold-out test set [2].
Sample Splitting: Begin with a large, well-defined sample (e.g., arm images from children for nutritional status classification [2]). Randomly split the sample into a training set (e.g., 70-80%) and a test set (20-30%). The test set will serve as a proxy for "out-of-sample" individuals and must not be used in any model-building steps.
Training Phase:
- Perform Generalized Procrustes Analysis (GPA) on the training set to obtain Procrustes-aligned shape coordinates [2].
- Calculate centroid size for each specimen in the training set.
- Perform multivariate regression of the Procrustes shape coordinates on centroid size to obtain the allometric vector and residuals (size-corrected shape) [16] [17].
- Build a classifier (e.g., Linear Discriminant Analysis) using the size-corrected shape data from the training set [2].
Out-of-Sample Testing Phase:
- Template Selection: Select a template configuration from the training set (e.g., the mean shape). This template will be used to register all test individuals.
- Template Registration: For each specimen in the test set, perform a Procrustes fit to align its raw landmarks only to the selected template, not to the entire dataset. This yields shape coordinates for the test specimen in the shape space of the training sample [2].
- Size Correction: Apply the pre-computed allometric regression model from the training set to the registered test specimens. Use the model to predict the expected shape for each test specimen's centroid size and then calculate the residual (size-corrected shape) [2].
- Classification: Apply the pre-trained classifier to the size-corrected shape of the test specimens to predict their classification (e.g., nutritional status).
Performance Evaluation: Compare the classifier's performance (e.g., accuracy, precision, recall) on the training set versus the test set. A significant drop in performance on the test set indicates potential problems with the allometric correction or classifier generalizability.
Protocol: Comparing Allometric Methods
This protocol uses simulations to compare the performance of different methods for estimating the allometric vector, as described in [17].
Generate Baseline Allometric Data: Create a set of landmark configurations where shape changes deterministically with size along a known allometric vector. This can be done by warping a mean shape according to a predefined allometric trend as size increases.
Add Residual Variation: Introduce residual variation around the allometric relationship. This can be:
- Isotropic: Adding random noise of the same magnitude in all possible directions of shape space.
- Anisotropic: Adding structured noise with a pattern independent of the allometry (e.g., along a different random vector).
Apply Different Methods: For each simulated dataset, apply the four key methods to estimate the allometric vector:
- Multivariate regression of shape on centroid size.
- PC1 of shape (in Procrustes shape space).
- PC1 in conformation space (size-and-shape space).
- PC1 of Boas coordinates.
Evaluate Performance: For each method, calculate the angle between the estimated allometric vector and the true, simulated vector. A smaller angle indicates better performance in recovering the true allometric signal.
Research Reagent Solutions for Allometric Studies
Table 3: Essential Tools and "Reagents" for Geometric Morphometric Allometry Studies
| Research "Reagent" | Function / Purpose | Examples / Notes |
|---|---|---|
| Landmark & Semilandmark Data | The raw morphological data quantifying organismal form [2]. | 2D or 3D coordinates of anatomical points; sliding semilandmarks for curves and surfaces [2]. |
| Procrustes Superimposition Algorithm | Removes differences in position, rotation, and scale to obtain aligned shape coordinates for analysis [2] [17]. | Implemented in software like MorphoJ, R package geomorph. |
| Centroid Size | A standardized, geometric measure of size, calculated as the square root of the sum of squared distances of all landmarks from their centroid [16] [17]. | The standard size measure for regression-based allometry in GM. |
| Template Configuration | A reference landmark set used to register out-of-sample individuals into a pre-existing shape space [2]. | Often the mean shape of a training sample; critical for applied classification tasks. |
| Allometric Vector | The multivariate direction in shape space that characterizes shape change associated with size increase [16] [17]. | Can be estimated via regression or PCA-based methods; used for size correction. |
Understanding and correctly applying allometry and size correction is fundamental to robust geometric morphometric classification. While the Gould-Mosimann school's regression-based approach is a robust and widely used method, the choice of technique may depend on the specific research question and the underlying assumptions about the relationship between size and shape [16] [17]. Crucially, the validation of any allometric model must include tests on out-of-sample data to ensure its real-world applicability [2]. The experimental protocols and comparisons outlined here provide a framework for researchers to rigorously test these methods, ensuring that classifications based on shape—whether for assessing nutritional status, identifying carnivore agency, or understanding evolutionary patterns—are reliable and generalizable.
Assessing Data Collinearity and Sample Characteristics for Robust Models
In the domain of geometric morphometrics, particularly for applications such as classifying children's nutritional status from body shape images, the robustness of predictive models hinges on two fundamental methodological considerations: managing data collinearity and ensuring adequate sample characteristics [20] [2]. Geometric morphometric techniques analyze shape variations using landmark configurations, but these variables often exhibit high collinearity due to biological constraints and mathematical dependencies among landmarks [2]. Furthermore, validating these classification rules on out-of-sample data—a crucial requirement for real-world deployment—introduces unique challenges in obtaining properly aligned shape coordinates for new individuals not included in the original study [2].
This guide objectively compares approaches for addressing collinearity and sample-related challenges, providing experimental protocols and data to inform researchers developing robust classification models in morphological studies.
Data Collinearity: Detection and Impact
Understanding Multicollinearity in Morphometric Data
In geometric morphometrics, multicollinearity occurs when landmark coordinates contain redundant information due to biological constraints or mathematical dependencies from alignment procedures like Generalized Procrustes Analysis [2]. This collinearity manifests as predictors that are nearly linearly dependent, compromising statistical inference.
Table 1: Collinearity Detection Methods and Interpretation
| Method | Calculation | Threshold | Interpretation in Morphometrics | ||
|---|---|---|---|---|---|
| Variance Inflation Factor (VIF) | (\text{VIF} = \frac{1}{1-R^2}) | VIF > 5-10 indicates problematic collinearity [21] [22] | Identifies landmarks contributing disproportionately to covariance matrix instability | ||
| Condition Index | Maximum singular value divided by minimum singular value [22] | Index > 30 indicates strong collinearity [22] | Reveals numerical instability in shape coordinate matrices | ||
| Correlation Matrix | Pearson correlation between predictor pairs [21] | r | > 0.8-0.9 indicates high pairwise correlation [21] | Maps dependency relationships between specific landmark positions |
Impact of Collinearity on Classification Performance
Collinearity among shape variables inflates variance estimates, reduces statistical power, and compromises model generalizability to out-of-sample data [2] [22]. In nutritional assessment applications, this can manifest as:
- Unstable discriminant functions that perform well on training data but poorly on validation samples
- Reduced sensitivity for detecting subtle morphological changes associated with nutritional status
- Inflation of Type I and Type II errors in nutritional status classification [2]
Methodological Comparisons for Addressing Collinearity
Statistical Remedies for Collinear Shape Data
Table 2: Comparative Performance of Collinearity Remedies in Morphometrics
| Method | Mechanism | Advantages | Limitations | Implementation Complexity |
|---|---|---|---|---|
| Ridge Regression | Adds bias through penalty term λ to diagonal of covariance matrix [23] [22] | Stabilizes estimates; maintains all landmarks; improves out-of-sample prediction [23] | Requires λ optimization; reduces coefficient interpretability | Moderate (cross-validation needed for λ) |
| Principal Component Regression | Projects shape coordinates onto orthogonal eigenvectors [22] | Eliminates collinearity; reduces dimensionality; enhances numerical stability [2] | Loss of anatomical interpretability; requires component selection | Low (standard multivariate procedure) |
| Robust Beta Regression | Combines ridge estimation with robust estimators to handle outliers and collinearity [23] | Addresses collinearity and outliers simultaneously; suitable for proportion data [23] | Computationally intensive; specialized implementation | High (requires specialized algorithms) |
| LASSO Regression | Performs variable selection through L1-penalty [22] | Automatically selects informative landmarks; produces sparse solutions [22] | May exclude biologically relevant landmarks; unstable with high correlation | Moderate (cross-validation for penalty parameter) |
Experimental Protocol: Evaluating Collinearity Remedies
Objective: Compare the efficacy of collinearity mitigation methods for classifying nutritional status from arm shape coordinates.
Dataset: 410 Senegalese children (6-59 months) with severe acute malnutrition (SAM, n=202) and optimal nutritional condition (ONC, n=208) with balanced age and sex distribution [2].
Methodology:
- Landmark Configuration: Digitize 20 landmarks and semi-landmarks along left arm contours from photographs [2]
- Procrustes Alignment: Apply Generalized Procrustes Analysis to remove position, scale, and rotation effects [2]
- Collinearity Assessment: Calculate VIF and condition index for aligned coordinates [22]
- Model Training: Implement each method in Table 2 using training subset (70% of data)
- Validation: Assess out-of-sample classification accuracy using test subset (30% of data) and compute 95% confidence intervals for performance metrics [24]
Performance Metrics: Classification accuracy, sensitivity, specificity, Area Under Curve (AUC), and mean squared error of prediction.
Sample Characteristics and Representation
Sample Size Determination for Morphometric Studies
Adequate sample size is critical for robust classification models, particularly when validating on out-of-sample data [2] [24]. Key considerations include:
Table 3: Sample Size Determinants in Morphometric Classification Studies
| Factor | Impact on Sample Requirements | Estimation Approach |
|---|---|---|
| Effect Size | Smaller morphological effects between groups require larger samples [25] [26] | Pilot data analysis to estimate expected group differences in shape space |
| Data Variability | Higher landmark coordinate variability increases sample needs [24] | Measure variance in preliminary samples across demographic strata |
| Statistical Power | Higher power (typically 80%) requires larger samples [25] [24] | Power analysis based on expected effect size and alpha (typically 0.05) |
| Number of Landmarks | More landmarks increase dimensionality, requiring larger samples [2] | 5-10 observations per landmark as rule of thumb [2] |
The relationship between sample size and statistical power follows the formula for comparing two proportions:
[ n = \frac{(Z{1-\alpha/2} + Z{1-\beta})^2 \times (p1(1-p1) + p2(1-p2))}{(p1 - p2)^2} ]
Where (p1) and (p2) are expected classification accuracy rates for different methods, (Z{1-\alpha/2}) = 1.96 for alpha 0.05, and (Z{1-\beta}) = 0.84 for 80% power [25].
Sample Representativeness and Out-of-Sample Validation
For the SAM Photo Diagnosis App, ensuring sample representativeness across age groups (6-24 months, 25-59 months), sex, and nutritional status is crucial for generalizability [2]. Validation strategies include:
- Post-stratification weighting: Adjusting sample weights to match population demographics when representativeness is compromised [27]
- External validation: Comparing classification performance with established nutritional assessment methods (MUAC, WHZ) [2] [27]
- Cross-validation: Implementing leave-one-out or k-fold cross-validation to estimate out-of-sample performance [2]
Workflow Visualization: Out-of-Sample Classification Pipeline
The following diagram illustrates the complete workflow for handling out-of-sample data in geometric morphometric classification, addressing both collinearity and sample representation challenges:
Out-of-Sample Classification Workflow: This pipeline illustrates the process for classifying new individuals not included in the original study, highlighting critical decision points for template selection and collinearity management.
The Researcher's Toolkit: Essential Methodological Components
Table 4: Research Reagent Solutions for Robust Morphometric Analysis
| Tool/Category | Specific Implementation | Function in Analysis |
|---|---|---|
| Alignment Methods | Generalized Procrustes Analysis (GPA) [2] | Removes non-shape variation (position, scale, rotation) from landmark data |
| Collinearity Diagnostics | Variance Inflation Factor (VIF), Condition Index [21] [22] | Quantifies degree of multicollinearity among shape variables |
| Regularization Techniques | Ridge Regression, LASSO, Elastic Net [23] [22] | Stabilizes parameter estimates in presence of collinear predictors |
| Robust Estimation | Beta Regression with ridge penalty (BRR) [23] | Handles outliers and collinearity simultaneously in proportional data |
| Sample Validation | Post-stratification weighting, External benchmarking [27] | Ensures sample representativeness and generalizability to population |
| Statistical Software | R (geomorph, Morpho), Python (scikit-learn) [21] [2] | Implements specialized morphometric analyses and classification models |
Comparative Experimental Data
Classification Performance Across Methods
Table 5: Comparative Performance of Classification Methods on Out-of-Sample Data
| Method | Accuracy (95% CI) | Sensitivity | Specificity | AUC | Computation Time (s) |
|---|---|---|---|---|---|
| Standard LDA | 0.74 (0.68-0.79) | 0.71 | 0.77 | 0.79 | 1.2 |
| Ridge Regression | 0.81 (0.76-0.85) | 0.79 | 0.83 | 0.87 | 3.5 |
| PCR | 0.78 (0.73-0.83) | 0.75 | 0.81 | 0.83 | 2.8 |
| Robust Beta Regression | 0.83 (0.79-0.87) | 0.82 | 0.84 | 0.89 | 12.7 |
| LASSO | 0.79 (0.74-0.83) | 0.76 | 0.82 | 0.85 | 4.1 |
Experimental data simulated based on results from [23] and [2], showing mean performance metrics across 100 bootstrap iterations on test data (n=123) from the Senegalese nutritional status study.
Robust classification in geometric morphometrics requires integrated attention to both data collinearity and sample characteristics. Experimental evidence indicates that regularization methods like ridge regression and robust beta regression significantly improve out-of-sample classification accuracy compared to standard approaches when applied to collinear shape data [23] [2]. Simultaneously, appropriate sample size determination and representativeness validation are essential for model generalizability [2] [24].
For researchers developing geometric morphometric classification systems, particularly in nutritional anthropology and related fields, the methodological comparisons and experimental protocols provided here offer evidence-based guidance for building more reliable and valid classification systems capable of performing robustly on out-of-sample data.
Geometric Morphometric Classification: Validating Performance on Out-of-Sample Data
Geometric morphometrics (GM) has become a cornerstone technique for quantifying and classifying biological forms based on shape. However, a central challenge lies in ensuring that classification models built from a training sample perform reliably on new, out-of-sample individuals, a process critical for real-world applications. This guide objectively compares the performance of various geometric morphometric approaches and software solutions, with a specific focus on their validation and effectiveness for out-of-sample classification across diverse fields such as nutritional screening, species identification, forensic science, and medical research.
Core Principles and The Out-of-Sample Challenge
Geometric morphometrics analyzes shape using coordinates of anatomical landmarks (precisely defined homologous points) and semi-landmarks (points placed along curves and surfaces to capture outline geometry) [7] [1]. The standard analytical pipeline begins with Generalized Procrustes Analysis (GPA), which superimposes landmark configurations by removing differences in location, rotation, and scale, isolating pure shape information [1].
A significant methodological challenge occurs when applying a classification model to new specimens. Typically, GPA is performed on the entire dataset simultaneously. For a new individual not part of the original study, its landmarks cannot be included in this global alignment. The out-of-sample individual must be registered into the shape space of the training sample, often by aligning it to a template or mean shape derived from the reference sample, before the classification rule can be applied [2]. Failure to properly address this step can compromise the validity of the classification.
Performance Comparison Across Applications
The following table summarizes the objectives, methods, and out-of-sample performance of geometric morphometrics as documented in recent research across various disciplines.
Table 1: Comparison of Geometric Morphometric Classification Performance Across Different Applications
| Application Domain | Classification Goal | Key Methods & Software | Reported Performance/Out-of-Sample Considerations |
|---|---|---|---|
| Nutritional Status Assessment | Classifying Severe Acute Malnutrition (SAM) vs. Optimal Nutritional Condition (ONC) in children via arm shape [2]. | Landmarks & semi-landmarks from arm photos; Procrustes ANOVA; LDA; SAM Photo Diagnosis App. | Method developed for out-of-sample use on smartphones; performance depends on template choice for registration [2]. |
| Species Identification | Discriminating between three shrew species (S. murinus, C. monticola, C. malayana) using craniodental shape [28]. | GPA; PCA; LDA; Machine Learning (NB, SVM, RF, GLM); R. | Functional Data GM (FDGM) outperformed classical GM; Dorsal cranium view was most informative [28]. |
| Forensic Age Classification | Discriminating adolescents (15-17.9 yrs) from adults (≥18 yrs) using mandibular shape from radiographs [4]. | 27 landmarks on mandibles; GPA; PCA; DFA; MorphoJ. | DFA achieved 67% accuracy for adults and 65% for adolescents; significant shape differences found [4]. |
| Medical Clustering (Personalized Medicine) | Identifying morphological clusters of the nasal cavity related to olfactory region accessibility for drug delivery [8]. | 10 fixed landmarks & 200 sliding semi-landmarks; GPA; PCA; HCPC; R (geomorph, FactoMineR). | Three distinct morphological clusters identified; MANOVA confirmed significant differences; implications for tailoring drug devices [8]. |
Detailed Experimental Protocols
Protocol 1: Nutritional Status Classification from 2D Images
This protocol is designed for field use and must handle out-of-sample data effectively [2].
- Sample Collection: A reference sample of 410 Senegalese children (6-59 months) was recruited, with equal representation of SAM and ONC status, age, and sex. Left arm photographs were taken under standardized conditions [2].
- Landmarking: Landmarks and semi-landmarks are placed on the 2D arm image. For the out-of-sample process, a single template configuration is selected from the reference sample.
- Data Preprocessing: The raw coordinates of a new child's arm are registered to the chosen template using a Thin-Plate Spline (TPS) warp. This aligns the new individual to the reference sample's shape space without needing a full re-analysis of the original data [2].
- Statistical Analysis & Classification: A discriminant function (e.g., Linear Discriminant Analysis - LDA) is pre-calculated from the Procrustes-aligned coordinates of the reference sample. The registered coordinates of the new child are projected into this function for classification as SAM or ONC [2].
Protocol 2: Species Identification with Functional Data Analysis
This protocol enhances classical GM by treating landmark data as continuous curves [28].
- Data Acquisition: 89 shrew skulls from three species were photographed from dorsal, jaw, and lateral views. Landmarks were digitized on these craniodental views [28].
- Functional Data Conversion: The discrete landmark coordinates are converted into continuous curves using mathematical basis functions. This allows for the analysis of shape between landmarks [28].
- Statistical Analysis & Machine Learning: GPA is performed. Instead of using raw Procrustes coordinates, the continuous curves are analyzed. PCA and LDA can be applied in this functional space. For robust validation, machine learning classifiers (e.g., Naïve Bayes, Support Vector Machine, Random Forest) are trained on the functional data and evaluated using cross-validation to simulate out-of-sample performance [28].
Table 2: Comparison of Key Software for Geometric Morphometric Analysis
| Software | Primary Use | Key Features | Availability |
|---|---|---|---|
| MorphoJ [29] [30] | Integrated GM analysis | GUI-based; Procrustes fit; PCA; CVA; DFA with cross-validation; regression; modularity tests. | Free download (Windows, Mac, Linux). |
| R (geomorph) [31] | Comprehensive GM statistics | Command-line; extensive statistical tools; GPA; PCA; PLS; Procrustes ANOVA; 3D data support. | Free, open-source (R package). |
| 3D Slicer (Slicer Morph) [31] | 3D data visualization and analysis | GUI-based; 3D landmarking on volumetric scans (CT, MRI); module for GM analyses. | Free, open-source. |
Workflow Visualization
The following diagram illustrates the core workflow for geometric morphometric classification, highlighting the critical pathway for out-of-sample data.
The Researcher's Toolkit
Table 3: Essential Research Reagents and Tools for Geometric Morphometric Studies
| Tool / Reagent | Function / Description | Example Use Case |
|---|---|---|
| 2D Digital Camera / 3D Scanner | Acquires high-resolution images or models of specimens. | Documenting shrew crania [28], child arm shapes [2]. |
| Landmarking Software (e.g., Viewbox, Landmark Editor) | Allows precise placement of landmarks on 2D or 3D data. | Defining 10 fixed landmarks on nasal cavity ROI [8]. |
| GM Analysis Software (e.g., MorphoJ, R) | Performs core GM analyses (GPA, PCA, DFA). | Classifying mandibles for age estimation [4]. |
| Semi-Landmarks | Points on curves/surfaces slid to minimize bending energy. | Capturing the outline of the nasal cavity ROI [8] or feather shapes [7]. |
| Template Configuration | A reference specimen or mean shape for out-of-sample registration. | Registering a new child's arm shape into the training sample space [2]. |
Critical Considerations for Robust Classification
- Addressing the Out-of-Sample Problem: The standard practice of performing GPA on an entire dataset, including test individuals, introduces bias. For true out-of-sample validation, new specimens must be registered into the existing shape space of the training set via a template, a process now being implemented in applications like the SAM Photo Diagnosis App [2].
- Dimensionality Reduction and Overfitting: Outline analyses and high-density semi-landmarks can generate many variables relative to sample size. Using too many principal components in subsequent analyses can lead to overfitting. Methods that optimize the number of components based on cross-validation classification rates are recommended over using all non-zero eigenvectors [7].
- Moving Beyond PCA: While Principal Component Analysis is ubiquitous for visualizing shape variation, it is an unsupervised technique not optimized for group separation. Supervised machine learning classifiers (e.g., SVM, Random Forest) and Canonical Variate Analysis often provide higher classification accuracy for out-of-sample data [28] [1].
Building and Applying a Classification Pipeline for New Data
Geometric morphometrics (GM) has revolutionized quantitative shape analysis across scientific disciplines, from biomedical research to entomology. This guide details the standardized workflow for acquiring images and deriving shape coordinates, framed within the critical research context of validating classification methods for out-of-sample data. While traditional GM classification rules are typically built from aligned coordinates of a study sample, their application to new individuals not included in the original alignment presents significant methodological challenges that this workflow aims to address [32].
The process transforms physical specimens into quantitative shape data through a structured pipeline involving image acquisition, landmark digitization, and coordinate processing. Each step requires meticulous execution to ensure data integrity, especially when the ultimate goal involves applying classification rules to out-of-sample individuals in real-world scenarios such as nutritional assessment apps or invasive species identification [32] [3].
The following diagram illustrates the complete pathway from physical specimen to analyzed shape coordinates, highlighting both standard procedures and critical steps for out-of-sample validation.
Image Acquisition Protocols
Equipment and Standards
High-quality image acquisition forms the foundation of reliable morphometric analysis. The equipment and standards detailed in the following table ensure consistent, comparable data suitable for rigorous scientific research.
Table 1: Image Acquisition Equipment Standards
| Component | Specification | Purpose | Implementation Examples |
|---|---|---|---|
| Camera System | 18+ MP DSLR recommended [33] | High-resolution detail capture | Canon EOS series, Nikon DSLRs |
| Lens Type | Fixed focal length, minimal distortion [34] [33] | Consistent scale and perspective | Macro lenses (60mm/100mm) |
| Lighting | Diffused, consistent source [34] [33] | Reduce shadows and highlights | Ring lights, softboxes |
| Scale Reference | Included in frame | Pixel-to-metric conversion | Precision rulers, scale bars |
| Background | High contrast, matte finish [33] | Clear specimen separation | Neutral gray/blue backdrop |
| Stabilization | Tripod mounting [33] | Eliminate motion blur | Heavy-duty tripod, remote trigger |
Acquisition Best Practices
Proper image acquisition requires attention to both technical specifications and practical implementation. For two-dimensional morphometrics, specimens should be positioned in a consistent orientation plane parallel to the camera sensor. Research on wing geometric morphometrics for insect identification demonstrates the importance of cleaned wings photographed under a digital microscope with consistent orientation and scale [3].
Lighting conditions significantly impact feature detection. Consistent, diffused lighting minimizes shadows and specular highlights that can obscure morphological features. Studies recommend soft, consistent lighting achievable with artificial light or cloudy skies to reduce shadows and ensure even illumination [34]. This is particularly important for capturing subtle morphological variations in medical applications such as nutritional assessment from arm shape analysis [32].
Camera settings must balance depth of field with image noise. While automatic settings can sometimes be used, manual configuration is often necessary to maintain consistency across all images in a dataset [34]. A fixed focal length without zoom changes ensures consistent magnification, and manual focus set to infinity prevents focus breathing between captures.
Landmark Digitization Methods
Landmark Types and Placement
Landmarks are biologically homologous points that provide the geometric framework for shape analysis. The precision of landmark placement directly influences analytical outcomes, particularly for out-of-sample classification.
Table 2: Landmark Classification and Applications
| Landmark Type | Definition | Placement Criteria | Research Example |
|---|---|---|---|
| Type I (Anatomical) | Discrete juxtapositions of tissues [32] | Defined by biological structure | Bone junctions, scale insertions |
| Type II (Mathematical) | Maxima of curvature or points of contour change | Mathematical derivatives of form | Wing venation patterns [3] |
| Type III (Extremal) | Extreme points or constructed coordinates | Relative to other landmarks | Outline endpoints, tangent points |
| Semilandmarks | Curves and surfaces between landmarks [32] | Sliding along predetermined paths | Complex contours, surface grids |
Research on Chrysodeixis moth identification utilized seven venation landmarks annotated from digital wing images to distinguish invasive from native species [3]. This approach demonstrates how a limited number of carefully chosen landmarks can effectively capture shape variation for classification purposes.
Template Registration for Out-of-Sample Data
The registration of out-of-sample individuals presents a particular challenge in geometric morphometrics. Unlike the study sample that undergoes Generalized Procrustes Analysis (GPA), new individuals require template registration to be properly positioned within the established shape space [32]. This process involves:
- Template Selection: Choosing an appropriate reference configuration from the training sample
- Procrustes Registration: Aligning the new specimen to the template through rotation, translation, and scaling
- Coordinate Extraction: Deriving the Procrustes coordinates relative to the established reference frame
The choice of template configuration significantly impacts classification accuracy for out-of-sample individuals. Research on children's nutritional assessment from arm shape analysis indicates that understanding sample characteristics and collinearity among shape variables is crucial for optimal classification results [32].
Comparative Analysis of Methodologies
Workflow Variations by Application
Different research applications require modifications to the standard workflow to address specific challenges. The following table compares methodological adaptations across disciplines.
Table 3: Methodological Variations Across Research Applications
| Research Domain | Sample Preparation | Landmark Strategy | Out-of-Sample Challenge | Citation |
|---|---|---|---|---|
| Insect Identification | Wings cleaned and mounted flat [3] | 7 Type II wing venation landmarks | Distinguishing invasive from native species | [3] |
| Nutritional Assessment | Left arm photographs with standardized pose [32] | Semilandmarks on arm contours | Classifying new children not in training set | [32] |
| Photogrammetry | Surface preparation with matte coating [33] | Dense point clouds from image matching | 3D reconstruction from overlapping images | [33] |
| Digital Image Correlation | Speckle pattern application [35] | Subset tracking across deformation states | Measuring displacement and strain fields | [35] |
Experimental Protocols
Protocol 1: Wing Geometric Morphometrics for Species Identification
This protocol is adapted from research on Chrysodeixis moth identification [3]:
- Specimen Preparation: Clean right forewings and mount flat on microscope slides
- Image Acquisition: Capture digital images using standardized microscope magnification
- Landmark Digitization: Annotate seven Type II landmarks at wing venation junctions
- Data Export: Record two-dimensional coordinates for statistical analysis
- Statistical Analysis: Perform discriminant analysis in specialized software (e.g., MorphoJ)
This approach successfully distinguished invasive C. chalcites from native C. includens, demonstrating practical utility for survey programs where traditional identification methods (genitalia dissection, DNA analysis) are time-consuming and require specialized expertise [3].
Protocol 2: Arm Shape Analysis for Nutritional Status Classification
This protocol derives from research on nutritional assessment in children [32]:
- Ethical Compliance: Obtain informed consent and ethical approval
- Standardized Photography: Capture left arm images with consistent distance and orientation
- Landmark Placement: Identify anatomical landmarks and curves for semilandmark placement
- Template Registration: Align out-of-sample individuals to established reference template
- Classifier Application: Apply discriminant functions to registered coordinates
This methodology highlights the challenge of applying classification rules to new individuals not included in the original study sample, requiring careful template selection and registration [32].
The Scientist's Toolkit
Research Reagent Solutions
Table 4: Essential Materials for Geometric Morphometrics Research
| Material/Reagent | Function | Application Specifics |
|---|---|---|
| Matte Spray Coating | Reduces surface reflectivity [33] | Creates scannable surface for photogrammetry |
| Scale References | Converts pixels to metric units | Essential for all comparative morphometrics |
| Standardized Backgrounds | Ensures consistent contrast [33] | Neutral chroma-key backdrops recommended |
| Specimen Mounting Systems | Maintains positional stability | Custom jigs for repeatable orientation |
| Landmark Digitization Software | Captures coordinate data | Tools like tpsDig2, MorphoJ [3] |
| Statistical Analysis Packages | Analyzes shape variation | R, MorphoJ, PATN, IMP suite |
Data Processing Pathway
The transformation from raw images to analyzed shape data involves multiple computational stages, particularly complex when handling out-of-sample specimens, as illustrated below.
This workflow provides a standardized yet flexible framework for geometric morphometrics research, with particular emphasis on addressing the critical challenge of out-of-sample classification. The protocols and methodologies detailed here highlight how careful attention to image acquisition, landmark digitization, and template registration enables reliable shape analysis across diverse research domains.
The comparative analysis demonstrates that while core principles remain consistent, methodological adaptations tailored to specific research questions and sample types significantly enhance analytical outcomes. As geometric morphometrics continues to evolve, particularly with increasing applications in field settings and digital health technologies, robust workflows for processing out-of-sample data will remain essential for translating morphological analyses into practical tools for identification, diagnosis, and classification.
Selecting Optimal Template Configurations for Out-of-Sample Registration
In geometric morphometrics (GM), classification rules are typically built from aligned coordinates of a study sample, most commonly using Generalized Procrustes Analysis (GPA) [2]. However, a significant methodological challenge emerges when attempting to classify new individuals that were not part of the original study sample—the "out-of-sample" problem [2]. In standard GM workflows, a series of sample-dependent processing steps, including alignment through Procrustes analysis and allometric regression, must be conducted before applying classification rules [2]. This creates a fundamental obstacle for real-world applications where classifiers developed on reference samples need to be deployed on new individuals without repeating the entire alignment process.
The significance of this challenge is particularly acute in applied contexts such as nutritional assessment of children from body shape images, where tools like the SAM Photo Diagnosis App Program aim to develop offline smartphone applications for nutritional screening [2]. Similar challenges exist across biological and biomedical fields, including nasal cavity analysis for drug delivery optimization [8] and taxonomic classification in evolutionary biology [36] [37]. This comparative guide evaluates current methodologies for selecting optimal template configurations to address this out-of-sample registration challenge, providing researchers with evidence-based recommendations for methodological selection.
Comparative Analysis of Template Selection Strategies
Table 1: Performance Comparison of Template Selection Methods
| Method Category | Specific Approach | Reported Performance | Key Advantages | Key Limitations |
|---|---|---|---|---|
| Single-Template | ALPACA (Automated Landmarking through Point cloud Alignment and Correspondence) | Higher error rates with morphological variability [36] | Computational efficiency; Simplified workflow | Bias from template-target dissimilarity; Poor performance with variable samples |
| Multiple-Template | MALPACA (Multiple ALPACA) | Significantly outperforms single-template for both single and multi-population samples [36] | Accommodates large morphological variation; Reduces single-template bias | Increased computational demand; Template selection critical |
| K-means Template Selection | K-means clustering on GPA-aligned point clouds | Avoids worst-performing template sets compared to random selection [36] | Unbiased with no prior knowledge; Automated cluster-based representation | Requires specifying cluster number; May miss rare morphologies |
| Deterministic Atlas Analysis | Iterative atlas generation minimizing total deformation energy | Strong correlation with manual landmarking (R² = 0.957 with optimal template) [37] | No fixed template required; Dynamically adapts to sample | Sample-dependent results; Parameter sensitivity (kernel width) |
| Prior Information-Based | Selection based on pilot study or existing data | Highest accuracy when prior morphological knowledge available [36] | Leverages existing biological knowledge; Targeted representation | Requires preliminary data collection; Potential observer bias |
Table 2: Quantitative Performance Metrics Across Methodologies
| Study Context | Method | Sample Size | Performance Metric | Result |
|---|---|---|---|---|
| Mouse & Ape Skulls [36] | Single-template ALPACA | 61 mice, 52 apes | Root Mean Square Error (RMSE) | Higher error rates, especially for morphologically variable specimens |
| Mouse & Ape Skulls [36] | MALPACA (7 templates) | 61 mice, 52 apes | RMSE reduction | Significant improvement over single-template |
| Mammalian Crania [37] | Deterministic Atlas Analysis | 322 mammals | Correlation with manual landmarking | R² = 0.957 with optimal initial template |
| Mammalian Crania [37] | Multiple initial templates | 322 mammals | Result correlation | R² = 0.801-0.957 between different templates |
| Nasal Cavity Analysis [8] | Semi-landmarks with GPA | 151 nasal cavities | Cluster identification | 3 distinct morphological clusters identified |
Experimental Protocols and Methodological Details
MALPACA (Multiple Template Approach)
The MALPACA pipeline operates through a structured two-step process. First, templates are identified to landmark the remaining samples. When no prior information about variation patterns exists, investigators can employ K-means clustering on point clouds of surface models to approximate overall morphological variations unbiasedly [36]. The methodological sequence involves: (1) performing Generalized Procrustes Analysis on point clouds, (2) applying PCA decomposition of Procrustes-aligned coordinates, (3) implementing K-means clustering on all PC scores, and (4) detecting samples closest to identified cluster centroids [36].
The second step executes the multi-template estimation pipeline by running ALPACA independently for each unique template. For each landmark coordinate, the median value from all corresponding estimates across templates is calculated as the final output [36]. This approach enables multiple templates to contribute to landmarking each target specimen, effectively minimizing bias introduced by single-template dependency. Post-hoc quality control can be implemented by importing individual template estimates into analytical software like R to assess convergence, with optional removal of outlier subsets to refine results [36].
Deterministic Atlas Analysis (DAA)
DAA employs a fundamentally different approach based on large deformation diffeomorphic metric mapping (LDDMM). Rather than relying on fixed templates, DAA iteratively estimates an optimal atlas shape by minimizing the total deformation energy required to map it onto all specimens [37]. The process begins with atlas generation through selecting an initial template mesh, which undergoes geodesic registration to represent the dataset [37].
Control points are generated based on a kernel width parameter, with smaller values yielding finer-scale deformations. These points are initially evenly distributed within the ambient space surrounding the atlas but adjust to fit areas with greater variability [37]. For each control point, a momentum vector ("momenta") is calculated for each specimen, representing the optimal deformation trajectory for atlas-specimen alignment. These momenta work within a Hamiltonian framework derived from the velocity field of ambient space and provide the basis for comparing shape variation through techniques like kernel principal component analysis [37].
Template Selection Protocol for Out-of-Sample Registration
For the specific challenge of out-of-sample registration, recent research has proposed methodologies to obtain shape coordinates for new individuals and analyzed the effect of different template configurations on registration accuracy [2]. The protocol involves using different template configurations from the study sample as targets for registration of out-of-sample raw coordinates. Understanding sample characteristics and collinearity among shape variables proves crucial for optimal classification results [2].
Diagram 1: Template selection workflow for out-of-sample registration, showing multiple pathways based on available prior knowledge and sample characteristics.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Essential Research Materials for Out-of-Sample Registration Studies
| Tool/Category | Specific Examples | Function/Application | Implementation Considerations |
|---|---|---|---|
| Software Platforms | 3D Slicer with SlicerMorph extension [36], R with geomorph package [8] [38], Viewbox 4.0 [8] | Automated landmarking, statistical shape analysis, and visualization | SlicerMorph includes MALPACA implementation; geomorph provides comprehensive GM statistics |
| Imaging Modalities | Computed Tomography (CT) scans [8] [37], structured-light scanning (DAVID SLS-2) [39], high-resolution photography [2] | 3D model generation for morphological analysis | Mixed modalities require standardization (e.g., Poisson surface reconstruction) [37] |
| Landmarking Tools | TPS Dig2 [38], ALPACA [36], manual landmarking protocols | Landmark digitization and correspondence establishment | Choice depends on resolution needs, sample size, and morphological variability |
| Template Selection Algorithms | K-means clustering, Hierarchical Clustering on Principal Components (HCPC) [8] | Objective template selection minimizing morphological bias | K-means effective without prior knowledge; HCPC useful for known group structures |
| Statistical Frameworks | Generalized Procrustes Analysis (GPA), Principal Component Analysis (PCA), MANOVA [8] [38] | Shape alignment, dimensionality reduction, and group comparison | PCA limitations noted for classification; consider machine learning alternatives [1] |
Diagram 2: Decision framework for selecting out-of-sample registration methods based on morphological variability and resource constraints.
The comparative analysis reveals that template selection strategy significantly impacts out-of-sample registration accuracy in geometric morphometrics. Multiple-template approaches consistently outperform single-template methods, particularly for morphologically variable samples [36]. The MALPACA framework with K-means template selection provides a robust solution when prior morphological knowledge is limited, while Deterministic Atlas Analysis offers powerful alternative for highly disparate taxa [37].
For research applications requiring out-of-sample classification, such as nutritional assessment [2] or nasal drug delivery optimization [8], investigators should prioritize multi-template approaches with careful attention to template selection that adequately represents population variation. Future methodological development should address computational efficiency of multi-template methods and standardized protocols for template selection across diverse biological applications.
Implementing Generalized Procrustes Analysis (GPA) on New Individuals
Geometric morphometrics (GM) is an essential technique for quantifying biological shape, with applications ranging from evolutionary biology to nutritional assessment. The standard analytical workflow involves two key steps: Generalized Procrustes Analysis (GPA) to remove non-shape variations (position, orientation, and scale), followed by Principal Component Analysis (PCA) to visualize and analyze shape variation in a reduced-dimensional space [1]. While this approach works effectively for analyzing complete datasets, a significant methodological challenge emerges when researchers need to classify new individuals that were not part of the original study sample—a scenario known as the "out-of-sample" problem [32].
In traditional morphometric analyses using linear measurements, classification functions derived from a training sample can be directly applied to new individuals. However, in geometric morphometrics, classifiers are constructed from transformed coordinates (Procrustes coordinates) that utilize information from the entire sample during the superimposition process [32]. This creates a fundamental problem: the Procrustes coordinates for a new specimen cannot be obtained without performing a new global alignment that includes this specimen, potentially altering the existing reference space and compromising the original classification model [32]. This review systematically compares current methodologies for addressing this challenge, evaluating their experimental performance and providing evidence-based protocols for researchers.
Methodological Comparison: Strategies for Out-of-Sample GPA
Template Registration Approach
Overview and Experimental Protocol The template registration method proposes obtaining shape coordinates for new individuals by registering their raw landmark coordinates to a template configuration derived from the reference sample [32]. This approach circumvents the need for a complete re-analysis of the training dataset. The experimental protocol involves:
- Template Selection: Choose one or more representative configurations from the reference sample to serve as registration targets. The study on children's arm shapes for nutritional assessment evaluated different template choices, including the sample consensus (mean shape) and individual specimens [32].
- Procrustes Superimposition: Perform a partial Procrustes analysis that rotates the new specimen's landmarks to the template configuration without updating the template itself. This is typically implemented using the
rottofunction in R'sshapespackage or similar software tools [32]. - Classification: Project the newly registered coordinates into the existing tangent space and apply the pre-trained classifier (e.g., Linear Discriminant Analysis) [32].
Performance and Limitations This method's effectiveness is influenced by template selection. Research on arm shape classification for nutritional status found that using a template most similar to the test specimen generally yielded optimal results [32]. The main advantage is computational efficiency, as it avoids re-computing the entire GPA. However, potential limitations include template choice sensitivity and the fact that the registered coordinates are approximations of what would have been obtained in a full GPA [32].
Full GPA Recalculation Approach
Overview and Experimental Protocol This conservative approach involves recalculating the Generalized Procrustes Analysis each time a new specimen is added to the dataset:
- Data Pooling: Combine the new specimen's raw landmark data with the original reference sample.
- GPA Recalculation: Perform a complete GPA on the pooled dataset using standard algorithms, such as the
gpagenfunction in the R packagegeomorph[40]. - Model Reconstruction: Rebuild the classification model using the new Procrustes coordinates.
Performance and Limitations While methodologically straightforward, this approach is computationally intensive for frequent classification tasks and alters the original reference space with each new specimen addition [32]. More critically, it necessitates re-computation of the classifier model for every new specimen, making it impractical for real-time applications such as the SAM Photo Diagnosis App designed for field use [32].
Machine Learning Alternatives
Overview and Experimental Protocol Given the limitations of GPA with PCA for classification, some researchers have explored supervised machine learning classifiers that operate directly on Procrustes distances or utilize alternative representations:
- Feature Extraction: Calculate Procrustes distances between all specimens or use other shape representations as features [1].
- Classifier Training: Implement supervised learning algorithms such as support vector machines, random forests, or neural networks on the reference sample [1].
- Model Application: Directly apply the trained model to new specimens using their shape features.
Performance and Limitations The MORPHIX Python package demonstrates that supervised machine learning classifiers can achieve higher accuracy for classification and new taxon detection compared to traditional PCA-based approaches [1]. These methods can potentially bypass the out-of-sample alignment problem entirely. However, they require careful model validation and may lack the visual interpretability of traditional morphometric methods [1].
Table 1: Comparison of Methods for Implementing GPA on New Individuals
| Method | Key Principle | Experimental Workflow | Advantages | Limitations |
|---|---|---|---|---|
| Template Registration [32] | Registers new individual to a fixed template from reference sample | 1. Template selection2. Partial Procrustes3. Classification | Computationally efficient; Practical for real-time applications | Approximation error; Sensitive to template choice |
| Full GPA Recalculation [40] | Recalculates GPA including the new specimen in the dataset | 1. Data pooling2. Complete GPA3. Model reconstruction | Methodologically straightforward; Theoretically pure | Computationally intensive; Alters original reference space |
| Machine Learning Alternatives [1] | Uses supervised classifiers on shape features/distances | 1. Feature extraction2. Classifier training3. Model application | High classification accuracy; Bypasses alignment problem | Requires extensive validation; Less visual interpretability |
Quantitative Performance Comparison
Classification Accuracy in Nutritional Assessment
Research on nutritional assessment from arm shapes provides comparative data on template registration performance. In studies classifying Severe Acute Malnutrition (SAM) versus Optimal Nutritional Condition (ONC) in Senegalese children, the template method achieved classification accuracies comparable to the standard leave-one-out cross-validation approach when tested on out-of-sample data [32]. The choice of template significantly influenced results, with templates most similar to the test specimen yielding the highest accuracy [32].
Impact of Measurement Error on Classification
A comprehensive study on Microtus vole molars quantified how measurement error from different sources affects classification reliability. The research examined error from imaging devices, specimen presentation, and inter-observer variation, with implications for out-of-sample classification:
Table 2: Impact of Measurement Error Sources on Classification Accuracy in Geometric Morphometrics [41]
| Error Source | Impact on Landmark Precision | Impact on Species Classification | Recommended Mitigation Strategy |
|---|---|---|---|
| Imaging Device | Moderate variation between devices | Significant differences in predicted group memberships | Standardize imaging equipment across studies |
| Specimen Presentation | High discrepancies, especially in 2D | Greatest impact on classification results | Standardize specimen orientations in 2D analyses |
| Inter-observer Variation | Highest landmark precision discrepancies | Substantial impact on classification consistency | Standardize landmark digitizers across studies |
| Intra-observer Variation | Lower than inter-observer effects | Moderate impact on classification stability | Training and periodic re-assessment |
This study demonstrated that no two landmark dataset replicates exhibited identical predicted group memberships for recent or fossil specimens, highlighting the critical importance of standardizing data acquisition protocols, particularly when applying models to new individuals [41].
Machine Learning vs. Traditional Approaches
Comparative analyses using benchmark data of papionin crania found that PCA-based results—commonly used after GPA—are "artefacts of the input data" and are "neither reliable, robust, nor reproducible" [1]. In contrast, supervised machine learning classifiers implemented in the MORPHIX package showed significantly higher accuracy for both classification and detecting new taxa [1]. This raises important concerns about approximately 18,000-32,900 existing studies based primarily on PCA outcomes for biological interpretations [1].
Essential Research Toolkit
Table 3: Essential Software Tools and Resources for Geometric Morphometric Analysis
| Tool Name | Function/Purpose | Implementation | Relevance to Out-of-Sample Problem |
|---|---|---|---|
| geomorph::gpagen() [40] | Generalized Procrustes Analysis | R package | Core GPA function for reference sample creation |
| MORPHIX [1] | Supervised machine learning for morphometrics | Python package | Alternative classification avoiding PCA limitations |
| TpsDig2 [41] | Landmark digitization | Standalone software | Standardized data acquisition to reduce error |
| shapes::rotto() [32] | Partial Procrustes to target | R package | Implements template registration for new individuals |
| SAM Photo Diagnosis App [32] | Field nutritional assessment | Mobile application | Real-world application requiring out-of-sample classification |
Experimental Workflow Visualization
Discussion and Research Recommendations
The implementation of GPA on new individuals remains a methodological challenge with significant implications for real-world applications. Based on current evidence:
- For real-time field applications (e.g., nutritional assessment apps), the template registration method offers the most practical solution, despite being an approximation [32].
- For research requiring maximum methodological purity, full GPA recalculation provides theoretical correctness at the cost of computational efficiency [40].
- For classification accuracy, machine learning alternatives increasingly outperform traditional PCA-based approaches following GPA [1].
- Regardless of method, standardization of data acquisition protocols is essential to minimize error propagation when classifying new individuals [41].
Future methodological developments should focus on improving template selection algorithms, developing more robust machine learning approaches, and creating standardized protocols for out-of-sample classification in geometric morphometrics.
In the field of geometric morphometrics, the accurate classification of new, out-of-sample individuals is a fundamental challenge. Classifiers are typically built from aligned coordinates, such as those obtained through Generalized Procrustes Analysis (GPA). However, a significant problem arises when attempting to apply these classification rules to new individuals in real-world scenarios, as the process for evaluating out-of-sample data remains poorly understood [2]. The core issue is that classifiers in geometric morphometrics are constructed not from raw coordinates but from transformations that utilize the entire sample's information. It is not straightforward to apply this registration to a new individual without conducting a new global alignment [2].
This guide objectively compares the performance of various dimensionality reduction strategies, primarily focusing on Principal Component Analysis (PCA) coupled with different cross-validation protocols. The central thesis is that the choice of dimensionality reduction approach and its validation method significantly impacts the reliability of classifying out-of-sample data in geometric morphometrics. We provide experimental data and detailed methodologies to guide researchers, scientists, and drug development professionals in selecting optimal strategies for their specific applications.
Core Concepts in Dimensionality Reduction and Validation
The Role of Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is a versatile multivariate tool with applications in data understanding, anomaly detection, missing data estimation, and compression. A PCA model follows the expression:
X = TA · PA' + E_A
where X is the data matrix, TA is the score matrix containing the projection of objects onto the A principal components subspace, PA is the loading matrix, and E_A is the matrix of residuals [42].
In geometric morphometrics, PCA is often used as a preprocessing step for dimension reduction prior to other costly computations. The objective is to maximize the amount of useful information captured by a reduced number of PCs, leaving any noise in the residuals [42]. The number of principal components (PCs) is a critical parameter that requires careful selection based on the intended application.
Cross-Validation Frameworks
Cross-validation (CV) is a fundamental technique for assessing how well a statistical model generalizes to unseen data. The table below compares common CV types used in conjunction with dimensionality reduction.
Table 1: Comparison of Common Cross-Validation Techniques
| Validation Method | Key Principle | Advantages | Disadvantages | Best Use Cases |
|---|---|---|---|---|
| K-Fold Cross-Validation [43] | Splits data into k folds; model is trained on k-1 folds and tested on the remaining fold. Process repeats k times. | Lower bias than a single train-test split; more reliable performance estimate; efficient data use. | Computationally expensive for large k or large datasets; results can vary based on random splits. | Small to medium datasets where accurate performance estimation is critical. |
| Leave-One-Out Cross-Validation (LOOCV) [43] | A special case of k-fold where k equals the number of samples. Each sample is used once as a test set. | Very low bias; uses almost all data for training. | High variance, especially with outliers; computationally prohibitive for large datasets. | Very small datasets where maximizing training data is essential. |
| Procrustes Cross-Validation (PCV) [44] | An alternative for "designed-like" short datasets. Creates a pseudo-validation set without removing samples. | Suitable for datasets where every sample is critical; prevents model collapse from sample removal. | Less conventional; requires specialized implementation. | Short, information-rich datasets common in qualitative analysis (e.g., authentication). |
Comparative Performance of Dimensionality Reduction Strategies
The choice of dimensionality reduction strategy, particularly how the number of PCs is selected, has a demonstrable impact on classification outcomes in geometric morphometrics.
Quantitative Comparison of Approaches
Experimental studies comparing dimensionality reduction approaches reveal significant performance differences. One study on feather shape classification found that a variable PC selection method—which uses cross-validation rates as the objective criterion—produced higher cross-validation assignment rates than using a fixed number of PC axes or a partial least squares method [7] [45].
Table 2: Comparison of Dimensionality Reduction Approaches in Geometric Morphometrics
| Approach | Description | Reported Performance | Key Findings |
|---|---|---|---|
| Fixed Number of PCs [7] | Retains a pre-specified number of principal components, often all with non-zero eigenvalues. | Lower cross-validation assignment rates. | Prone to overfitting; higher resubstitution rates but lower cross-validation rates due to loss of generality. |
| Partial Least Squares (PLS) [7] | Uses covariance between measurements and classification codes to generate SVD axes. | Lower cross-validation assignment rates compared to the variable method. | While designed for classification, it was outperformed by a PCA-based approach optimized for cross-validation. |
| Variable Number of PCs [7] [45] | Chooses the number of PC axes that maximizes the cross-validation rate of correct assignments. | Highest cross-validation assignment rates. | Optimizes the end goal of classification; reduces overfitting by finding the balance between bias and variance. |
In credit risk assessment, another field reliant on classification, combining PCA with cross-validation has also proven effective. One study showed that a dataset with 20 original features could be expressed by 13 PCs (capturing 80% of the variance) and achieve similar or higher success than the original dataset when classified with models like Random Forest [46].
The Critical Importance of Correct PRESS Calculation in PCA
A common mistake is to compute the Predicted Sum of Squares (PRESS) for PCA in a manner analogous to regression. The naive approach involves leaving out a sample, performing PCA on the training set, and then calculating the reconstruction error of the left-out sample. This method is theoretically flawed because it uses the left-out sample itself in the prediction step, which can lead to overfitting and an underestimation of the optimal number of components [47].
A correct approach involves a nested validation: leave out one data point, compute PCA on the training set, and then, for the left-out point, iteratively leave out one of its dimensions, using the remaining dimensions to predict the missing one via the PCA model. The total PRESS is then the sum of squared errors across all data points and all dimensions [47]. This method ensures a fair assessment of the model's predictive power.
Experimental Protocols and Workflows
Workflow for Validated Dimensionality Reduction
The following diagram illustrates a robust workflow for applying PCA and cross-validation in a geometric morphometrics classification context, integrating best practices from the literature.
Protocol for Variable PC Axis Selection
This protocol details the method found to optimize cross-validation assignment rates [7] [45].
- Perform Initial PCA: Conduct PCA on the entire dataset of aligned shape coordinates after GPA.
- Iterate Over Potential PC Numbers: For a candidate number of PC axes (e.g., from 1 to the number of samples minus one), perform the following:
- Cross-Validation Loop: Implement a leave-one-out or k-fold cross-validation.
- For each training set, build a classifier (e.g., Linear Discriminant Analysis) using the candidate number of PC scores.
- For the left-out test sample, project it onto the PC space defined by the training set and assign it to a group using the classifier.
- Calculate Correct Assignment Rate: Record whether the classification was correct.
- Cross-Validation Loop: Implement a leave-one-out or k-fold cross-validation.
- Aggregate Results: After iterating over all test samples, calculate the overall cross-validation correct assignment rate for that candidate number of PCs.
- Determine the Optimum: Repeat steps 2-3 for a range of candidate numbers. The optimal number of PCs is the one that maximizes the cross-validation assignment rate.
- Build Final Model: Using the optimal number of PCs determined, build a final classification model using the entire dataset.
Protocol for Out-of-Sample Alignment and Classification
This protocol addresses the challenge of classifying new individuals not included in the training sample [2].
- Define a Template: Select a single template configuration from the training sample. This could be a consensus (mean) configuration or a representative individual.
- Register New Individual: For a new individual with raw landmark coordinates, perform Procrustes registration (or an alternative alignment method) to align the new data to the pre-selected template, not the entire training set. This step requires the new individual's coordinates to be superimposed onto the template, adjusting for scale, rotation, and translation.
- Project into Existing Model: Project the newly aligned coordinates into the PCA space defined by the original training set, using the pre-calculated loadings (P_A).
- Apply Classifier: Use the resulting PC scores and the pre-trained classifier (e.g., LDA, Random Forest) to predict the class of the new individual.
The Scientist's Toolkit: Essential Research Reagents and Materials
The following table details key solutions and materials essential for conducting research in geometric morphometric classification with dimensionality reduction.
Table 3: Essential Research Reagents and Computational Tools
| Item / Solution | Function / Application | Example / Note |
|---|---|---|
| 3D Scanner / Digitizer | Captures high-resolution 2D images or 3D surface data of specimens. | Examples include the FaceGo pro 3D scanner [48]; critical for data acquisition. |
| Geometric Morphometrics Software | Performs landmark digitization, Generalized Procrustes Analysis (GPA), and visualization. | Tools like MorphoJ, GEOM; fundamental for core shape analysis. |
| Statistical Computing Environment | Provides a flexible platform for implementing custom PCA, cross-validation, and classification algorithms. | R or Python (with scikit-learn [43]); essential for the variable PC method and custom validation. |
| Procrustes Cross-Validation (PCV) Toolbox | Validates models built on short, "designed-like" datasets where standard CV fails. | Available in R and Matlab [44]; specific solution for small sample sizes. |
| MeshMonk Toolbox | Enables spatially dense registration of 3D surfaces for high-dimensional landmarking. | An open-source toolbox for MATLAB [48]; used for advanced 3D shape analysis. |
The comparative analysis presented in this guide demonstrates that there is no one-size-fits-all approach to dimensionality reduction for geometric morphometric classification. The performance of a strategy is highly dependent on the context and the end goal.
Key findings indicate that a variable number of PC axes, selected specifically to maximize cross-validation assignment rates, outperforms fixed-PC and PLS-based approaches in classification tasks [7] [45]. Furthermore, the choice of cross-validation method is critical; standard k-fold or LOOCV are generally effective, but for short, designed datasets, Procrustes Cross-Validation offers a robust alternative [44]. Finally, the proper implementation of these techniques, including the correct calculation of PRESS for PCA and a rigorous protocol for out-of-sample alignment, is fundamental to developing classifiers that generalize well to new data [47] [2].
Researchers must therefore carefully consider their application's objective—whether it is classification, compression, or process monitoring—and select a dimensionality reduction and validation strategy that is optimally aligned with that objective. The experimental protocols and tools provided here serve as a foundation for conducting such rigorous and validated analysis.
This case study examines the implementation of the SAM Photo Diagnosis App, a geometric morphometrics (GM)-based tool for screening Severe Acute Malnutrition (SAM). We objectively compare its performance against traditional anthropometric methods—Mid-Upper Arm Circumference (MUAC) and Weight-for-Height Z-score (WHZ)—and situate its development within a research framework focused on validating GM classification for out-of-sample data. The analysis synthesizes performance data from field tests, details the experimental protocols for GM assessment, and visualizes the core methodology. For researchers and drug development professionals, this study highlights both the transformative potential and the technical challenges of integrating GM into large-scale public health interventions.
Performance Comparison: SAM Photo App vs. Traditional Methods
The following tables summarize the key performance characteristics and operational parameters of the three main SAM diagnostic approaches.
Table 1: Diagnostic Performance and Operational Characteristics
| Feature | SAM Photo App | Mid-Upper Arm Circumference (MUAC) | Weight-for-Height Z-score (WHZ) |
|---|---|---|---|
| Underlying Principle | Geometric morphometric analysis of body shape (arm) [2] | Single-dimensional measurement of arm circumference [49] | Calculation based on weight and height/length measurements [49] |
| Primary Output | Nutritional status classification (e.g., SAM, ONC) [2] | Absolute measurement (mm) [50] | Z-score relative to WHO growth standards [50] |
| Reported Efficacy | ~90% effective in early screenings [51] [52] | Identifies a different subset of SAM children compared to WHZ [49] | Identifies a different subset of SAM children compared to MUAC [49] |
| Key Advantage | Portability, speed, minimal training required, digital record [51] [52] | Simplicity, low cost, rapid community screening [53] | International gold standard, part of WHO guidelines [50] |
| Key Limitation | In testing phases; dependency on image quality and algorithm [2] [51] | Does not identify all children at risk of mortality; discrepancy with WHZ [49] | Requires heavy, cumbersome equipment; prone to measurement error; stressful for children [51] [52] |
Table 2: Comparative Analysis of Diagnostic Outcomes and Mortality Risk
| Aspect | Findings | Data Source / Context |
|---|---|---|
| Diagnostic Agreement | MUAC and WHZ show a "fair degree of agreement" but identify different children. One study found 73.2% of children were identified as SAM by MUAC (<115mm) vs. 70% by WHZ (<-3 SD) [53]. | Hospital-based study, Pakistan [53] |
| Mortality Risk (Community) | Children with only WHZ <-3 have a significantly elevated mortality hazard ratio (HR=11.6). Children with only MUAC <115mm and those with both deficits also show high mortality risk [49]. | Pooled multi-country community cohort analysis [49] |
| Developmental Impact | SAM significantly delays development, with younger children more affected. For 1-year-olds, gross motor skills are delayed by 300%, fine motor by 200%, and language by 71.4% [54]. | Case-control study, Ethiopia [54] |
Experimental Protocols for GM-Based Nutritional Assessment
The development and validation of the SAM Photo App rely on rigorous experimental protocols derived from geometric morphometrics. The following workflow details the key steps for both creating the classification model and applying it to new subjects.
Figure 1: GM Workflow for Training and Out-of-Sample Classification.
Detailed Methodological Breakdown
Sample Collection and Preparation: The protocol begins with the assembly of a reference sample. For the SAM Photo App, this involved 410 Senegalese children aged 6-59 months, with equal proportions of those with Severe Acute Malnutrition (SAM) and an Optimal Nutritional Condition (ONC) group, balanced for age and sex [2]. Selection criteria included standard anthropometric definitions: for ONC, MUAC between 135-155 mm or WHZ between -1 and +1 SD; for SAM, MUAC < 115 mm or WHZ < -3 SD, excluding children with physical malformations or complicating medical conditions [2].
Image Acquisition and Landmark Digitization: Photographs of the children's left arms are taken under standardized conditions. The core GM process involves digitizing landmarks (anatomically defined points) and semilandmarks (points along curves) on these images to quantitatively capture the arm's shape [2]. This step converts visual information into numerical data (Cartesian coordinates) amenable to statistical analysis.
Shape Alignment and Classifier Construction: The raw coordinate data are subjected to a Generalized Procrustes Analysis (GPA), which superimposes the landmark configurations by scaling, rotating, and translating them to remove non-shape variation [2] [55]. The resulting Procrustes coordinates represent pure shape variables. A classifier (e.g., Linear Discriminant Analysis) is then trained on this data to distinguish between the SAM and ONC groups based on shape [2].
Addressing the Core Challenge: Out-of-Sample Classification: A critical and often overlooked step in real-world GM application is classifying a new individual not included in the original training set. The standard GPA is a sample-wide process and cannot be performed on a single new image. The proposed solution is template-based registration: the raw landmarks from a new subject's photo are aligned to a single, representative template configuration selected from the training sample. This places the new subject's coordinates into the same shape space as the training data, allowing the pre-trained classifier to determine its nutritional status [2]. This process is visualized in Figure 1.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Materials and Reagents for GM-Based Nutritional Studies
| Item / Solution | Function in Protocol | Specification / Rationale |
|---|---|---|
| Standardized Digital Camera | Image acquisition of the anatomical region of interest (e.g., left arm). | Ensures consistency in resolution, lighting, and perspective, minimizing a major source of non-biological shape variation [2]. |
| Landmarking Software | Digitization of anatomical landmarks and semilandmarks on digital images. | Allows for precise capture of 2D or 3D coordinates defining shape (e.g., TPS Dig2, MorphoJ) [2] [55]. |
| Geometric Morphometrics Software Suite | Performing GPA, statistical analysis, and classifier construction. | Essential for processing coordinate data (e.g., R packages geomorph and Morpho) [2]. |
| Reference Training Sample | Serves as the basis for the classification model and the template for out-of-sample registration. | Must be carefully curated with known nutritional status (SAM/ONC) and balanced for age and sex to avoid bias [2]. |
| Anthropometric Toolkit | Validation of nutritional status against gold-standard methods. | Digital scales, length/height boards, and non-stretch MUAC tapes are required to establish the "ground truth" for the training sample [2] [53]. |
Critical Analysis and Research Context
Navigating Measurement Error and Bias in GM
The validity of GM, especially concerning out-of-sample classification, is highly susceptible to measurement error (ME). A significant, often uncontrolled source of ME is the "visiting scientist effect" – a time-related systematic bias in landmark digitization. Research demonstrates that when the same operator digitizes the same specimens at different time periods (e.g., with gaps of weeks or years), a systematic shape difference is introduced, which can be large enough to confound biological signals [55]. This is particularly critical for the SAM Photo App program, which relies on aggregating data from multiple screening campaigns over time. Mitigation strategies, such as rigorous and continuous training of digitizers and randomizing the order of specimen digitization, are essential to prevent this bias from being structured by group (e.g., digitizing all SAM children in one campaign and ONC in another) [55].
Public Health Implications and Diagnostic Paradigms
The shift towards novel diagnostic tools like the SAM Photo App occurs within a complex public health landscape. Traditional methods themselves have a well-documented diagnostic discrepancy: MUAC and WHZ identify different sub-populations of malnourished children, a critical finding reinforced by a multi-country pooled analysis [49]. This discrepancy has direct life-or-death consequences, as community-based studies show that children with only WHZ <-3 or only MUAC <115mm face significantly elevated mortality risks [49]. Therefore, any new tool must not merely match the performance of one existing method but aim to capture the combined at-risk population identified by both. The SAM Photo App's GM approach, which analyzes overall arm shape, theoretically offers a pathway to achieve this by potentially capturing the morphological features associated with both wasting (low WHZ) and muscle mass loss (low MUAC).
Mitigating Error and Enhancing Classification Accuracy
Quantifying and Managing Measurement Error from Multiple Operators
In geometric morphometric (GM) analyses, the quantification of shape and shape variation relies on the precise placement of landmarks by human operators. Measurement error, particularly that introduced by multiple operators, is a ubiquitous yet frequently unaddressed threat to the validity and replicability of research findings [56]. When multiple operators digitize the same specimens, variations in their technique, interpretation of anatomical loci, and consistency can introduce artificial variation that obscures true biological signals [57]. This challenge is especially critical when GM classification models are applied to out-of-sample data—new individuals not included in the original training set [2]. The broader thesis of validating geometric morphometric classification on out-of-sample data hinges on the ability to disentangle operator-induced error from genuine biological variation. Without proper management and quantification of these errors, even the most sophisticated statistical models may produce unreliable classifications, leading to incorrect interpretations in taxonomy, ecomorphology, and evolutionary biology [57] [18]. This guide provides a structured approach to comparing, quantifying, and mitigating measurement error from multiple operators, ensuring that analytical results are both robust and reproducible.
Understanding Measurement Error in Geometric Morphometrics
Fundamental Concepts: Accuracy, Precision, and Error Types
All measurements contain some degree of uncertainty, making error analysis fundamental to scientific research [58]. In the context of multiple operators, it is crucial to distinguish between two key concepts:
- Accuracy: The closeness of agreement between a measured value and a true or accepted value. Inaccuracy is measurement error [58].
- Precision: The degree of consistency and agreement among independent measurements of the same quantity; it reflects the reliability or reproducibility of the result, without reference to a theoretical true value [58].
Measurement errors are broadly categorized as either random or systematic:
- Random Errors: Statistical fluctuations (in either direction) in the measured data due to the precision limitations of the measurement device or operator. These can be evaluated through statistical analysis and reduced by averaging over many observations [58].
- Systematic Errors: Reproducible inaccuracies that are consistently in the same direction. These errors are difficult to detect and cannot be analyzed statistically or reduced by increasing observations. If identified, they can often be corrected via calibration [58].
Operator-Specific Error Mechanisms
In geometric morphometrics, error from multiple operators, often termed "personal error," manifests in specific ways [57] [58]:
- Interobserver Error: Variation in landmark positioning when different individuals digitize the same specimen and the same anatomical locus. This is often the most substantial source of personal error [57].
- Intraobserver Error: Variation in landmark placement by the same individual across different digitizing sessions or even across different specimens. This can be affected by factors like digitizing experience, fatigue, and the number of sessions conducted [57].
Personal errors can stem from carelessness, poor technique, or unconscious bias on the part of the experimenter, who may inadvertently force results to agree with expected outcomes. While gross personal errors (blunders) should be avoided and corrected, the more subtle and pervasive forms of inter- and intraobserver variation require formal quantification [58].
Quantifying Operator-Induced Error: Experimental Data and Protocols
Quantifying the impact of multiple operators requires controlled experiments and specific statistical measures. The following data and protocols provide a framework for this essential process.
A landmark study evaluating error sources in 2D landmark configurations of vole teeth provides critical quantitative insights. Researchers acquired data from the same specimens multiple times to isolate error from four distinct sources [57].
Table 1: Contribution of Different Error Sources to Total Shape Variation
| Error Source | Type | Contribution to Total Variation | Key Finding |
|---|---|---|---|
| Interobserver Variation | Personal | Sometimes >30% | Greatest discrepancy in landmark precision |
| Specimen Presentation | Methodological | Substantial | Greatest discrepancy in species classification results |
| Intraobserver Variation | Personal | Significant | Impacts statistical classification |
| Imaging Device | Instrumental | Significant | Combined impact on statistical fidelity |
The study concluded that data acquisition error can be substantial, sometimes explaining more than 30% of the total variation among datasets. Furthermore, no two landmark dataset replicates yielded the same predicted group memberships for recent or fossil specimens, underscoring the profound impact of these errors on downstream analysis [57].
Experimental Protocol for Quantifying Inter- and Intraobserver Error
To systematically quantify operator error, the following experimental protocol is recommended, adapted from methodologies used in morphometric research [57]:
- Specimen and Operator Selection: Select a representative subset of specimens (e.g., 10-20% of the total dataset) covering the full morphological range. Multiple operators (e.g., 3-5) with varying levels of experience should participate.
- Repeated Digitization: Each operator performs multiple rounds of landmark digitization on the selected specimens. For intraobserver error assessment, each operator digitizes the same set of specimens at least twice, with sessions separated by days or weeks to avoid memory effects. For interobserver error, all operators digitize the same set of specimens.
- Data Acquisition Standardization: To isolate operator error, control for other variables. Use the same imaging device for all specimens. Standardize specimen presentation and orientation as rigorously as possible, especially for 2D analyses [57].
- Statistical Analysis: Perform a Procrustes ANOVA on the landmark coordinates from the repeated trials. This partitions the total shape variance into components attributable to:
- Actual specimen differences (the biological signal of interest).
- Operator differences (interobserver error).
- Digitization round differences (intraobserver error).
- Unexplained residual variance.
This protocol directly quantifies how much variance in the final dataset is caused by the operators themselves versus true biological differences.
Impact on Classification Accuracy
The ultimate test of measurement error is its impact on the analytical goals of the study. In classification analyses like Linear Discriminant Analysis (LDA), operator error has a demonstrable effect on accuracy and reliability [57] [18].
Table 2: Impact of Measurement Error on Classification Methods
| Classification Method | Reported Accuracy with Error | Context / Condition |
|---|---|---|
| Geometric Morphometrics (2D) | < 40% | Low discriminant power in bidimensional analysis of tooth marks [18] |
| Computer Vision (Deep Learning) | ~81% | Classification of experimental tooth pits [18] |
| Computer Vision (Few-Shot Learning) | ~79.5% | Classification of experimental tooth pits [18] |
One study found that different error sources uniquely impacted classification: while interobserver variation caused the largest discrepancies in landmark precision, variation in specimen presentation had the greatest negative effect on final species classification results [57]. This highlights that error management is critical for achieving the primary objective of many GM studies—accurate group prediction.
Managing and Mitigating Operator Error
A proactive approach to managing operator error involves strategies implemented before, during, and after data collection.
Standardization and Training Protocols
The most effective way to manage error is to prevent it through rigorous standardization [57].
- Standardize Landmark Definitions: Create a detailed guide with precise, unambiguous definitions and high-quality visual examples for every landmark. This is the foundational step for consistency.
- Training and Calibration Sessions: Before formal data collection, conduct joint training sessions where all operators digitize the same practice specimens. Discuss discrepancies and refine techniques until a high consensus is achieved.
- Standardize Equipment and Setup: Use the same imaging equipment and software for the entire study. For 2D analyses, establish and rigorously adhere to a fixed protocol for specimen presentation and orientation to minimize projection artifacts [57].
Statistical Correction and Analytical Best Practices
When error cannot be fully eliminated, statistical and analytical practices can mitigate its impact.
- Quantify and Report Error: Always estimate and report the magnitude of inter- and intraobserver error in publications. This provides context for the results and allows other researchers to assess the reliability of the findings [57].
- Out-of-Sample Validation: When building classifiers, always test their performance on data that was not used in the model training stage (out-of-sample testing) [2]. This practice helps ensure that the model captures generalizable biological patterns rather than operator-specific or sample-specific noise.
- Use Error Estimates in Analysis: In some cases, measurement error models can be used to correct associations and mitigate bias, provided the error structure (e.g., classical error model) can be quantified [56].
The Research Toolkit: Essential Materials and Solutions
The following table details key resources and their functions for implementing a robust error management protocol.
Table 3: Research Reagent Solutions for Error Management
| Item / Solution | Function in Error Management |
|---|---|
| Detailed Landmark Protocol | Provides unambiguous definitions and visual guides for landmarks to standardize digitization across operators. |
| Calibration Specimen Set | A fixed set of specimens used for training and periodic calibration of all operators to maintain consistency. |
| Standardized Imaging Rig | A dedicated setup (camera, lens, lighting, specimen mount) to eliminate instrumental and presentation error. |
| Procrustes ANOVA Software | Statistical software (e.g., MorphoJ, R packages) to partition variance and quantify operator error. |
| Blinded Specimen Presentation | Software or protocol that randomizes and blinds specimen identity during digitization to reduce observer bias. |
Workflow for Managing Operator-Induced Error
The following diagram illustrates a comprehensive workflow for managing error from multiple operators, from initial study design to final validation.
Diagram: Workflow for managing operator-induced error from study design to validation.
The question is not if multiple operators introduce measurement error, but how much and what impact it will have on scientific conclusions. As shown, interobserver error can explain a substantial portion of total shape variation, directly compromising the accuracy of taxonomic classifications and other analytical outcomes [57]. The path to robust geometric morphometrics requires a shift in practice: from treating operator error as an unmentionable flaw to formally quantifying it as a standard component of methodological rigor. By implementing the structured protocols outlined in this guide—including rigorous training, standardized imaging, formal error quantification using Procrustes ANOVA, and rigorous out-of-sample validation—researchers can significantly mitigate this risk. In doing so, they strengthen the foundation of their findings and contribute to a more reproducible and reliable morphometric science.
Optimizing Landmark and Semi-Landmark Protocols to Reduce Bias
Geometric morphometrics (GM) is a cornerstone of modern biological and anthropological research, providing powerful tools for quantifying and analyzing shape variation. Its applications span from exploring evolutionary dynamics and taxonomic classifications to assessing nutritional status in public health interventions [2] [37]. The reliability of these analyses, however, is fundamentally dependent on the landmark and semi-landmark protocols used to capture morphological data. Traditional approaches, which rely on manually placed anatomical landmarks, offer biological homology but often provide only a sparse representation of form, potentially missing critical shape information from regions lacking discrete homologous points [59] [60].
The expansion of high-resolution 3D imaging technologies has created an urgent need for methods that can densely sample complex surfaces, leading to the widespread adoption of semi-landmarks [59] [60]. While these techniques enrich shape description, they introduce specific challenges, including the potential for methodological artifacts, correspondence problems, and various biases that can distort statistical outcomes and biological interpretations [59] [1]. Furthermore, the critical step of classifying new, out-of-sample individuals—a common requirement in applied settings—remains a non-standardized process within the GM workflow [2].
This guide objectively compares contemporary landmark and semi-landmark sampling strategies, evaluating their performance in reducing bias and enhancing analytical robustness, particularly within the context of out-of-sample classification. We synthesize experimental data from diverse fields—including primatology, clinical nutrition, and archaeology—to provide a clear framework for selecting and optimizing morphometric protocols.
Comparative Performance of Sampling Strategies
Different landmarking strategies present unique trade-offs in correspondence, coverage, repeatability, and robustness to noise. The table below summarizes the quantitative performance and characteristics of three semi-landmark approaches evaluated for analyzing great ape cranial morphology [59].
Table 1: Performance comparison of dense semi-landmark sampling strategies for 3D cranial data
| Method | Key Description | Mean Shape Estimation Error (Mean MRSE) | Sensitivity to Noise & Missing Data | Computational Demand | Best Use Cases |
|---|---|---|---|---|---|
| Patch-based | Projects points from triangular patches defined by manual landmarks onto each specimen's surface. | Comparable or better than manual landmarks alone, but with outliers. | High (results in outliers with large deviations) | Lower | Specimen-independent analysis; well-defined, patchable surfaces. |
| Patch-TPS | Transfers a single template's semi-landmarks to all specimens via Thin-Plate Spline (TPS) warp and normal projection. | Comparable or better than manual landmarks alone. | Low (robust performance) | Medium | Datasets with high variability or noise; standardized comparisons. |
| Pseudo-landmark | Automatically samples points on a template surface with enforced minimum spacing, transferred via TPS. | Comparable or better than manual landmarks alone. | Low (robust performance) | Higher (initial setup) | Capturing overall shape form without strict biological homology. |
The data indicates that while all three automated strategies significantly increase shape information density compared to using manual landmarks alone, their performance varies. The Patch-based method, while computationally efficient and applicable to individual specimens without a template, demonstrates high sensitivity to noise and missing data, leading to unreliable outliers [59]. The Patch-TPS and Pseudo-landmark methods, which both rely on a template-based TPS transformation, show superior and more robust performance in the presence of dataset variability [59]. The choice between them involves a trade-off between the geometric interpretability of patch-based semi-landmarks and the extensive, homology-free coverage of pseudo-landmarks.
Detailed Experimental Protocols
To ensure reproducibility and informed application, this section details the key methodologies from the cited comparative studies.
Protocol for Patch-based Semi-landmarking
This protocol, applied to great ape crania, generates semi-landmarks directly on each specimen without a population template [59].
- Patch Definition: An expert defines triangular regions on the specimen's surface using three pre-placed manual landmarks as vertices.
- Grid Registration: A pre-defined, uniformly sampled triangular grid is warped to fit the vertices of the target patch using a Thin-Plate Spline (TPS) deformation.
- Surface Projection: The grid points are projected onto the actual specimen surface. The projection vector is determined by averaging the surface normals at the three bounding manual landmarks. A ray is cast from each grid point, and its intersection with the surface mesh is identified.
- Merging and Finalization: After processing all patches, overlapping points along shared triangle edges are removed. The final set comprises the original manual landmarks and the newly placed semi-landmarks.
Protocol for Template-Based Semi-landmark Transfer (Patch-TPS & Pseudo-landmarks)
This general workflow is used for transferring landmarks from a template to individual specimens, common to both Patch-TPS and Pseudo-landmark methods [59] [2].
- Template Generation: A representative specimen or a synthetic mean shape is selected as the template. For Patch-TPS, semi-landmarks are placed on the template using the patch-based method. For Pseudo-landmarks, a dense set of points is automatically sampled across the template surface, filtered to ensure a minimum distance between points.
- TPS Transformation: A Thin-Plate Spline transform is calculated based on the correspondence between the manual landmarks placed on the template and those placed on the target specimen.
- Landmark Transfer: The template's semi- or pseudo-landmarks are warped to the target specimen's space using the TPS transform.
- Surface Projection: Each warped point is projected onto the target specimen's surface along the direction of the template's surface normal vectors at those points. This step ensures the points sit on the actual surface of the target specimen, refining the TPS approximation.
Protocol for Out-of-Sample Classification in Nutritional Assessment
This protocol addresses the critical challenge of classifying new individuals not included in the original training sample, as developed for a child nutritional status app [2].
Training Phase:
- A reference sample of 2D arm photographs from children of known nutritional status (e.g., Severe Acute Malnutrition vs. Optimal Nutritional Condition) is collected.
- Manual landmarks and semi-landmarks are placed on each image.
- A Generalized Procrustes Analysis (GPA) is performed on the entire training sample to align all configurations.
- A classifier (e.g., Linear Discriminant Analysis) is trained on the Procrustes-aligned coordinates from the training sample.
Out-of-Sample Processing Phase:
- A new child's arm photograph is taken.
- Manual landmarks are placed on the new image.
- Instead of performing a new GPA with the training sample, the new individual's raw landmark coordinates are registered to the shape space of the training sample. This is achieved by using one of the training samples (or its mean) as a template for TPS registration.
- The registered coordinates of the new individual are then input into the pre-trained classifier to predict nutritional status.
The choice of template for registration was found to be crucial, as different templates can influence the resulting coordinates and the final classification outcome [2].
Workflow for Method Selection and Out-of-Sample Analysis
The following diagram illustrates the decision pathway for selecting a landmarking strategy and the subsequent workflow for analyzing out-of-sample data, integrating the protocols described above.
The Scientist's Toolkit: Essential Research Reagents and Materials
Successful implementation of optimized morphometric protocols requires a suite of specialized software and analytical tools. The following table details key solutions used in the featured studies.
Table 2: Key software and analytical tools for geometric morphometrics
| Tool Name | Function/Brief Explanation | Application in Reviewed Studies |
|---|---|---|
| 3D Slicer / SlicerMorph | An open-source platform for biomedical image visualization and analysis. The SlicerMorph extension provides specific tools for 3D morphometrics. | Used for data acquisition, manual landmarking, and implementing the patch, patch-TPS, and pseudo-landmark protocols on great ape crania [59]. |
| R package 'Morpho' | An R package providing a comprehensive suite of functions for geometric morphometric analysis, including sliding semi-landmarks and Procrustes analysis. | Cited as a standard toolkit for statistical analysis of landmark data, including semi-landmark optimization [59]. |
| R package 'geomorph' | Another widely used R package for the geometric analysis of shape, supporting everything from Procrustes alignment to complex multivariate and phylogenetic analyses. | Referenced as a standard tool for the statistical analysis of shape in evolutionary biology [59]. |
| Deterministic Atlas Analysis (DAA) | A landmark-free method using Large Deformation Diffeomorphic Metric Mapping (LDDMM) to establish dense correspondence across highly disparate shapes. | Explored for macroevolutionary analyses across 322 mammalian species as an alternative to manual landmarking, showing promise for large-scale studies [37]. |
| Convolutional Neural Networks (CNNs) | A class of deep learning models capable of automatically learning relevant shape features directly from images, bypassing the need for manual landmark definition. | Outperformed traditional outline-based geometric morphometrics in classifying archaeobotanical seeds, demonstrating superior classification accuracy [61]. |
| MORPHIX | A Python package that uses supervised machine learning classifiers to process superimposed landmark data, designed to address biases in traditional PCA-based approaches. | Developed to provide more accurate classification and outlier detection than standard Principal Component Analysis (PCA), mitigating sample identification bias [1]. |
The optimization of landmark and semi-landmark protocols is paramount for reducing bias in geometric morphometrics, especially as the field moves toward the analysis of larger, more complex datasets and the application of models to out-of-sample individuals. Evidence shows that while traditional manual landmarks are irreplaceable for establishing biological homology, supplementing them with dense semi-landmarks (e.g., via Patch-TPS) or pseudo-landmarks significantly enforms shape representation without sacrificing accuracy [59]. For the critical task of out-of-sample validation, a template-based registration strategy provides a viable path to integrate new specimens into an existing model's shape space [2].
Emerging methodologies, including landmark-free approaches like DAA and deep learning models like CNNs, present a paradigm shift. These methods offer superior efficiency and, in some cases, classification performance, by circumventing the bottlenecks and potential subjectivity of manual point placement [37] [61]. However, they may come at the cost of explicit biological correspondence. The choice of an optimal protocol therefore depends on a balance between analytical goal, dataset characteristics, and the fundamental trade-off between the rich biological interpretability of homology-based landmarks and the powerful, automated shape capture of landmark-free and machine learning techniques. Future work should focus on standardizing out-of-sample pipelines and further validating these advanced methods across diverse biological contexts.
The integration of datasets from multiple sources and studies is a foundational step in advancing research, particularly in specialized fields like geometric morphometrics where the validation of classification methods on out-of-sample data is paramount. This process enables researchers to develop more robust, generalizable models and overcome the limitations of small, homogenous samples. However, pooling data introduces significant complexities, including variations in data collection protocols, taxonomic structures, and analytical frameworks across studies. Within geometric morphometrics—a methodology for quantifying and analyzing shape variation using landmarks—the challenge is particularly acute. The standard approach of Generalised Procrustes Analysis (GPA) followed by Principal Component Analysis (PCA) has been criticized for producing artefacts of the input data and performing poorly when classifying new, out-of-sample individuals [62]. This guide objectively compares the performance of traditional geometric morphometric techniques with emerging machine learning and computer vision alternatives, providing a structured framework for pooling datasets to enhance the reliability and validity of out-of-sample predictions in morphological research.
Foundational Strategies for Data Pooling
Successful data pooling requires a methodical approach to ensure that combined datasets are coherent, reliable, and fit for purpose. The following strategies provide a roadmap for this process.
Define Clear Objectives: Begin by establishing precise research goals. In the context of morphometrics, this could include creating a single source of truth for morphological reporting, automating classification pipelines, or preparing consolidated datasets for machine learning models. Clear objectives guide all subsequent decisions, from source selection to transformation rules, ensuring the pooled data supports the intended analytical outcomes [63].
Take Inventory of Data Sources: Create a comprehensive inventory of all potential data sources, including raw landmark coordinates, processed Procrustes coordinates, and associated metadata. For each source, document key characteristics such as the type of data (e.g., 2D vs. 3D landmarks, semi-landmarks), the number and type of landmarks used, update frequency, and the responsible team or individual. This inventory provides a full framework for understanding data provenance and highlights opportunities to remove duplication or fill gaps [63].
Choose a Central Data Destination: Select a centralized repository suitable for the volume and complexity of morphological data. Options include data warehouses like BigQuery or Snowflake for structured analytics and dashboard queries, or data lakes like Amazon S3 for raw, semi-structured landmark coordinates. The choice should align with reporting goals, data volume, and long-term scalability needs for housing large-scale morphometric datasets [63].
Automate Data Transfers: Implement automated pipelines for transferring data from multiple sources to the central repository. Manual uploads are prone to error and not feasible for large-scale collaborations. Automation ensures the warehouse remains updated and data is always ready for analysis, which is crucial for maintaining the integrity of pooled datasets across multiple research institutions [63].
Transform and Standardize Data: Once data is centralized, focus on making it consistent and usable. Different morphometric studies may use varied landmark schemes, anatomical definitions, or measurement protocols. Transformation involves data cleaning (fixing errors, removing duplicates), normalization (applying consistent units and formats), and taxonomy alignment (matching anatomical categories and landmark labels across systems) [63].
Implement Data Governance: Establish consistent rules and accountability for the pooled data. Assign ownership for each dataset in the repository, establish data quality review processes, control access levels and permissions, and document lineage to indicate where each dataset originates and how it should be transformed. A strong governance structure builds confidence in subsequent analyses [63].
Application in Geometric Morphometrics
The general strategies for data pooling take on specific significance when applied to geometric morphometrics, particularly in addressing the critical challenge of out-of-sample classification.
The Out-of-Sample Problem in Morphometrics
In geometric morphometrics, classification rules are typically built from aligned coordinates of a study sample, most commonly using linear discriminant analysis, neural networks, logistic regression, or support vector machines [32]. The benchmark practice is to split data into training and test sets or use leave-one-out cross-validation after joint Generalised Procrustes Analysis (GPA) of the entire dataset [32]. However, this approach presents a fundamental limitation: classifiers are constructed not from raw coordinates but from transformations that utilize the entire sample's information, such as Procrustes coordinates derived from GPA. Consequently, it remains unclear how to apply this registration to a new individual without conducting a new global alignment, creating a significant barrier for real-world applications [32].
This challenge is particularly relevant in contexts such as nutritional assessment of children from body shape images. Here, classification rules obtained on the shape space from a reference sample cannot be used on out-of-sample individuals in a straightforward way, as a series of sample-dependent processing steps (such as Procrustes analysis or allometric regression) must be conducted before the classification rule can be applied [32]. Research has shown that understanding sample characteristics and collinearity among shape variables is crucial for optimal classification results when evaluating children's nutritional status using arm shape analysis from photos [32].
Methodological Comparison for Out-of-Sample Classification
[32] proposes a methodology to evaluate out-of-sample cases from a classification model created from a training sample and analyzes the effect of using different template configurations for registration of out-of-sample raw coordinates. This approach is particularly valuable for applications like the SAM Photo Diagnosis App Program, which aims to develop an offline smartphone tool capable of updating the training sample across different nutritional screening campaigns [32].
The table below summarizes the key methodological considerations for out-of-sample classification in geometric morphometrics:
Table 1: Methodological Approaches for Out-of-Sample Classification in Geometric Morphometrics
| Methodological Aspect | Traditional Approach | Proposed Improvements |
|---|---|---|
| Data Alignment | Generalised Procrustes Analysis (GPA) using entire sample | Template-based registration for new individuals |
| Classification Framework | PCA followed by linear discriminant analysis | Supervised machine learning classifiers |
| Template Selection | Not standardized for out-of-sample data | Analysis of different template configurations from study sample |
| Validation Method | Leave-one-out cross-validation on aligned data | Separate validation on truly out-of-sample datasets |
| Application Context | Research settings with complete datasets | Real-world applications with new individuals |
Experimental Protocols for Method Validation
To validate the reliability of different approaches for out-of-sample classification, researchers can implement the following experimental protocols:
Protocol 1: Template Configuration Experiment
- Objective: Evaluate the effect of different template configurations on classification accuracy for out-of-sample individuals.
- Methodology: Select multiple template configurations from the training sample as targets for registration of out-of-sample raw coordinates. Compare classification performance across different template choices.
- Data Requirements: A reference sample with known classification, plus truly out-of-sample individuals for validation.
- Output Metrics: Classification accuracy, precision, recall, and F1-score for each template configuration.
Protocol 2: Machine Learning Benchmarking
- Objective: Compare traditional morphometric classification with modern machine learning approaches.
- Methodology: Apply both standard geometric morphometric pipelines (GPA + PCA + LDA) and supervised machine learning classifiers (e.g., Random Forest, Support Vector Machines) to the same dataset using appropriate train-test splits that mimic out-of-sample scenarios.
- Data Requirements: Dataset with sufficient samples for training and hold-out testing.
- Output Metrics: Classification accuracy, robustness to sample size, computational efficiency.
Comparative Performance of Analytical Techniques
Research has demonstrated significant differences in performance between traditional geometric morphometric methods and emerging computational approaches for classifying morphological data.
Limitations of Traditional Geometric Morphometrics
The standard geometric morphometrics approach comprises two steps: Generalised Procrustes Analysis (GPA) followed by Principal Component Analysis (PCA) [62]. PCA projects the superimposed data produced by GPA onto a set of uncorrelated variables, which are visualized on scatterplots and used to draw phenetic, evolutionary, and ontogenetic conclusions [62]. However, recent evaluations have raised serious concerns about this approach:
PCA Outcomes as Artefacts: Studies have found that PCA outcomes are largely artefacts of the input data and are neither reliable, robust, nor reproducible as field members may assume [62]. The proximity of samples in PCA plots is often interpreted as evidence of relatedness and shared evolutionary history, but these interpretations are subjective and potentially misleading [62].
Dimensional Inconsistency: Different principal component plots may yield conflicting results. In the case of Homo Nesher Ramla bones, PC1-PC2 and PC1-PC3 plots showed different relationships than PC2-PC3 plots, creating interpretation challenges [62].
Limited Discriminant Power: Current bidimensional applications of geometric morphometrics yield limited discriminant power (<40%) for classifying tooth marks to specific carnivore agencies, raising questions about its reliability for taxonomic classification [18].
Emerging Alternatives: Computer Vision and Machine Learning
In contrast to traditional geometric morphometrics, computer vision and machine learning approaches have demonstrated superior performance for classification tasks:
Enhanced Accuracy: Computer vision approaches, particularly Deep Learning using convolutional neural networks (DCNN) and Few-Shot Learning (FSL) models, have classified experimental tooth pits with 81% and 79.52% accuracy respectively, significantly outperforming geometric morphometric methods [18].
Supervised Machine Learning Classifiers: Supervised machine learning classifiers have been shown to be more accurate than PCA-based approaches both for classification and detecting new taxa [62]. The MORPHIX Python package provides tools for processing superimposed landmark data with classifier and outlier detection methods that offer better-supported results than principal component analysis [62].
3D Topographical Analysis: Future research directions emphasize utilizing complete 3D topographical information for more complex geometric morphometric and computer vision analyses, which may resolve current interpretive challenges in bidimensional approaches [18].
The table below provides a quantitative comparison of method performance based on experimental data:
Table 2: Quantitative Comparison of Classification Method Performance
| Methodological Approach | Classification Accuracy | Robustness to Out-of-Sample Data | Limitations |
|---|---|---|---|
| Traditional GMM (2D) | <40% [18] | Low | Sample-dependent processing; alignment challenges |
| Computer Vision (DCNN) | 81% [18] | High | Requires large training datasets |
| Few-Shot Learning (FSL) | 79.52% [18] | Moderate-High | Limited applications in fossil record |
| Supervised Machine Learning | Higher than PCA [62] | High | Dependent on feature engineering |
Workflow Visualization
The following diagram illustrates the comparative workflows for traditional geometric morphometrics versus machine learning approaches for out-of-sample classification:
The Scientist's Toolkit: Research Reagent Solutions
The following table details essential materials and computational tools used in geometric morphometric research, particularly for studies involving pooled datasets and out-of-sample validation:
Table 3: Essential Research Reagents and Tools for Geometric Morphometrics
| Item/Tool | Function | Application Context |
|---|---|---|
| MORPHIX Python Package | Processes superimposed landmark data with classifier and outlier detection methods | Provides supervised machine learning alternatives to PCA for improved classification accuracy [62] |
| Deep Convolutional Neural Networks (DCNN) | Classifies morphological features using computer vision | Achieves higher accuracy (81%) for agency attribution in taphonomic studies [18] |
| Few-Shot Learning (FSL) Models | Enables learning from limited examples | Classifies experimental tooth pits with 79.52% accuracy where training data is limited [18] |
| Generalized Procrustes Analysis (GPA) | Superimposes landmark coordinates by reducing shape-independent variations | Standard preprocessing step in traditional geometric morphometrics [62] |
| Template Configurations | Provides reference for registration of out-of-sample raw coordinates | Enables application of classification rules to new individuals not included in original study sample [32] |
| 3D Topographical Scanners | Captures complete three-dimensional surface information | Provides more comprehensive data for complex GMM and computer vision analyses [18] |
Pooling datasets from multiple sources and studies presents both challenges and opportunities for advancing geometric morphometric research, particularly in validating classification methods on out-of-sample data. Traditional approaches relying on Generalized Procrustes Analysis and Principal Component Analysis show significant limitations in reliability, robustness, and reproducibility, especially when applied to new individuals not included in the original study sample. Emerging methodologies, including supervised machine learning classifiers and computer vision techniques, demonstrate superior classification accuracy and better handling of out-of-sample data. The strategic integration of these approaches within a structured data pooling framework—encompassing clear objectives, comprehensive inventory, centralized storage, automated transfers, standardized transformation, and strong governance—provides a pathway toward more reliable and valid morphological classifications. As the field progresses, leveraging complete 3D topographical information and continued refinement of machine learning applications will further enhance our ability to make confident taxonomic and phylogenetic interpretations from morphological data.
In the field of geometric morphometrics (GM) and predictive modeling, overfitting remains one of the most pervasive and deceptive pitfalls, leading to models that perform exceptionally well on training data but fail to generalize to new, unseen data [64]. This problem is particularly acute in geometric morphometric classification, where the goal is often to apply models derived from a reference sample to out-of-sample individuals in real-world scenarios [2]. The challenge lies in the fact that classifiers in geometric morphometrics are typically constructed not from raw coordinates but from transformed data utilizing the entire sample's information, most commonly Procrustes coordinates derived from generalized Procrustes analysis (GPA) [2].
The fundamental issue of overfitting arises when model complexity exceeds what is justified by the available data, often as a result of inadequate validation strategies, faulty data preprocessing, and biased model selection [64]. These problems can artificially inflate apparent accuracy and compromise predictive reliability, creating a significant barrier to practical application. In geometric morphometrics specifically, the classification of new individuals that were not part of the original study sample presents unique challenges, as standard alignment-based methods do not readily address this scenario [2]. Understanding how to balance variable selection with appropriate sample sizes is therefore critical for developing robust, generalizable models that maintain predictive performance when applied to new data in real-world contexts such as nutritional assessment, evolutionary biology, and medical diagnostics.
The Theoretical Framework of Overfitting
Defining Overfitting and Its Consequences
Overfitting occurs when a model learns not only the underlying patterns in the training data but also the noise and random fluctuations, resulting in excellent performance on the training data but poor generalization to new data. This phenomenon is especially problematic in geometric morphometrics, where the high dimensionality of shape data—often represented by numerous landmarks and semilandmarks—creates substantial risk for overparameterization. In the context of classifying children's nutritional status from body shape images, for instance, the inability to properly classify out-of-sample individuals significantly limits the practical utility of the method [2].
The consequences of overfitting extend beyond merely reduced predictive accuracy. In scientific research, overfit models can lead to incorrect conclusions about the relationships between variables, potentially misdirecting entire research programs. In clinical applications, such as nutritional assessment or disease diagnosis, the stakes are even higher, as overfit models may fail to correctly identify individuals requiring intervention [2] [64]. The problem is often compounded by publication biases that favor novel findings and strong results, creating incentives for practices that inadvertently promote overfitting [64].
Mechanisms Leading to Overfitting
Overfitting typically results from a chain of avoidable missteps rather than a single error. Common contributing factors include data leakage during preprocessing, where information from the test set inadvertently influences model training; inappropriate validation strategies that do not truly assess generalizability; and model selection procedures that overoptimize for performance on limited data [64]. In geometric morphometrics, additional domain-specific challenges arise from the need to align new individuals to an existing template configuration before classification, a process that may introduce artifacts if not carefully handled [2].
Complex models with excessive parameters relative to the sample size are particularly prone to overfitting. This explains why machine learning techniques, including tree-based ensemble methods, often require substantially larger sample sizes than traditional statistical approaches to achieve comparable generalization performance [65]. The relationship between model complexity, sample size, and overfitting risk follows a fundamental trade-off: as model flexibility increases, more data is required to reliably estimate parameters without capturing spurious patterns.
Sample Size Requirements for Robust Modeling
General Sample Size Considerations
Determining appropriate sample sizes is a critical defense against overfitting, yet it remains a complex challenge with no universally applicable solutions. Sample size determination involves careful tradeoffs between statistical power, practical constraints, and the level of accuracy required for the specific application [66]. The appropriate sample size depends on multiple factors, including the variability of the data, the effect size researchers wish to detect, the desired level of statistical confidence, and the complexity of the model being developed [66] [65].
For qualitative research focused primarily on discovery and hypothesis generation, such as identifying potential usability issues in early-stage design, smaller samples may be sufficient. However, the moment research objectives shift to quantitative assessment—including estimating frequencies, comparing groups, or building predictive models—larger samples become necessary [66]. This distinction is crucial in geometric morphometrics, where research may transition from exploratory shape analysis to predictive classification.
Sample Size Guidelines for Different Modeling Approaches
Table 1: Sample Size Recommendations for Different Modeling Techniques
| Modeling Approach | Minimum Sample Guideline | Key Considerations | Context of Use |
|---|---|---|---|
| Logistic Regression | Varies by event prevalence and predictors [65] | Follow established formulas accounting for events per variable (EPV) | Clinical risk prediction models with binary outcomes |
| Tree-Based Ensemble ML | 2-12x logistic regression requirements [65] | Boosting: 2-3x larger; Random Forests: may need >12x | Complex data structures with non-linearities and interactions |
| Geometric Morphometrics | Depends on landmark number and variation [2] | Must account for template registration of out-of-sample data | Shape classification, nutritional assessment, morphological studies |
| Quantitative UX Research | Minimum 30-40 per group [66] | For statistical comparisons and reliable metrics | Benchmark studies, satisfaction measurement, performance testing |
Recent research has provided increasingly specific guidance for different modeling scenarios. For conventional logistic regression, sample size calculations should account for the event proportion, number of model parameters, and the predictive strength of the model (R²/C-statistic) [65]. For machine learning techniques, however, these sample size requirements often increase substantially. When developing prediction models using tree-based ensemble methods like random forests or gradient boosting machines, sample sizes may need to be 2-12 times larger than those recommended for logistic regression to achieve comparable predictive accuracy [65].
In geometric morphometric applications, sample size requirements are further influenced by the number of landmarks, the biological variation in the population, and the specific classification task. For the SAM Photo Diagnosis App Program, which aims to classify nutritional status of children aged 6-59 months from arm shape images, researchers collected data from 410 Senegalese children, with careful attention to balanced representation across nutritional status, age, and sex [2]. This sample design specifically addressed the need for sufficient representation across key variables that might influence shape variation.
The Special Challenge of Out-of-Sample Classification in Geometric Morphometrics
Geometric morphometrics faces unique sample size challenges related to the classification of new individuals not included in the original study. Unlike traditional anthropometric approaches where classification rules can be directly applied to new individuals, GM classifiers built from aligned coordinates require special methodologies to evaluate out-of-sample cases [2]. This necessitates not only sufficient sample sizes for model development but also careful consideration of how new individuals will be registered to the existing template.
The process of obtaining registered coordinates for new individuals in the training sample's shape space is not straightforward and requires methodological solutions beyond standard GM practices [2]. Specifically, the choice of template configuration for registering out-of-sample raw coordinates can significantly impact classification performance, making template selection a critical consideration in study design. These additional complexities introduce potential sources of error that must be accounted for in sample size planning, often necessitating larger samples than might be required for less complex morphological analyses.
Variable Selection and Dimensionality Reduction
The Curse of Dimensionality in Geometric Morphometrics
Geometric morphometric data naturally exists in high-dimensional spaces, with the number of dimensions proportional to the number of landmarks multiplied by the number of coordinates per landmark. This high dimensionality creates what is known as the "curse of dimensionality," where the available data becomes sparse in the corresponding shape space, increasing the risk of overfitting. With fixed sample sizes, as the number of variables or dimensions increases, the model's capacity to find spurious correlations that do not generalize to new data grows exponentially.
In practice, the effective dimensionality of morphometric data is often lower than the mathematical dimensionality due to biological constraints and correlations among landmarks. However, accurately characterizing this effective dimensionality requires careful analysis. Techniques such as Procrustes ANOVA can help partition shape variation into different components, providing insight into the true dimensionality of the data and guiding appropriate variable selection [2]. Understanding these patterns of variation and covariation is essential for developing robust classifiers that generalize well to new samples.
Strategies for Managing Variables and Complexity
Effective management of variables and complexity represents a crucial approach to mitigating overfitting risk. Several strategies have proven effective in geometric morphometrics and related fields:
Feature Selection Based on Biological Knowledge: Prior biological knowledge can guide the selection of landmarks and semilandmarks most relevant to the research question, reducing dimensionality while maintaining biological interpretability.
Collinearity Assessment: Understanding collinearity among shape variables is crucial for optimal classification results [2]. High collinearity can inflate variance estimates and reduce model stability, making careful assessment essential.
Dimensionality Reduction Techniques: Principal component analysis (PCA) and other dimensionality reduction methods can transform correlated shape variables into a smaller set of uncorrelated components, retaining most of the original variation with fewer variables.
Regularization Methods: Techniques such as ridge regression or LASSO can penalize model complexity during the estimation process, effectively reducing the risk of overfitting without explicitly removing variables.
In applications such as nutritional status classification from arm shape, the strategic placement of landmarks and semilandmarks can capture biologically meaningful shape variation while minimizing redundant information [2]. This careful variable design, combined with appropriate sample sizes, forms the foundation for robust classification models.
Experimental Protocols for Model Validation
Robust Validation Strategies
Implementing robust validation strategies is essential for detecting and preventing overfitting. The gold standard for validation involves assessing model performance on completely independent data that played no role in model development or selection [64]. For geometric morphometric classification, this presents specific challenges due to the need for coordinate registration before classification can occur [2].
Table 2: Comparison of Validation Methods for Assessing Overfitting
| Validation Method | Procedure | Advantages | Limitations |
|---|---|---|---|
| Holdout Validation | Split data into training and test sets | Simple to implement | Reduced sample for training; single split may be unrepresentative |
| K-Fold Cross-Validation | Partition data into K folds; train on K-1, test on held-out fold | More efficient data usage | Can be optimistic with dependent data; requires multiple models |
| Leave-One-Out Cross-Validation | Each observation serves as test set once | Maximum training data usage | Computationally expensive; high variance with correlated data |
| External Validation | Test on completely independent dataset | Most realistic performance estimate | Requires additional data collection; may differ in key characteristics |
| Out-of-Sample Simulation | Test classification of new individuals not in original alignment [2] | Addresses real-world application scenario | Requires methodological development for registration and classification |
For geometric morphometric studies specifically, standard validation approaches that split data into training and test sets after joint generalized Procrustes analysis may provide overly optimistic performance estimates, as they do not properly simulate the real-world scenario of classifying completely new individuals [2]. True out-of-sample validation requires methodological approaches that address how new individuals will be registered to the existing template, a process that remains poorly understood in the standard GM literature [2].
Workflow for Robust Geometric Morphometric Classification
The following experimental workflow illustrates a comprehensive approach to developing and validating geometric morphometric classifiers while addressing overfitting concerns:
This workflow emphasizes several critical points for addressing overfitting: proper sample size planning that accounts for model complexity and subgroup analyses; careful data collection with balanced representation across key variables; appropriate variable selection and dimensionality reduction techniques; and rigorous validation that specifically tests out-of-sample classification performance.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Research Reagent Solutions for Geometric Morphometric Studies
| Tool/Category | Specific Examples | Function/Purpose | Implementation Considerations |
|---|---|---|---|
| Data Collection Tools | Digital cameras; CT scanners; 3D laser scanners; calipers | Capture morphological data at appropriate resolution | Standardization of positioning and lighting; calibration protocols |
| Landmarking Software | MorphoJ; tpsDig2; 3D Slicer [67] | Precise landmark placement on specimens or images | Training for landmark reliability; protocols for difficult landmarks |
| GM Analysis Platforms | R (geomorph package); PAST; EVAN Toolbox | Statistical shape analysis and visualization | Compatibility with data formats; scripting for reproducibility |
| Template Registration | Custom algorithms for out-of-sample registration [2] | Align new individuals to existing reference sample | Impact on classification accuracy; parameter optimization |
| Validation Frameworks | Custom scripts for out-of-sample testing [2] | Assess real-world generalizability of classifiers | Proper separation of training and test data; performance metrics |
This toolkit represents essential resources for conducting geometric morphometric research with proper attention to overfitting concerns. The selection of appropriate tools should align with research objectives, with particular attention to methodologies that support robust validation and out-of-sample classification [2]. For nutritional assessment applications such as the SAM Photo Diagnosis App, additional considerations include offline functionality for field use and regular updating of training samples across different nutritional screening campaigns [2].
Addressing overfitting through appropriate balancing of variables and sample sizes requires both methodological rigor and practical judgment. There is no universal formula that applies to all research contexts, but rather a set of principles that must be adapted to specific research questions and constraints. The most effective approach combines adequate sample sizes determined through power considerations and previous research, careful variable selection informed by biological knowledge, appropriate model complexity matched to both the research question and available data, and robust validation strategies that honestly assess real-world performance.
In geometric morphometrics specifically, the challenge of classifying out-of-sample individuals adds complexity to standard validation approaches [2]. Future methodological development should focus on improving template registration methods for new individuals and establishing clearer guidelines for sample size requirements in relation to landmark number and biological variation. By adopting comprehensive approaches that address both statistical and domain-specific concerns, researchers can develop geometric morphometric classifiers that maintain their predictive performance when applied to new data in real-world scenarios, ultimately enhancing the scientific utility and practical impact of morphometric research.
Evaluating the Effect of Different Alignment Methods on Results
In the field of geometric morphometrics (GM), shape analysis provides a powerful toolkit for quantifying and comparing morphological forms. The process of shape alignment is a critical first step, directly influencing all subsequent statistical analyses and interpretations. This process is particularly crucial in applied research, such as the validation of classification models for out-of-sample data, where the alignment method determines how a new specimen is projected into the shape space of a reference sample. The central challenge, as highlighted in recent research on classifying children's nutritional status, is that classification rules derived from a reference sample cannot be applied to new individuals in a straightforward way. This is because standard alignment procedures, like Generalized Procrustes Analysis (GPA), are sample-dependent, requiring a series of processing steps before a classification rule can be applied to an out-of-sample individual [2] [20].
This guide objectively compares the performance of different alignment methodologies, focusing on their application within a research context aimed at validating geometric morphometric classification for out-of-sample data. We summarize experimental data, provide detailed methodologies, and offer visual workflows to assist researchers, scientists, and drug development professionals in selecting optimal alignment strategies for their specific needs.
Alignment in geometric morphometrics involves superimposing landmark configurations to isolate shape variation from differences in position, scale, and orientation. The most common method is Generalized Procrustes Analysis (GPA), which iteratively translates, scales, and rotates specimens to minimize the overall sum of squared distances between corresponding landmarks [2]. The resulting Procrustes coordinates reside in a curved, non-Euclidean shape space and are used for most subsequent statistical analyses.
However, a significant methodological gap exists when applying a classification model, built from a training sample, to a new specimen. The standard practice of performing a new global GPA including the new specimen is statistically invalid, as it alters the predefined shape space of the training data. To address this, a template-based registration approach has been proposed, where the raw coordinates of a new individual are aligned to a single template configuration derived from the training sample [2]. The choice of this template—such as the mean shape, a single specimen, or a pristine representative—becomes a critical parameter influencing classification accuracy.
Beyond traditional landmark-based GM, other alignment-free or outline-based methods exist, such as Fourier analysis of outlines [18]. Furthermore, fields like bioinformatics and computer vision face analogous challenges, leading to the development of various alignment-free sequence comparison methods [68] and computer vision approaches like Deep Learning, which can classify shapes with high accuracy without relying on landmark alignment [18].
Comparative Performance Analysis of Alignment Methods
The effectiveness of an alignment method is not absolute but is contingent on the data type, research question, and specific challenges like out-of-sample classification. The following table synthesizes findings from recent studies across multiple disciplines to provide a comparative overview.
Table 1: Performance Comparison of Different Alignment and Classification Methods
| Method | Application Context | Reported Performance/Accuracy | Key Advantages | Key Limitations |
|---|---|---|---|---|
| Generalized Procrustes Analysis (GPA) | Wing shape, Chrysodeixis moth identification [3] [69] | Validated for distinguishing invasive vs. native species | Standard, mathematically rigorous; effective for distinguishing closely related species [3]. | Sample-dependent; not designed for out-of-sample classification. |
| Template-Based Registration | Child nutritional status from arm shape [2] [20] | Accuracy varies with template choice (e.g., mean shape vs. single specimen) | Enables out-of-sample classification; computationally efficient. | Performance is sensitive to the choice of the template. |
| Fourier Analysis (Landmark-Free) | Carnivore tooth mark identification [18] | Low classification accuracy (<40% for carnivore agency) | Does not require landmark identification; captures outline shape. | Lower discriminant power compared to 3D methods in some contexts [18]. |
| Computer Vision (Deep Learning) | Carnivore tooth mark identification [18] | High classification accuracy (81%) | High accuracy; can learn features directly from images. | Requires large training datasets; potential "black box" interpretation. |
| Profile-Profile Alignment | Protein structure prediction [70] | TM-score 26.5% higher than sequence-profile methods | High sensitivity for detecting distant homologies. | Not directly applicable to geometric morphometric data. |
The table reveals that while traditional GPA is a robust internal analysis tool, it does not natively solve the out-of-sample problem. Template-based registration directly addresses this gap, but its performance is not fixed and depends on implementation details. Meanwhile, alternative methods like computer vision can achieve high accuracy, suggesting that the choice of analytical framework (landmark-based vs. image-based) can be as important as the alignment method itself.
Experimental Protocols for Key Studies
Protocol: Wing Geometric Morphometrics for Pest Identification
This protocol is derived from research validating the identification of invasive moth species [3] [69].
- Specimen Collection & Curation: Collect moths using pheromone-baited traps. Select only specimens with well-preserved right forewings to avoid shape distortion from damage.
- Species Validation: Validate the identity of reference specimens using definitive methods such as dissection of male genitalia or real-time PCR analysis [3] [69].
- Digitization and Landmarking: Carefully remove the forewing and photograph it under a digital microscope. Annotate a defined set of seven landmarks located at the intersections of wing veins in the central cell region [3].
- Data Processing: Input the 2D coordinate data of the landmarks into geometric morphometrics software (e.g., MorphoJ).
- Shape Alignment and Analysis: Perform a Generalized Procrustes Analysis (GPA) on the training sample to align all specimens. Subsequently, use statistical classifiers like linear discriminant analysis on the Procrustes coordinates to build a classification model [3].
Protocol: Template-Based Out-of-Sample Classification for Nutritional Status
This protocol outlines the methodology for classifying new individuals not included in the original training set [2] [20].
- Reference Sample Creation: Assemble a training sample with known classification (e.g., severe acute malnutrition vs. optimal nutritional status). Capture standardized photographs of the children's left arms.
- Landmarking and Training Model Construction: Digitize landmarks and semilandmarks along the arm's outline. Perform GPA on the entire training sample to define the reference shape space. Construct a classifier (e.g., linear discriminant analysis) based on the Procrustes coordinates [2].
- Template Selection: Select a template configuration from the training sample. Common choices include the Procrustes mean shape, a single representative specimen, or a specimen with a pristine landmark configuration.
- Out-of-Sample Processing: For a new child, capture a new arm photograph and digitize the same set of landmarks. Instead of performing a new GPA, align the new specimen's raw coordinates directly to the chosen template using a Procrustes superimposition.
- Classification: Project the newly aligned coordinates into the pre-existing reference shape space. Apply the pre-built classification model to assign a nutritional status to the new individual [2].
Visualizing the Out-of-Sample Classification Workflow
The following diagram illustrates the logical workflow and critical decision points involved in the template-based method for classifying out-of-sample data, as applied in nutritional status assessment.
Diagram 1: Workflow for Out-of-Sample Classification Using Template-Based Alignment. This diagram outlines the two-phase process for building a classification model from a reference sample (Phase 1) and subsequently using it to classify new individuals via template-based alignment (Phase 2). The choice of template is a critical decision point influencing the final result.
The Scientist's Toolkit: Essential Reagents and Materials
Successful geometric morphometric analysis, particularly in rigorous validation studies, relies on a combination of specialized software and consistent laboratory materials.
Table 2: Key Research Reagent Solutions for Geometric Morphometrics
| Item Name | Function/Application | Specific Example/Note |
|---|---|---|
| MorphoJ Software | Statistical software for geometric morphometrics | Used for performing Procrustes superimposition, statistical shape analysis, and discriminant analysis [3]. |
| Digital Microscope | High-resolution imaging of small structures | Essential for capturing detailed images of insect wings or other small specimens for landmark digitization [3] [69]. |
| Standardized Photography Setup | Consistent image capture for large subjects | Includes backdrop, fixed camera distance, and lighting to ensure uniform arm photographs for nutritional assessment [2]. |
| Sex Pheromone Lures | Targeted collection of insect specimens | Used in bucket or delta traps for a survey of specific moth pests like Chrysodeixis chalcites [3] [69]. |
| Real-time PCR Assay | molecular validation of species identity | Provides a definitive identification method to validate the training sample used in morphometric studies [3] [69]. |
The evaluation of alignment methods confirms that the choice of methodology has a profound effect on analytical results, especially when the goal is the practical application of models to new data. While Generalized Procrustes Analysis remains the gold standard for analyzing closed samples, its inherent sample-dependence is a major limitation for classification tasks. The template-based registration method directly addresses the out-of-sample problem, providing a practical pathway for deploying GM models in real-world settings, though its performance is sensitive to template selection.
Evidence from other fields suggests that alternative approaches like computer vision (Deep Learning) can achieve superior classification accuracy by bypassing landmark alignment altogether [18]. This indicates that the future of morphological classification may lie in hybrid approaches or the judicious application of multiple methods. For researchers validating geometric morphometric classifications, the initial choice between a landmark-based framework and an image-based, alignment-free framework is a fundamental strategic decision that will dictate the alignment challenges they face and the results they achieve.
Benchmarking Performance and Comparing with Emerging Technologies
In the field of geometric morphometric classification, the paramount goal is to develop models that generalize effectively to new, unseen data. The validation framework chosen to assess model performance is not merely a procedural step but a critical determinant of the reliability and interpretability of research findings. Within the broader thesis on validating geometric morphometric classification on out-of-sample data, understanding the distinction between cross-validation and the use of an independent test set is fundamental. These techniques serve complementary roles in the model development and evaluation pipeline, yet they are often conflated or misapplied. This guide provides an objective comparison of these core validation strategies, detailing their operational protocols, comparative performance data, and optimal application within morphometric research.
Core Concepts and Definitions
The Tripartite Data Splitting Paradigm
In supervised machine learning, including geometric morphometric classification, the available dataset is typically partitioned into three distinct subsets, each serving a unique purpose in the model lifecycle [71] [72].
- Training Set: This subset is used to fit the model's parameters. For example, in a neural network, the training set determines the optimal weights between neurons through algorithms like back-propagation [71] [72].
- Validation Set: This subset is used for model selection and hyperparameter tuning. It provides an unbiased evaluation of a model fit during the experimentation phase. In the context of a Multilayer Perceptron (MLP), the validation set helps determine the optimal number of hidden units or acts as a stopping criterion for the back-propagation algorithm [72].
- Test Set: This subset is held back entirely until the very end of the research process. It is used only for the final, unbiased evaluation of a fully-specified model (with all parameters and hyperparameters chosen). Its purpose is to estimate the true out-of-sample generalization error. After assessing the final model on the test set, the model must not be tuned any further [72].
The separation of validation and test sets is crucial because using the test set for model selection can lead to an optimistically biased estimate of generalization error, as the model may have been indirectly fitted to the test set [72].
The Role of Cross-Validation
Cross-validation is a powerful resampling technique used primarily for two purposes: (1) to provide a robust estimate of a model's predictive performance, and (2) to aid in model selection and hyperparameter tuning without needing a separate, dedicated validation set [73] [74].
The most common form is k-fold cross-validation. In this method, the original dataset (typically the training portion) is randomly partitioned into k equal-sized subsamples or "folds". Of the k folds, a single fold is retained as the validation data for testing the model, and the remaining k-1 folds are used as training data. The cross-validation process is then repeated k times, with each of the k folds used exactly once as the validation data. The k results can then be averaged to produce a single estimation [73]. This method ensures that every observation in the dataset is used for both training and validation exactly once, thereby maximizing data usage and providing a stable performance estimate [73] [74].
Comparative Analysis of Validation Frameworks
Quantitative Performance Comparison
Different validation strategies can yield significantly different estimates of model performance and require varying computational resources. The table below summarizes a quantitative comparison based on empirical studies.
Table 1: Quantitative Comparison of Validation Framework Performance
| Validation Method | Statistical Power | Statistical Confidence | Computational Cost | Risk of Optimistic Bias | Recommended Context |
|---|---|---|---|---|---|
| Single Holdout Validation | Low [75] | Low [75] | Low | High [75] | Very large datasets, initial prototyping |
| K-Fold Cross-Validation | Moderate | Moderate | Moderate | Moderate | Most standard datasets and models [73] |
| Stratified K-Fold | High (for imbalanced classes) | High (for imbalanced classes) | Moderate | Low | Classification with imbalanced classes [76] |
| Nested K-Fold Cross-Validation | High [75] | High [75] | High | Low [76] [75] | Final model evaluation, small datasets, hyperparameter tuning [76] |
| Leave-One-Out (LOOCV) | High for small N | High for small N | Very High | Low | Very small datasets [73] [74] |
Empirical evidence from speech, language, and hearing sciences demonstrates that models evaluated with a single holdout method exhibited low statistical power and confidence, leading to a significant overestimation of classification accuracy [75]. In contrast, nested k-fold cross-validation resulted in the highest statistical confidence and power while providing an unbiased accuracy estimate. The required sample size using the single holdout method could be 50% higher than that needed with nested k-fold cross-validation [75].
Experimental Protocols
To ensure reproducibility and rigorous comparison, the following standardized protocols are recommended for the key validation methods.
Protocol 1: Standard K-Fold Cross-Validation
- Objective: To obtain a robust estimate of model performance and aid in hyperparameter tuning.
- Procedure:
- Randomly shuffle the dataset and split it into k folds of approximately equal size. A common value is k=5 or k=10 [73].
- For each unique fold:
- Designate the current fold as the validation set.
- Designate the remaining k-1 folds as the training set.
- Train the model on the training set.
- Evaluate the model on the validation set and record the performance metric (e.g., accuracy, F1-score).
- Calculate the average performance across all k folds. This is the cross-validation score.
- Considerations: For classification problems with imbalanced classes, use stratified k-fold to ensure each fold has a representative proportion of each class label [76] [73].
Protocol 2: Nested K-Fold Cross-Validation
- Objective: To perform both hyperparameter tuning and model evaluation without bias, providing a final, reliable performance estimate [76] [75].
- Procedure:
- Define an outer loop: split the data into m outer folds (e.g., m=5).
- Define an inner loop: for each outer fold, the data not in that fold will be used for a standard k-fold cross-validation.
- For each outer fold:
- Hold out the current outer fold as the test set.
- Use the remaining data (the training set) to perform an inner k-fold cross-validation to find the best hyperparameters.
- Train a final model on the entire training set using these best hyperparameters.
- Evaluate this final model on the held-out test set (the outer fold) and record the performance.
- The final model performance is the average of the performances on the m outer test folds.
- Considerations: This method is computationally intensive but is considered the gold standard for obtaining an unbiased performance estimate, especially in knowledge-developing studies [76] [75].
Protocol 3: Independent Test Set Validation
- Objective: To provide a final, unbiased evaluation of a model that has been completely developed and tuned.
- Procedure:
- Before any model development or analysis begins, randomly split the dataset into a training/validation set (e.g., 70-80%) and a holdout test set (e.g., 20-30%) [71].
- Use the training/validation set for all steps of model development, including feature engineering, model selection, and hyperparameter tuning (potentially using cross-validation).
- Once a final model is selected, evaluate it a single time on the held-out test set to obtain the final performance metric.
- Considerations: The test set must be locked away and never used for any decision-making during the model development process. Violating this principle invalidates the test set's role as an unbiased evaluator [72].
Visualization of Validation Frameworks
The following diagrams illustrate the logical structure and data flow for the primary validation frameworks discussed.
K-Fold Cross-Validation Workflow
Diagram 1: K-Fold Cross-Validation Workflow. This process involves iteratively holding out a different fold for validation, training on the remainder, and averaging the results to get a robust performance estimate.
Relationship Between Validation Methods
Diagram 2: A hierarchical taxonomy of common validation methods, showing how complex methods like Nested Cross-Validation build upon simpler ones like K-Fold.
The Scientist's Toolkit: Essential Research Reagents
For researchers implementing these validation frameworks in geometric morphometric studies, the following tools and concepts are essential.
Table 2: Essential Reagents for Validation Research in Geometric Morphometrics
| Tool / Concept | Category | Function / Purpose | Example Instances |
|---|---|---|---|
| Stratified Splitting | Data Preprocessing | Ensures representative distribution of classes in each fold, critical for imbalanced morphometric data [76] [73]. | StratifiedKFold in scikit-learn |
| Nested Cross-Validation | Statistical Protocol | Provides an unbiased performance estimate when both model selection and evaluation are needed [76] [75]. | Custom loops using GridSearchCV within cross_val_score |
| Hyperparameter Grid | Model Tuning | Defines the search space for model optimization during validation. | param_grid in scikit-learn's GridSearchCV |
| Performance Metrics | Evaluation | Quantifies model performance; choice depends on the research question and data balance. | Accuracy, F1-Score, Precision, Recall, AUC-ROC [71] |
| Subject-Wise Splitting | Data Preprocessing | Splits data by subject/individual to prevent data leakage from repeated measures, a key concern in clinical or biological studies [76]. | GroupKFold in scikit-learn |
| Computational Resources | Infrastructure | Enables the execution of computationally intensive protocols like Nested CV or LOOCV. | High-Performance Computing (HPC) clusters, cloud computing |
The choice between cross-validation and an independent test set is not a matter of selecting a superior method but of correctly applying each within the appropriate stage of the research pipeline. Cross-validation, particularly in its more robust forms like nested k-fold, is an indispensable tool for model development and for obtaining a reliable performance estimate during experimental phases. In contrast, a strictly independent test set, kept in a "vault" until the final model is completely specified, is the non-negotiable standard for providing an unbiased assessment of how the model will perform in the real world on genuine out-of-sample data.
For researchers in geometric morphometric classification, adopting these rigorous validation frameworks is critical. The empirical evidence shows that simpler methods like single holdout validation can lead to significantly underpowered studies, overfitted models, and ultimately, non-reproducible results. By strategically employing k-fold cross-validation for model tuning and reserving an independent test set for final validation, scientists can ensure their findings are both statistically sound and generalizable, thereby advancing the field with greater confidence and credibility.
Interpreting Classification Accuracy and Discriminant Power
Geometric morphometrics (GM) has become an indispensable tool for classifying biological specimens, from distinguishing closely related species to identifying age-related morphological changes. However, the reported classification accuracy of GM studies can vary dramatically, creating a critical interpretation challenge for researchers. Understanding the factors that influence discriminant power—from methodological choices to analytical frameworks—is essential for properly evaluating GM's utility in taxonomic, ecological, and biomedical research.
This guide examines the performance of geometric morphometrics against traditional methods and emerging computational approaches, with particular emphasis on validation practices that ensure reliable application to out-of-sample data. We synthesize evidence across biological disciplines to provide researchers with evidence-based criteria for evaluating classification accuracy in morphometric studies.
Performance Comparison: Geometric Morphometrics vs. Alternative Methods
Comparative Classification Performance Across Applications
Table 1: Classification accuracy of geometric morphometrics across biological disciplines
| Application Domain | Biological Structures | Classification Purpose | Reported Accuracy | Key Methodological Factors | Citation |
|---|---|---|---|---|---|
| Forensic Dentistry | Mandible (27 landmarks) | Adolescent vs. Adult age classification | 65-67% | Panoramic radiographs, DFA with cross-validation | [4] [77] |
| Pest Identification | Wing venation (7 landmarks) | Invasive vs. native moth species | High (exact % not reported) | Limited landmark strategy for damaged specimens | [3] |
| Nutritional Assessment | Arm shape from images | Severe acute malnutrition screening | Validated for SAM identification | Template registration for out-of-sample classification | [2] |
| Carnivore Agency ID | Tooth mark outlines | Carnivore species from bite marks | <40% (2D outlines) | Fourier analysis of outlines | [18] |
| Mammalian Taxonomy | Skull morphology | Cryptic species complex | Better after allometry removal | 3D GMM with allometric correction | [78] |
Performance Relative to Alternative Approaches
Table 2: Methodological comparison of shape analysis approaches
| Methodological Approach | Classification Context | Relative Performance | Key Advantages | Key Limitations | |
|---|---|---|---|---|---|
| Geometric Morphometrics | Species discrimination, age classification | Variable (40-95% across studies) | Visualizes shape change; accounts for allometry | Sensitive to landmark selection and alignment | |
| Traditional Linear Morphometrics | Taxonomic studies | High raw discrimination but size-confounded | Simple measurement protocol; extensive historical data | Cannot separate size from shape; measurement redundancy | [78] |
| Computer Vision (Deep Learning) | Carnivore tooth mark classification | 79.5-81% accuracy | Automates feature extraction; handles complex patterns | Limited application to fossil record with taphonomic changes | [18] |
| Functional Data GM | Shrew species classification | Superior to classical GM | Captures continuous shape as functions; better for subtle variations | Complex implementation; computationally intensive | [28] |
Experimental Protocols and Methodological Framework
Standardized Workflow for GM Classification Studies
The following diagram illustrates the core experimental workflow for geometric morphometric classification studies, highlighting critical decision points that influence accuracy and discriminant power:
Critical Experimental Considerations
Landmark Strategy and Selection
Landmark configuration profoundly influences classification accuracy. Counterintuitively, studies across six insect families demonstrated that small subsets of landmarks (as few as 3-4) can outperform full landmark sets in species discrimination [79]. This suggests careful landmark selection focusing on morphologically informative points is more important than maximizing landmark quantity.
Two approaches for identifying influential landmarks have been proposed:
- Random subset method: Systematically testing random landmark combinations to identify high-performing subsets
- Hierarchical method: Selecting landmarks based on their individual contribution to shape discrimination [79]
Out-of-Sample Validation Framework
A significant methodological challenge in GM involves classifying new specimens not included in the original training set. Standard protocols that perform Generalized Procrustes Analysis (GPA) on combined training and test sets introduce circularity and inflate performance metrics [2].
The recommended approach involves:
- Performing GPA alignment exclusively on the training set
- Using a template specimen from the training set as a reference for aligning out-of-sample individuals
- Applying the classification model derived from training set Procrustes coordinates to the newly aligned test specimens [2]
This method more accurately reflects real-world application scenarios where new specimens must be classified without recalculating the entire morphospace.
Dimensionality Reduction Optimization
Morphometric data presents a high-dimension-low-sample-size challenge that requires careful dimensionality reduction before classification. A variable number of Principal Component (PC) axes approach has demonstrated superior performance compared to fixed-PC or partial least squares methods [7].
The optimal approach uses cross-validation accuracy rather than variance explained as the criterion for selecting the number of PC axes, preventing overfitting and improving generalizability [7].
Analytical Toolkit for Classification Studies
Research Reagent Solutions
Table 3: Essential tools for geometric morphometric classification studies
| Tool Category | Specific Solutions | Primary Function | Application Notes | |
|---|---|---|---|---|
| Imaging Systems | Digital microscopes, Panoramic radiography, Standardized photography | High-resolution image acquisition for 2D GM | Resolution standardization critical for comparability | |
| Digitization Software | tpsDig2, MorphoJ, ImageJ with plugins | Landmark and semi-landmark coordinate collection | Manual landmarking introduces observer error that must be quantified | |
| Alignment & Analysis | MorphoJ, EVAN Toolbox, GEOM | Procrustes superimposition, PCA, DFA | MorphoJ most widely used; includes cross-validation options | |
| Statistical Packages | R (geomorph, shapes), PAST | Advanced statistical analysis and visualization | R provides greater flexibility for custom analyses | |
| Template Registration | SAM Photo Diagnosis App, Custom algorithms | Out-of-sample specimen alignment | Essential for real-world application without retraining models | [2] |
Interpreting Classification Accuracy: Key Considerations
The following diagram outlines the primary factors that influence reported classification accuracy in geometric morphometric studies, providing a framework for critical evaluation:
Discussion and Research Implications
Interpreting Varied Classification Performance
The wide range of classification accuracy reported across GM studies (40-95%) reflects both biological reality and methodological choices. Studies examining subtle shape differences, such as age-related mandibular changes, understandably report more modest accuracy (65-67%) [4] [77], while applications with more pronounced morphological distinctions achieve higher performance.
Critically, studies that remove allometric variation before classification typically show improved discriminant power for non-size-related shape differences, revealing true morphological distinctions rather than size disparities [78]. This highlights the importance of examining whether reported accuracy derives from size or shape differences.
Emerging Approaches and Future Directions
Functional Data Geometric Morphometrics (FDGM) represents a promising advancement that converts discrete landmark data into continuous curves, potentially capturing more subtle shape variations [28]. In shrew craniodental classification, FDGM outperformed classical GM, particularly when combined with machine learning classifiers.
Similarly, 3D geometric morphometrics addresses significant limitations of 2D approaches for complex morphological structures. While 2D GM showed limited discriminant power (<40%) for carnivore tooth mark classification, future research emphasizing 3D topographical information promises substantially improved resolution [18].
Best Practices for Methodological Reporting
To enhance interpretability and reproducibility of GM classification studies, researchers should:
- Explicitly report validation methods, distinguishing between resubstitution and cross-validation accuracy [7]
- Document landmarking protocols and assess observer error through repeated measurements
- Test landmark influence through subset analysis rather than assuming more landmarks improve accuracy [79]
- Address allometry explicitly by reporting results both before and after allometric correction [78]
- Provide out-of-sample classification protocols when proposing methods for real-world application [2]
Classification accuracy in geometric morphometrics is profoundly influenced by methodological choices from landmark selection to validation protocols. While GM provides powerful discriminatory capability for biological classification, reported accuracy must be interpreted in context of methodological decisions and biological effect sizes. Emerging approaches including functional data analysis, 3D morphometrics, and integration with machine learning classification promise enhanced discriminant power, particularly when coupled with rigorous validation frameworks that test performance on genuinely out-of-sample data.
The quantitative analysis of biological shape is a fundamental tool in evolutionary biology, anthropology, and paleontology. For decades, geometric morphometrics (GM) has been the cornerstone methodology for these analyses, primarily relying on landmark-based statistical approaches. However, with the rise of artificial intelligence, deep learning (DL) methods are emerging as powerful alternatives. This guide provides a comparative analysis of both approaches, focusing on a critical benchmark: their performance and reliability in classifying shapes, particularly on out-of-sample data. The validation of methods on unseen data is paramount for establishing robust, generalizable conclusions in scientific research.
Methodological Foundations
The fundamental difference between GM and DL lies in their approach to feature extraction—how they quantify and represent shape information from raw image data.
Geometric Morphometrics (GM): The Conventional Approach
The standard GM pipeline is a two-step process:
- Generalized Procrustes Analysis (GPA): This step superimposes landmark configurations by scaling, translating, and rotating them to minimize the sum of squared distances between corresponding landmarks. This aligns the shapes into a common coordinate system, removing variations due to position, orientation, and scale.
- Principal Component Analysis (PCA): The aligned coordinates are then subjected to PCA. This statistical technique projects the high-dimensional landmark data onto a new set of axes (Principal Components) that capture the greatest directions of shape variation in the data. The resulting low-dimensional scatterplots are visually interpreted to assess shape similarities and differences between groups [62].
A significant limitation of this approach is its dependence on anatomically defined homologous landmarks, which can be difficult to define consistently across phylogenetically distant species or different developmental stages [80]. Furthermore, the interpretation of PCA scatterplots, while intuitive, is often subjective. Researchers may selectively report PC combinations that support their hypotheses, while ignoring others that show conflicting patterns, as was noted in the analysis of the Homo Nesher Ramla remains [62].
Deep Learning (DL): The Emerging Paradigm
Deep learning approaches, particularly Convolutional Neural Networks (CNNs) and Autoencoders, learn to extract relevant features directly from the raw pixel data of images without requiring pre-defined landmarks.
- Convolutional Neural Networks (CNNs) use layers of filters to automatically detect hierarchical patterns and features in images, from simple edges to complex morphological structures. These features are then used for classification tasks [81] [82].
- Autoencoders (AEs) and Variational Autoencoders (VAEs) are designed for unsupervised learning. They compress input images into a low-dimensional latent space (encoding) and then attempt to reconstruct the original image from this compressed representation (decoding). The latent space serves as a non-linear, information-dense representation of the shape [80].
A advanced architecture known as Morphological regulated Variational Autoencoder (Morpho-VAE) combines supervised and unsupervised learning. It integrates a classifier module directly into the VAE architecture, forcing the model to learn latent features that are optimal not only for reconstructing the shape but also for distinguishing between predefined class labels (e.g., biological families) [80].
Table 1: Core Methodological Differences Between GM and Deep Learning for Shape Classification.
| Feature | Geometric Morphometrics (GM) | Deep Learning (DL) |
|---|---|---|
| Core Approach | Landmark-based statistics | Representation learning from pixels/voxels |
| Feature Extraction | Manual (Expert-defined landmarks) | Automatic (Model-learned features) |
| Dimensionality Reduction | Linear (Principal Component Analysis) | Non-linear (e.g., Latent space in VAEs) |
| Data Input | Landmark coordinates | 2D images or 3D meshes |
| Primary Strength | Interpretability of shape changes | Ability to model complex, non-linear shape features |
| Key Weakness | Subjective landmarking; poor performance on non-homologous structures [80] [62] | "Black box" nature; large data requirements |
Comparative Performance Analysis
Recent studies have directly or indirectly compared the performance of GM and DL methods, with a consistent trend emerging regarding their classification accuracy and robustness.
Quantitative Performance Metrics
Empirical evidence demonstrates that DL models frequently achieve superior classification accuracy compared to GM and other traditional machine learning methods.
- Primate Mandible Classification: In a study classifying primate mandibles into seven families, the Morpho-VAE model achieved a median validation accuracy of 90%. More importantly, the latent space it generated showed better cluster separation than PCA when quantified using a Cluster Separation Index (CSI) [80].
- Neurodegenerative Disease Classification: A large-scale study comparing classifiers on structured volumetric MRI data found that a deep neural network (DNN) produced the best overall performance measures (Cohen’s kappa, accuracy, F1-score) for multi-class classification of eleven neurodegenerative syndromes, outperforming Support Vector Machines (SVM) and ensemble methods [83].
- Carnivore Tooth Mark Identification: A direct comparison on classifying carnivore agency from tooth marks showed a stark contrast. GM methods, whether using semi-landmarks or outline analysis, had a low discriminant power (<40%). In contrast, computer vision approaches using Deep Convolutional Neural Networks (DCNN) and Few-Shot Learning classified the same experimental tooth pits with accuracies of 81% and 79.52%, respectively [18].
Table 2: Summary of Comparative Performance from Reviewed Studies.
| Study & Application | Geometric Morphometrics / Traditional ML Performance | Deep Learning Performance |
|---|---|---|
| Primate Mandible Classification [80] | Less separated clusters in PCA space | 90% accuracy; superior cluster separation (Morpho-VAE) |
| Carnivore Tooth Mark ID [18] | <40% accuracy (2D outline analysis) | 81% accuracy (DCNN) |
| Neurodegenerative Disease [83] | Lower overall performance (SVM, Random Forest) | Best overall performance (Deep Neural Network) |
| Shrew Crania Classification [28] | Lower classification accuracy (Classical GM) | Higher accuracy (Functional Data GM with ML) |
Robustness and Generalization
The reliability of a model on out-of-sample data is the cornerstone of valid scientific inference.
- GM and PCA Reliability Concerns: A critical study argues that PCA outcomes are "artefacts of the input data" and are "neither reliable, robust, nor reproducible" as often assumed. The subjective interpretation of PCA plots can lead to unstable taxonomic and phylogenetic conclusions, a concern raised with an estimated 18,000 to 32,900 existing studies potentially affected [62].
- DL Generalization Capability: Deep learning models show a strong ability to generalize. For instance, CNNs trained exclusively on synthetic data from numerical simulations have been shown to successfully classify fundamental geometric shapes based solely on real, experimentally measured ultrasound echoes [81]. Furthermore, research into making DL more reliable includes using landscape metrics to assess the similarity between training and new test data, helping to determine a model's applicability to a new dataset [84].
Experimental Protocols
To ensure reproducibility, this section outlines the core experimental workflows and key reagents used in the cited studies.
A. Data Preparation:
- Sample Collection: 147 mandible samples from seven primate families and an outgroup (carnivora Phocidae).
- Image Generation: 3D mandible data are projected from three directional views (e.g., dorsal, lateral, ventral) to generate 2D image data.
- Data Splitting: Images are split into training, validation, and test sets.
B. Model Architecture and Training (Morpho-VAE):
- Architecture: A Variational Autoencoder is combined with a classifier network. The encoder network compresses the input image into a low-dimensional latent variable (ζ). This latent variable is used by two parallel networks: the decoder (for image reconstruction) and the classifier (for family prediction).
- Loss Function: The model is trained using a hybrid loss function:
E_total = (1 - α) * E_VAE + α * E_C, whereE_VAEis the reconstruction and regularization loss from the VAE, andE_Cis the cross-entropy classification loss. The hyperparameterα(set to 0.1 via cross-validation) balances the two objectives. - Training: The model is trained for 100 epochs to optimize the total loss.
C. Evaluation:
- Classification Accuracy: Median accuracy on the validation set is calculated.
- Cluster Separation: The latent space embeddings (ζ) for all samples are visualized. The Cluster Separation Index (CSI) is computed to quantitatively compare the separation achieved by Morpho-VAE against standard PCA and VAE.
Workflow Visualization
The following diagram illustrates the logical relationship and core differences between the standard GM workflow and a representative DL workflow (Morpho-VAE) for shape classification.
The Scientist's Toolkit: Key Research Reagents
Table 3: Essential Materials and Software Solutions for GM and DL Shape Analysis.
| Item Name | Function/Brief Explanation | Context of Use |
|---|---|---|
| Landmarking Software(e.g., tpsDig2, MorphoJ) | Tools for manually placing and managing anatomical landmarks on 2D or 3D data. | Geometric Morphometrics |
| Generalized Procrustes Analysis (GPA) | Algorithm to remove non-shape differences (size, rotation, translation) from landmark data. | Geometric Morphometrics |
| MORPHIX Python Package | A supervised machine learning package designed to process landmark data with classifiers, proposed as an alternative to PCA. [62] | Advanced GM / ML |
| Convolutional Neural Network (CNN) | A class of deep neural networks designed for processing pixel data, ideal for automatic feature extraction from images. [81] [82] | Deep Learning |
| Variational Autoencoder (VAE) | A generative model that learns a compressed, latent representation of input data, useful for feature reduction and synthesis. [80] | Deep Learning |
| Graph Autoencoder | A neural network designed to learn from graph-structured data, such as 3D anatomical meshes. [85] | Deep Learning (3D Meshes) |
| MedShapeNet19 Dataset | A curated benchmark dataset of 19 anatomical classes from surface meshes, used for standardized evaluation of 3D shape analysis methods. [85] | Deep Learning Benchmarking |
The comparative analysis reveals a clear paradigm shift in shape classification. While geometric morphometrics provides an interpretable framework for landmark-based shape analysis, its reliance on subjective landmarking and linear statistics like PCA makes it less accurate and potentially less reliable for complex classification tasks and out-of-sample validation.
In contrast, deep learning methods demonstrate superior performance in multiple, independent studies. They automate feature extraction, capture complex non-linear shape variations, and achieve higher classification accuracy and better cluster separation. The primary challenge with DL remains the "black box" nature of its decisions. However, architectures like Morpho-VAE, which couple reconstruction with classification, offer a path toward more interpretable and powerful models. For researchers requiring the highest possible accuracy and robustness for validating classifications on new data, deep learning represents the more promising and powerful toolkit. Future progress will likely hinge on the development of standardized benchmarks, like MedShapeNet19 [85], and continued efforts to enhance the interpretability of deep learning models.
Assessing the Limitations of 2D GM and the Promise of 3D Approaches
Geometric morphometrics (GM) has revolutionized the quantitative analysis of form by enabling researchers to statistically compare complex biological shapes. As a discipline, it provides a powerful toolkit for testing hypotheses about morphological variation, evolution, and development. However, a significant methodological divergence has emerged between two-dimensional (2D) and three-dimensional (3D) approaches, with important implications for the validation of classification models on out-of-sample data. This guide objectively compares these methodologies, examining their performance characteristics, limitations, and applications within a framework focused on reliable generalization of morphological classifications.
The fundamental distinction between these approaches lies in their data capture: 2D GM analyzes landmarks projected onto a single plane, while 3D GM utilizes the complete spatial configuration of landmarks. This difference profoundly impacts analytical outcomes, particularly when models trained on one dataset are applied to new, unseen data. Within the context of taxonomic identification, morphological analysis, and evolutionary biology, understanding these methodological trade-offs is essential for selecting appropriate protocols and interpreting results with scientific rigor.
Fundamental Limitations of 2D Geometric Morphometrics
Two-dimensional geometric morphometrics suffers from several inherent constraints that can compromise its reliability for out-of-sample classification and generalization.
Information Loss and Projection Bias
The most significant limitation of 2D GM is dimensional reduction, which inevitably flattens complex 3D structures into simplified representations. This process discards critical morphological information along the axis of projection, potentially distorting true biological shapes and relationships. Studies comparing both methodologies consistently demonstrate that 2D approaches capture only a subset of the morphological variation detectable with 3D methods [86]. In taxonomic studies of social voles (Microtus), for instance, 2D analyses failed to distinguish between certain species that were clearly differentiated using 3D GM, particularly for species with similar diploid chromosome numbers (M. guentheri-M. hartingi and M. anatolicus-M. schidlovskii) [86].
Limited Landmark Configurations
The types of landmarks available for 2D analysis are inherently restricted compared to 3D approaches. Type III landmarks (constructed points located around outlines or in relation to other landmarks) are particularly problematic in 2D space because their biological homology becomes difficult to establish and verify [87]. This limitation directly impacts analytical power and the biological meaningfulness of resulting morphospaces. For out-of-sample validation, this means that models may learn projection artifacts rather than biologically significant shape characteristics, reducing their generalizability to new specimens.
Orientation Sensitivity and Measurement Error
2D GM results are highly sensitive to specimen orientation during imaging, introducing potential measurement artifacts that can distort morphological comparisons. Minor variations in positioning can significantly alter landmark coordinates, adding noise that reduces statistical power and compromises model generalizability [18]. This sensitivity poses particular challenges for out-of-sample classification, as orientation differences between training and validation datasets can lead to misclassification even when true morphology is similar.
Advantages of 3D Geometric Morphometrics
Three-dimensional geometric morphometrics addresses many limitations of 2D approaches while introducing unique capabilities for morphological analysis and classification.
Comprehensive Morphological Capture
3D GM enables researchers to capture the complete geometry of biological structures, preserving all spatial relationships between landmarks. This comprehensive data capture provides a more accurate representation of true biological form, allowing for more nuanced analyses of shape variation. In studies of fossil shark teeth, 3D GM not only recovered the same taxonomic separations identified by traditional morphometrics but also captured additional shape variables that 2D methods failed to detect [88]. This enhanced sensitivity provides greater discriminatory power for classifying novel specimens.
Enhanced Biological Meaningfulness
The morphospaces generated through 3D GM demonstrate superior biological interpretability because they more accurately represent actual anatomical relationships. As noted in theoretical foundations of morphometrics, for morphospaces to be useful, "relative locations and distances in such spaces must have biological meaning" and "directions within the morphospace should have biological meaning" [89]. 3D approaches better satisfy these criteria by maintaining the true spatial configuration of anatomical structures, resulting in more biologically meaningful statistical comparisons and more reliable out-of-sample predictions.
Methodological Flexibility and Technological Integration
Modern 3D GM benefits from integration with advanced imaging technologies including photogrammetry, micro-CT scanning, and laser scanning [86] [87]. These methods enable the creation of highly accurate 3D models that capture both external and internal structures. Photogrammetry, in particular, offers distinct advantages as an economical, portable method that accurately reproduces the geometry and color pattern of complex objects [86]. This technological flexibility allows researchers to select the most appropriate capture method for their specific research questions and specimen types.
Comparative Experimental Data
Direct comparisons between 2D and 3D geometric morphometrics reveal significant differences in their performance characteristics for classification tasks.
Table 1: Classification Performance Comparison Between 2D and 3D GM
| Study Organism | 2D GM Accuracy | 3D GM Accuracy | Performance Difference | Key Findings |
|---|---|---|---|---|
| Social voles (Microtus) [86] | Lower classification rates | High correct classification | Significant improvement with 3D | 3D GM distinguished species with similar chromosome numbers where 2D failed |
| Fossil shark teeth [88] | Captured basic taxonomic separation | Captured additional shape variables | Enhanced morphological resolution | 3D provided more comprehensive morphological information |
| Carnivore tooth marks [18] | <40% discriminant power | Potential for improved performance | Substantial | 2D outlines showed low classification accuracy for modifying agent |
Table 2: Methodological Characteristics and Applications
| Characteristic | 2D Geometric Morphometrics | 3D Geometric Morphometrics |
|---|---|---|
| Data Collection | Faster, less expensive | More time-consuming, requires specialized equipment |
| Information Capture | Limited to projected landmarks | Comprehensive 3D coordinates |
| Analytical Power | Reduced for complex shapes | Enhanced for complex morphological structures |
| Specimen Orientation | Highly sensitive | Less sensitive with proper registration |
| Landmark Types | Limited primarily to Types I and II | All landmark types, including sliding semilandmarks |
| Ideal Applications | Preliminary analyses, large-scale 2D collections | Detailed taxonomic studies, complex morphological questions |
Experimental Protocols and Methodologies
Standardized 3D GM Protocol for Taxonomic Identification
The following workflow illustrates the standard protocol for 3D geometric morphometric analysis, optimized for taxonomic classification tasks:
Detailed Methodology: Fossil Shark Teeth Analysis
A comparative study on fossil shark teeth exemplifies rigorous protocol design for validating taxonomic identification [88]. Researchers analyzed 120 specimens including fossil and extant lamniform shark teeth using the following specific methods:
- Landmark Configuration: Seven homologous landmarks and eight semilandmarks were digitized on each specimen using TPSdig 2.32 software
- Semilandmark Placement: Semilandmarks were placed along the curved profile of the ventral margin of the tooth root where no homologous points could be detected
- Data Collection: Landmarks and semilandmarks were digitized on either the lingual or labial side of teeth, as these were the only accessible sides for fossil specimens
- Statistical Validation: The resulting landmark data underwent Generalized Procrustes Analysis followed by multivariate statistical tests to validate a priori qualitative taxonomic separations
This protocol successfully confirmed generic-level taxonomic distinctions while capturing subtle morphological variations that traditional morphometrics had overlooked [88].
Methodology: Social Vole Skull Analysis
Research on social vole skulls provides another exemplary protocol for 3D GM [86]:
- Imaging Method: Photogrammetry was used to construct 3D models of skulls from multiple overlapping photographs
- Landmark Scheme: 3D landmarks were placed on crania and mandibles to capture overall skull shape
- Comparative Framework: Results were compared with previous 2D geometric morphometric and linear morphometric analyses
- Classification Testing: Canonical Variate Analysis (CVA) and discriminant function analysis were used to test classification accuracy across species
This approach demonstrated that 3D GM could distinguish between morphologically similar species that 2D methods failed to separate, highlighting its superior discriminatory power for taxonomically challenging groups [86].
The Scientist's Toolkit: Essential Research Solutions
Implementing robust 3D geometric morphometrics requires specific methodological tools and approaches. The following table details essential solutions for researchers designing validation studies for out-of-sample classification:
Table 3: Research Reagent Solutions for 3D Geometric Morphometrics
| Solution Category | Specific Tools/Methods | Function & Application |
|---|---|---|
| 3D Data Acquisition | Photogrammetry [86] | Economical, portable 3D model creation from photographs |
| Micro-CT Scanning [87] | High-resolution internal and external structure capture | |
| Laser Scanning [86] | Precise surface geometry capture | |
| Landmark Digitization | TPSdig Software [88] | Precise landmark and semilandmark placement on digital specimens |
| Homologous Landmarks [88] | Biologically corresponding points across specimens | |
| Semilandmarks [88] | Points along curves and surfaces to capture outline geometry | |
| Data Processing | Generalized Procrustes Analysis [87] | Superimposition that removes non-shape variation (position, orientation, scale) |
| Principal Components Analysis [87] | Dimensionality reduction to identify major shape variation axes | |
| Thin-Plate Spline [87] | Visualization of shape deformations between specimens | |
| Statistical Validation | Discriminant Function Analysis [86] | Classification and group separation analysis |
| Cross-Validation [90] | Method for testing model performance on unseen data | |
| Leave-Profile-Out Validation [90] | Specialized CV for 3D data preventing autocorrelation artifacts |
Addressing Data Challenges in 3D Morphometrics
Sample Size Limitations and Data Augmentation
A significant challenge in 3D GM is obtaining sufficient sample sizes for robust statistical analysis, particularly for rare specimens such as fossils. Generative Adversarial Networks (GANs) and other computational learning algorithms offer promising solutions by creating synthetic 3D landmark data that augment limited datasets [87]. These approaches can help overcome the "insufficiency of information density" that plagues small sample studies, improving model generalizability and reducing overfitting in classification tasks.
Validation Methodologies for 3D Data
Proper validation is crucial for reliable out-of-sample classification. Leave-Profile-Out Cross-Validation (LPOCV) has been advocated as more appropriate for 3D data than traditional Leave-Sample-Out Cross-Validation (LSOCV) because it accounts for vertical autocorrelation in 3D structures [90]. Using inappropriate validation methods can result in data leakage and overly optimistic performance estimates, compromising the real-world applicability of classification models.
The methodological evolution from 2D to 3D geometric morphometrics represents significant progress in quantitative morphology, offering enhanced capabilities for taxonomic classification and morphological analysis. Experimental evidence consistently demonstrates that 3D approaches capture more comprehensive morphological information, achieve higher classification accuracy, and provide more biologically meaningful results than 2D methods.
For researchers focused on validating classifications on out-of-sample data, 3D GM provides superior generalizability when implemented with appropriate protocols, including rigorous landmark schemes, proper validation methods like LPOCV, and modern data acquisition technologies. While 2D methods retain utility for preliminary analyses or when working with existing 2D collections, 3D approaches offer more robust solutions for challenging taxonomic problems and complex morphological questions. As imaging technologies continue to advance and computational methods become more accessible, 3D geometric morphometrics is poised to become the standard for morphological classification and analysis across biological and paleontological disciplines.
Establishing Confidence Indicators for Taxonomic and Diagnostic Decisions
Validating classification methods is paramount for taxonomic and diagnostic decisions based on geometric morphometric (GM) data. This is particularly critical when applying established classification rules to new, out-of-sample individuals, a common challenge in real-world research applications [2]. Geometric morphometrics, which quantifies biological shape using Cartesian landmark coordinates, is widely employed across ecology, archaeology, and paleontology for taxonomic identification and ecological affinity assessment [57]. However, the replicability of GM analyses and the confidence in their resulting classifications can be compromised by multiple sources of measurement error. Establishing clear confidence indicators is therefore essential for interpreting results reliably, especially when extending analyses to fossil specimens, clinical nutritional assessments, or metagenomic classifications [2] [18] [91]. This guide objectively compares the performance of various GM protocols and computational classification methods, evaluating their robustness to different error sources and their efficacy in handling out-of-sample data, to provide a framework for making high-confidence diagnostic decisions.
Comparative Analysis of Methodological Performance
The confidence in taxonomic and diagnostic decisions is directly influenced by the choice of methodology and its management of error. The tables below synthesize experimental data comparing the performance of different approaches under varying conditions.
Table 1: Impact of Data Acquisition Error on Geometric Morphometric Classification (2D Landmark Data)
| Error Source | Impact on Landmark Precision | Impact on Species Classification | Recommended Mitigation Strategy |
|---|---|---|---|
| Imaging Device [57] | Moderate variation due to lens distortion and resolution. | Impacts statistical classification results. | Standardize imaging equipment across studies. |
| Specimen Presentation [57] | Substantial displacement of landmark loci when projecting 3D objects in 2D. | Greatest discrepancy in species classification results (e.g., predicted group memberships). | Standardize specimen orientations for 2D analyses. |
| Interobserver Variation [57] | Greatest discrepancies in landmark precision among error sources. | Impacts statistical classification; different observers can yield different group memberships. | Standardize landmark digitizers where possible. |
| Intraobserver Variation [57] | Notable variation in landmark placement across sessions. | Impacts statistical classification to some extent. | Conduct multiple digitization sessions to quantify error. |
| Composite Error [57] | Can explain >30% of total shape variation among datasets. | No two dataset replicates yielded identical predicted group memberships for fossils. | Mitigate all above errors collectively; report measurement error. |
Table 2: Performance Comparison of Classification and Analysis Methods
| Method | Application Context | Reported Performance/Accuracy | Key Factors Influencing Confidence |
|---|---|---|---|
| Linear Discriminant Analysis (LDA) [57] [92] | Species classification from 2D molar landmarks. | Classification accuracy sensitive to measurement error; no two error-impacted replicates gave same fossil PGM. | Standardization of data acquisition; use of leave-one-out cross-validation to reduce overfitting. |
| Computer Vision (Deep Learning) [18] | Carnivore agency identification from tooth marks. | 81% accuracy with Deep Convolutional Neural Networks (DCNN). | Superior to 2D GMM for complex outlines; requires well-preserved samples for reliable fossil application. |
| Geometric Morphometrics (2D Outline) [18] | Carnivore agency identification from tooth marks. | <40% accuracy; limited discriminant power for this application. | Outlined methods (Fourier, semi-landmarks) perform poorly with non-oval, allometrically-conditioned pits. |
| k-mer Based Classification (Kraken2) [91] | Metagenomic taxonomic classification. | Precision & F1 score improve with higher confidence scores (CS) on large databases. | Database size (comprehensive > compact) and CS setting (moderate CS ~0.2-0.4 optimizes accuracy). |
| Canonical Variates Analysis (CVA) [92] | Age classification from feather outlines. | Cross-validation rates optimized by reducing PCA axes before CVA to avoid overfitting. | Choice of dimensionality reduction approach is more critical than outline measurement method. |
Experimental Protocols for Establishing Confidence
Protocol 1: Quantifying Geometric Morphometric Measurement Error
This protocol, derived from Fox et al.'s study on vole molars, provides a framework for evaluating the impact of data acquisition error on subsequent classification analyses [57] [41].
- Specimen Imaging & Replication: Specimen images are acquired using different imaging devices (e.g., DSLR camera vs. digital microscope). To quantify presentation error, specimens are intentionally tilted along various axes and re-photographed, ensuring all landmark loci remain visible. This simulates orientation changes common when comparing in-situ and isolated elements (e.g., fossils) [57] [41].
- Landmark Digitization: The same set of specimen images is digitized by multiple observers. To assess interobserver error, each observer digitizes the entire image set independently. To assess intraobserver error, each observer re-digitizes the same image set in a separate session, with at least one week between iterations to minimize memory effects [57].
- Data Processing & Analysis: All landmark datasets are superimposed using Generalized Procrustes Analysis (GPA) to isolate shape variation. The resulting Procrustes coordinates are then used as predictor variables in a Linear Discriminant Analysis (LDA). The classification accuracy for specimens of known species affinity is evaluated using leave-one-out cross-validation. Finally, the trained LDA models are used to predict the group membership of unknown specimens (e.g., fossils), allowing for a direct comparison of how each source of error influences the diagnostic decision [57] [41].
Protocol 2: Validating Out-of-Sample Classification in Geometric Morphometrics
This protocol addresses the critical challenge of classifying new individuals not included in the original training sample, as encountered in the SAM Photo Diagnosis App for child nutritional status [2].
- Reference Sample Construction: A training sample is constructed with known group membership (e.g., Severe Acute Malnutrition vs. Optimal Nutritional Condition). The sample should be balanced for covariates like age and sex. Landmarks and semilandmarks are digitized on the biological structure of interest (e.g., a child's arm) [2].
- Template Selection for Registration: A key methodological step is selecting a template configuration from the reference sample to which the raw coordinates of new individuals will be registered. Different template choices (e.g., mean shape, a specific individual) must be evaluated for their effect on classification performance [2].
- Out-of-Sample Processing: For a new individual, raw landmark coordinates are obtained. These coordinates are then aligned to the chosen template, rather than undergoing a full GPA with the entire training sample. This process generates a set of registered shape coordinates for the new individual within the shape space of the reference sample [2].
- Classification and Validation: The pre-trained classifier (e.g., LDA) built from the reference sample is applied directly to the registered coordinates of the new individual. The performance of this entire pipeline, including template selection, is rigorously tested using validation datasets not used in training [2].
Workflow Visualization
The following diagrams illustrate the logical workflows for the two key experimental protocols described above, highlighting pathways to high and low-confidence outcomes.
Error Assessment in Morphometric Classification
Out-of-Sample Validation Pathway
The Scientist's Toolkit: Essential Research Reagents & Solutions
Confident taxonomic and diagnostic decisions rely on the appropriate selection of tools and methods. The following toolkit details key components for designing robust geometric morphometric and classification studies.
Table 3: Research Reagent Solutions for Confident Geometric Morphometric Classification
| Tool/Reagent | Function & Application | Considerations for Confidence |
|---|---|---|
| Generalized Procrustes Analysis (GPA) [57] [2] | Superimposes landmark configurations to remove effects of position, rotation, and scale, isolating pure shape. | Foundational step for all subsequent shape analysis. Assumes isometric scaling may not always be valid. |
| Linear Discriminant Analysis (LDA) [57] [2] [92] | A statistical classification method that finds linear combinations of variables to best separate groups. | Prone to overfitting; requires cross-validation. Performance is highly sensitive to measurement error. |
| Deep Convolutional Neural Networks (DCNN) [18] | A computer vision approach that automatically learns features from images for classification. | Can achieve high accuracy (>80%) on complex shapes where GMM fails; acts as a "black box." |
| Kraken2 & Comprehensive Databases (e.g., NT, GTDB) [91] | A k-mer-based taxonomic classifier for metagenomic sequences, paired with an expansive reference database. | A comprehensive database combined with a moderate confidence score (0.2-0.4) optimizes classification accuracy. |
| Cross-Validation (e.g., Leave-One-Out) [57] [92] | A model validation technique where portions of the data are iteratively held out as a test set. | Provides a nearly unbiased estimate of classifier performance on new data, preventing overconfidence. |
| Semi-Landmark & Outline Methods (e.g., Fourier) [18] [92] | Captures the shape of curves and outlines where discrete homologous landmarks are scarce. | Choice of method (semi-landmark vs. Fourier) is less critical than the subsequent dimensionality reduction. |
| Damaged/Pathologic Specimens [93] | The strategic inclusion of non-ideal specimens to bolster sample size in intraspecific studies. | Can strengthen statistical support for dominant shape predictors (e.g., allometry) but may obscure finer-scale signals. |
Conclusion
Validating geometric morphometric classifications on out-of-sample data is paramount for translating research findings into reliable clinical and biomedical applications. This synthesis underscores that successful out-of-sample prediction hinges on rigorous methodological choices—from template selection and error management to appropriate dimensionality reduction. While GM remains a potent tool for quantifying subtle shape variations, researchers must be aware of its limitations, particularly when compared to emerging deep learning approaches that show superior performance in some classification tasks. Future directions should focus on developing standardized protocols for out-of-sample registration, integrating 3D topographical information for enhanced complexity, and creating hybrid models that leverage the strengths of both GM and computer vision. By adopting these validated frameworks, researchers can significantly improve the generalizability and impact of morphometric analyses in drug development and personalized medicine.
References
- 1. Resolving sample identification bias in morphometrics ... [https://elifesciences.org/reviewed-preprints/94685v1/pdf]
- 2. Geometric morphometrics approach for classifying ... [https://www.nature.com/articles/s41598-025-85718-4]
- 3. Noctuidae) to support pest identification in invasive species ... [https://www.frontiersin.org/journals/insect-science/articles/10.3389/finsc.2025.1542467/full]
- 4. Geometric morphometric analysis of mandibular ... [https://www.sciencedirect.com/science/article/pii/S2212426825002246]
- 5. Evaluating statistical models for establishing morphometric ... [https://www.sciencedirect.com/science/article/abs/pii/S0305440322000681]
- 6. Sex classification accuracy through machine learning ... [https://link.springer.com/article/10.1186/s13104-025-07185-4]
- 7. Comparison of geometric morphometric outline methods in the ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC1592095/]
- 8. A Geometric Morphometrics Approach for Predicting Olfactory ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12565324/]
- 9. Procrustes analysis - Wikipedia [https://en.wikipedia.org/wiki/Procrustes_analysis]
- 10. Generalized Procrustes Analysis | Psychometrika | Cambridge Core [https://www.cambridge.org/core/journals/psychometrika/article/abs/generalized-procrustes-analysis/912F9374B1CB0294175A3B622C1D7696]
- 11. Geometric Morphometrics of Astragalus and Shape Variation ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12023762/]
- 12. procrustes - Procrustes analysis - MATLAB [https://www.mathworks.com/help/stats/procrustes.html]
- 13. A Comparison of Similarity Measures for Unsupervised ... [https://pubmed.ncbi.nlm.nih.gov/41060781/]
- 14. [1911.11431] Procrustes registration of two-dimensional statistical shape models without correspondences [https://arxiv.org/abs/1911.11431]
- 15. A Comparative Analysis of Artificial Intelligence Generated ... [https://www.sciencedirect.com/science/article/pii/S1073874625001409]
- 16. Size, shape, and form: concepts of allometry in geometric ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4896994/]
- 17. Methods for studying allometry in geometric morphometrics [https://link.springer.com/article/10.1007/s10682-022-10170-z]
- 18. Testing the reliability of geometric morphometric and ... [https://www.sciencedirect.com/science/article/pii/S2666033425000048]
- 19. When size makes a difference: allometry, life-history and ... [https://bmcecolevol.biomedcentral.com/articles/10.1186/1471-2148-7-20]
- 20. Geometric morphometrics approach for classifying ... [https://pubmed.ncbi.nlm.nih.gov/39890869/]
- 21. Multicollinearity Demystified: Choose the Right Features for ... [https://medium.com/@shridharpawar77/multicollinearity-demystified-choose-the-right-features-for-robust-ml-models-53fba3830d4f]
- 22. Multicollinearity [https://en.wikipedia.org/wiki/Multicollinearity]
- 23. Robust estimation methods for addressing multicollinearity ... [https://www.nature.com/articles/s41598-025-85553-7]
- 24. Impact of Sample Size and Its Estimation in Medical ... [https://www.sciencedirect.com/science/article/pii/S2773065425001397]
- 25. Sample size, power and effect size revisited: simplified and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7745163/]
- 26. The Importance and Effect of Sample Size [https://select-statistics.co.uk/blog/importance-effect-sample-size/]
- 27. How to Validate Your Market Research Sample [https://www.linkedin.com/advice/0/how-can-you-validate-representativeness-your-sample-rptvf]
- 28. Functional data geometric morphometrics with machine ... [https://www.nature.com/articles/s41598-024-66246-z]
- 29. MorphoJ [https://morphometrics.uk/MorphoJ_page.html]
- 30. an integrated software package for geometric morphometrics [https://pubmed.ncbi.nlm.nih.gov/21429143/]
- 31. 3D software [https://www.sbmorphometrics.org/soft-3d.html]
- 32. Geometric morphometrics approach for classifying children's ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11785739/]
- 33. Photogrammetry: Step-by-Step Tutorial and Software ... [https://formlabs.com/blog/photogrammetry-guide-and-software-comparison/?srsltid=AfmBOoosNm5P3IGk9p7GAMrpkP8tsMaGLOVCXvwQ-gyIRYCs151CZBfE]
- 34. Best practices for image acquisition and photogrammetry [https://support.pix4d.com/hc/best-practices-for-image-acquisition-and-photogrammetry]
- 35. Digital Image Correlation - The basics [https://eikosim.com/en/technical-articles/digital-image-correlation-the-basics/]
- 36. Automated landmarking via multiple templates - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC9714854/]
- 37. Assessing the application of landmark-free morphometrics to ... [https://bmcecolevol.biomedcentral.com/articles/10.1186/s12862-025-02377-9]
- 38. geometric morphometrics of head and thorax shapes in ... [https://www.frontiersin.org/journals/insect-science/articles/10.3389/finsc.2025.1558242/full]
- 39. Geometric Morphometrics and Machine Learning Models ... [https://www.mdpi.com/2076-3417/13/6/3967]
- 40. gpagen: Generalized Procrustes analysis of points, curves ... [https://rdrr.io/cran/geomorph/man/gpagen.html]
- 41. Data: Are geometric morphometric analyses replicable? ... [https://datadryad.org/dataset/doi:10.6071/M3KD40]
- 42. Cross-validation in PCA models with the element-wise k- ... [https://www.sciencedirect.com/science/article/abs/pii/S0169743913002335]
- 43. Cross Validation in Machine Learning [https://www.geeksforgeeks.org/machine-learning/cross-validation-machine-learning/]
- 44. Procrustes Cross-Validation of short datasets in PCA context [https://www.sciencedirect.com/science/article/abs/pii/S0039914021000254]
- 45. Comparison of geometric morphometric outline methods in the ... [https://digitalcommons.lmu.edu/bio_fac/62/]
- 46. Comparison of the impact of dimensionality reduction and ... [https://link.springer.com/article/10.1007/s10462-024-10904-1]
- 47. How to perform cross-validation for PCA to determine the ... [https://stats.stackexchange.com/questions/93845/how-to-perform-cross-validation-for-pca-to-determine-the-number-of-principal-com]
- 48. Geometric morphometrics and machine learning from three ... [https://www.frontiersin.org/journals/medicine/articles/10.3389/fmed.2023.1203023/full]
- 49. Comparison of indicators in a multi-country pooled analysis [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0219745]
- 50. Severe acute malnutrition | MSF Medical Guidelines [https://medicalguidelines.msf.org/en/viewport/CG/english/severe-acute-malnutrition-16689141.html]
- 51. Fighting Malnutrition with a Single Photo - Action contre la Faim [https://www.actioncontrelafaim.org/en/news/headlines/fighting-malnutrition-with-a-single-photo/]
- 52. Fighting Malnutrition with a Single Photo | Action Against Hunger [https://www.actionagainsthunger.org/story/fighting-malnutrition-with-a-single-photo/]
- 53. Comparison of Weight-for-Height Z-score and Mid-Upper ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6500831/]
- 54. Developmental performance of hospitalized severely acutely ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5704634/]
- 55. “Visiting scientist effect”? Exploring the impact of time‐lags in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12594189/]
- 56. The Measurement Error Elephant in the Room [https://pmc.ncbi.nlm.nih.gov/articles/PMC9005058/]
- 57. Are geometric morphometric analyses replicable? Evaluating ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7140992/]
- 58. Measurements and Error Analysis [https://www.webassign.net/question_assets/unccolphysmechl1/measurements/manual.html]
- 59. Comparing semi-landmarking approaches for analyzing ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12088985/]
- 60. A Practical Guide to Sliding and Surface Semilandmarks in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7780474/]
- 61. Deep Learning Outperforms Geometric Morphometrics for ... [https://archaeo.peercommunityin.org/PCIArchaeology/articles/rec?id=502]
- 62. Resolving sample identification bias in morphometrics ... [https://elifesciences.org/reviewed-preprints/94685v1]
- 63. Organizing Large Amounts of Data from Multiple Sources [https://calibrate-analytics.com/insights/2025/10/14/Organizing-Large-Amounts-of-Data-from-Multiple-Sources/]
- 64. The importance of choosing a proper validation strategy in ... [https://www.sciencedirect.com/science/article/pii/S0003267025012322]
- 65. Evaluating the sample size requirements of tree-based ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12308042/]
- 66. A Guide to Sample Sizes in UX Research — It's Not “Test ... [https://medium.com/design-bootcamp/a-guide-to-sample-sizes-in-ux-research-3379d61af381]
- 67. A Geometric Morphometric Study of Scapular Ontogeny in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12236271/]
- 68. Benchmarking of alignment-free sequence comparison methods [https://pmc.ncbi.nlm.nih.gov/articles/PMC6659240/]
- 69. Validation of wing geometric morphometrics in Chrysodeixis ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11811107/]
- 70. A comparative assessment and analysis of 20 ... [https://www.nature.com/articles/srep02619]
- 71. Training, Validation and Test Sets: How To Split Machine ... [https://kili-technology.com/blog/training-validation-and-test-sets-how-to-split-machine-learning-data]
- 72. What is the difference between test set and validation set? [https://stats.stackexchange.com/questions/19048/what-is-the-difference-between-test-set-and-validation-set]
- 73. Cross-validation (statistics) [https://en.wikipedia.org/wiki/Cross-validation_(statistics)]
- 74. Cross Validation. [https://medium.com/@Mustafa77/cross-validation-7c774fb59779]
- 75. Estimating Sample Size and Reducing Overfitting [https://pmc.ncbi.nlm.nih.gov/articles/PMC11005022/]
- 76. Practical Considerations and Applied Examples of Cross ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11041453/]
- 77. Geometric morphometric analysis of mandibular morphology ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12465032/]
- 78. The relative performance of geometric morphometrics and linear‐based methods in the taxonomic resolution of a mammalian species complex - PMC [https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10049884/]
- 79. Landmark-based geometric morphometrics: Influential ... [https://sciety-labs.elifesciences.org/articles/by?article_doi=10.1101/2025.07.14.664645]
- 80. A deep learning approach for morphological feature ... [https://www.nature.com/articles/s41540-023-00293-6]
- 81. Synthetically-trained neural networks for shape ... [https://www.sciencedirect.com/science/article/pii/S0022460X25003037]
- 82. Performance of Deep-Learning Solutions on Lung Nodule ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10532719/]
- 83. Comparative analysis of machine learning algorithms for multi ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9066923/]
- 84. Assessing the generalization capability of deep learning ... [https://www.sciencedirect.com/science/article/pii/S1569843222002424]
- 85. Benchmark-Ready 3D Anatomical Shape Classification [https://arxiv.org/abs/2511.01613]
- 86. Three-dimensional (3D) photogrammetric-based geometric ... [https://www.sciencedirect.com/science/article/abs/pii/S0044523125000506]
- 87. Geometric Morphometric Data Augmentation Using ... [https://www.mdpi.com/2076-3417/10/24/9133]
- 88. Geometric morphometrics on fossil shark teeth [https://palaeo-electronica.org/content/2025/5603-geometric-morphometrics-on-fossil-shark-teeth]
- 89. Morphometrics, 3D Imaging, and Craniofacial Development [https://pmc.ncbi.nlm.nih.gov/articles/PMC5299999/]
- 90. The problematic case of data leakage: A case for leave- ... [https://www.sciencedirect.com/science/article/pii/S0016706125000618]
- 91. Impact of database choice and confidence score on the ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11624175/]
- 92. Comparison of geometric morphometric outline methods in the ... [https://frontiersinzoology.biomedcentral.com/articles/10.1186/1742-9994-3-15]
- 93. Bolstering geometric morphometrics sample sizes with ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8128762/]