Generative AI for Geometric Morphometrics: Augmenting Biomedical Data to Overcome Sample Size Limitations
Geometric Morphometrics (GM) is a powerful multivariate tool for quantifying biological morphology, but its application in drug development and biomedical research is often constrained by small, incomplete, or imbalanced datasets.
Generative AI for Geometric Morphometrics: Augmenting Biomedical Data to Overcome Sample Size Limitations
Abstract
Geometric Morphometrics (GM) is a powerful multivariate tool for quantifying biological morphology, but its application in drug development and biomedical research is often constrained by small, incomplete, or imbalanced datasets. This article explores how generative computational learning algorithms, particularly Generative Adversarial Networks (GANs), can overcome these limitations. We provide a foundational understanding of GM's challenges, detail methodological implementations of generative models for data augmentation, address common troubleshooting and optimization strategies, and present a comparative analysis of validation techniques. By synthesizing the latest research, this review offers biomedical researchers a practical guide to leveraging synthetic data for enhanced predictive modeling, classification accuracy, and morphological analysis in clinical and preclinical development.
The Data Scarcity Challenge in Geometric Morphometrics and Biomedical Research
Geometric Morphometrics (GM) is a powerful visual statistical toolset that has revolutionized morphological research by enabling the rigorous analysis of form and shape using Cartesian geometric coordinates rather than traditional linear, areal, or volumetric variables [1] [2]. These methods employ two or three-dimensional homologous points of interest, known as landmarks, to quantify geometric variances among individuals [3]. In biomedical contexts, GM provides indispensable capabilities for modern medical diagnostics, individualized treatment, forensics, and the investigation of human morphological diversity [4]. When combined with virtual imaging, image manipulation, and morphometric methods, GM allows researchers to readily visualize, explore, and study digital anatomical objects, leading to new insights into organismal growth, development, and evolution [5].
The application of GM to biomedical data presents unique opportunities and challenges. While the foundations of GM were established approximately 30 years ago, the field has continually evolved through refinement and extension of its methodologies [4]. Modern GM now incorporates advanced computational approaches, including generative computational learning algorithms for data augmentation, which help overcome the common limitation of small sample sizes in specialized biomedical research domains [3] [6]. This protocol outlines the fundamental principles, practical applications, and emerging innovations in GM, with particular emphasis on its relevance to biomedical data analysis within a research framework investigating geometric morphometric data augmentation using generative algorithms.
Fundamental Concepts and Terminology
Landmarks: The Foundation of Geometric Morphometrics
Landmarks are biologically or geometrically corresponding point locations on the measured objects that form the basis of all GM analyses [4]. These landmarks are typically categorized into three primary types:
Table 1: Types of Landmarks in Geometric Morphometrics
| Landmark Type | Definition | Examples | Application Context |
|---|---|---|---|
| Type I | Anatomical points of biological significance | Sutures between bones, foramina | Biological and anatomical studies [3] |
| Type II | Points of mathematical significance | Points of maximal curvature or length | Generalized morphological analyses [3] |
| Type III | Constructed points located around outlines or in relation to other landmarks | Extremities of structures, outline points | Analyses requiring additional points beyond homologous landmarks [3] |
In addition to these traditional landmarks, modern GM incorporates semilandmarks for quantifying curves and surfaces. These semilandmarks "slide" over curves and surfaces in an attempt to reduce bending energy, thus enabling a more comprehensive capture of geometrical information [3] [4].
Shape, Form, and Size
In GM terminology, form refers to the geometric information independent of location and orientation, but not scale, while shape specifically denotes the geometric information independent of location, scale, and orientation [4]. The most common approach to standardizing shape data involves Generalized Procrustes Analysis (GPA), which translates all configurations to the same centroid, scales them to the same centroid size, and rotates them to minimize the summed squared differences between the configurations and their sample average [4]. This process effectively isolates biological variation by minimizing non-biological factors such as position, orientation, and size [7].
Core Methodological Workflow
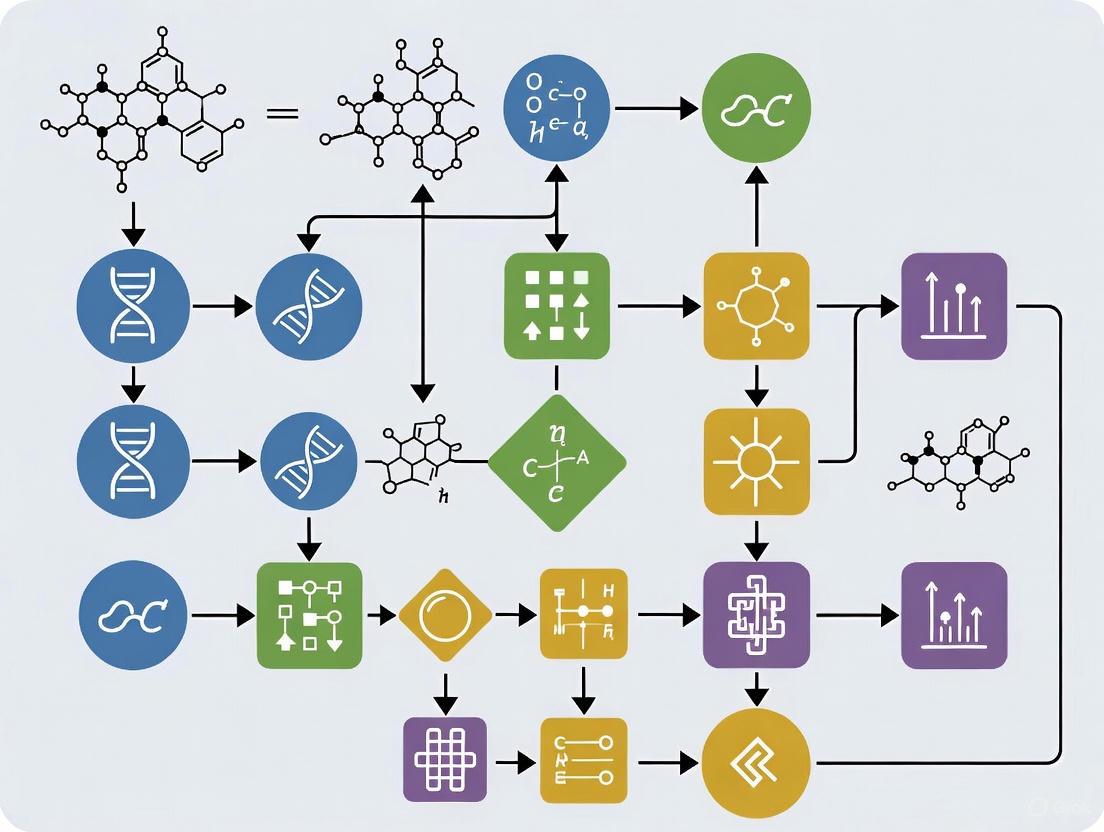
The standard GM analytical pipeline follows a systematic sequence of steps from data acquisition through statistical analysis and visualization. The following diagram illustrates this fundamental workflow:
Data Acquisition and Landmark Digitization
The initial phase involves collecting two-dimensional or three-dimensional coordinate data from biological specimens. In biomedical contexts, this typically utilizes various imaging modalities:
- Computed Tomography (CT): Provides detailed 3D internal structures; used in equine skull studies [8]
- Surface Scanning: Captures external morphology with high precision
- Virtual Imaging: Enables digital extraction and manipulation of anatomical structures [5]
Landmarks are then digitized onto these images using specialized software. The precision of landmark placement is critical, as error at this stage propagates through all subsequent analyses. For comparative studies, all specimens must share the same configuration of biologically homologous landmarks.
Procrustes Superimposition
Generalized Procrustes Analysis (GPA) standardizes landmark configurations by:
- Translating all configurations to the same centroid
- Scaling them to unit centroid size (the square root of the summed squared distances of landmarks from their centroid)
- Rotating them to minimize the sum of squared distances between corresponding landmarks [4]
This process effectively removes the effects of position, orientation, and scale, isolating pure shape information for subsequent analysis.
Statistical Analysis of Shape Data
Following Procrustes alignment, the resulting shape coordinates undergo multivariate statistical analysis:
- Principal Component Analysis (PCA): Examines major patterns of variation in the dataset by projecting specimens into a new shape space [3] [9]
- Multivariate Regression: Assesses how form is influenced by meaningful factors such as age, size, or environmental variables [5] [4]
- Partial Least Squares (PLS): Examines associations among structures or between shape and other variables [5] [4]
- Canonical Variate Analysis (CVA): Explores group differences, though this method is highly sensitive to small or imbalanced datasets [3]
These analyses generate shape variables that can be related to other biological factors of interest through appropriate statistical modeling.
Application Notes for Biomedical Research
Case Study: Ontogenetic Changes in Equine Skulls
A representative application of GM in biomedical research investigated ontogenetic changes in equine skulls using CT imaging [8]. This study exemplifies the standard GM protocol in practice:
Experimental Protocol:
- Sample Preparation: Twenty-nine normal equine heads were divided into three age groups (<5 years, 6-15 years, >16 years)
- CT Imaging: Heads were scanned using multislice CT scanners with slice thickness of 1.5mm or 1.25mm
- Image Processing: Bone window DICOM images were reconstructed into isosurfaces using Stratovan Checkpoint software
- Landmarking: Twenty-nine homologous landmarks were placed on each skull, including internal structures like the ventral and dorsal conchal bullae and tooth pulps
- Data Analysis: Landmark coordinates were processed through Procrustes fitting in MorphoJ software, followed by principal component analysis
Key Findings: The analysis revealed that allometric shape changes (shape variation correlated with size) accounted for 27% of variance along PC1, successfully distinguishing the youngest horses from the two older age groups. When allometric effects were removed, age groups could not be distinguished, indicating that size-related shape changes dominate ontogenetic variation in equine skulls [8].
Visualization and Interpretation
A critical strength of GM is the capacity to visualize statistical results as actual shapes or forms [4] [10]. Common visualization methods include:
- Deformation Grids: Thin-plate spline deformation grids show shape changes by analogy with physical surface deformation [9] [4]
- Vector Plots: Display relative landmark displacements between starting and target shapes [10]
- Shape Models: Generate theoretical shapes at specific positions within morphospaces (e.g., along principal components)
These visualization techniques transform abstract statistical outputs into biologically interpretable forms, facilitating insights into morphological patterns that might otherwise remain obscured in numerical results.
Data Augmentation Using Generative Algorithms
A significant challenge in GM, particularly for biomedical applications with rare specimens or clinical conditions, is limited sample size. Traditional resampling techniques like bootstrapping duplicate existing data but do not generate genuinely new information [3]. Emerging approaches using generative computational learning algorithms offer promising solutions.
Generative Adversarial Networks for GM
Generative Adversarial Networks (GANs) represent a cutting-edge approach for geometric morphometric data augmentation [3] [6]. The architecture and workflow of a typical GAN system for GM data augmentation can be visualized as follows:
Protocol for GAN-Based Data Augmentation [3]:
- Data Preparation: Format Procrustes-aligned landmark coordinates as training data
- Model Selection: Choose appropriate GAN architecture (standard GANs with different loss functions have outperformed conditional GANs in GM applications)
- Training: Simultaneously train generator and discriminator networks in adversarial fashion
- Synthetic Data Generation: Use trained generator to produce novel landmark configurations
- Validation: Apply robust statistical methods to verify synthetic data equivalence to original training data
Applications and Benefits: GAN-based augmentation helps address the "insufficiency of information density" common with small sample sizes, reducing overfitting in subsequent classification algorithms and predictive models [3]. Experimental results demonstrate that GANs can produce highly realistic synthetic data that is statistically equivalent to original training data, thereby enhancing the robustness of downstream statistical analyses [3] [6].
Landmark-Free Approaches
Recent methodological innovations include landmark-free approaches such as Deterministic Atlas Analysis (DAA), which uses Large Deformation Diffeomorphic Metric Mapping (LDDMM) to compare shapes without manual landmarking [7]. These methods:
- Generate control points automatically based on morphological features
- Compute deformation momenta to quantify shape differences
- Enable analysis of highly disparate forms with limited homology
- Are particularly valuable for large-scale studies across disparate taxa [7]
While these methods show promise for automating shape analysis, they currently face challenges in consistency with traditional landmark-based approaches, especially for certain taxonomic groups like Primates and Cetacea [7].
The Scientist's Toolkit
Table 2: Essential Research Reagents and Computational Tools for Geometric Morphometrics
| Tool Category | Specific Tools | Function | Application Context |
|---|---|---|---|
| Landmark Digitization Software | Stratovan Checkpoint, tps-series | Place and manage landmarks on 2D/3D images | Data acquisition phase [8] |
| Statistical Analysis Packages | MorphoJ, geomorph R package, PAST | Perform Procrustes analysis, PCA, and other multivariate statistics | Core analytical workflow [1] [8] |
| Programming Environments | R statistical computing, Wolfram Mathematica | Custom analysis scripting and implementation | Flexible, reproducible analyses [9] [1] |
| Generative Algorithms | Generative Adversarial Networks (GANs) | Synthetic data generation for small samples | Data augmentation for limited datasets [3] |
| Visualization Tools | Thin-plate spline, deformation grids | Visual representation of shape changes | Interpretation and communication of results [10] |
Geometric Morphometrics provides a powerful, visually intuitive framework for quantifying and analyzing form and shape in biomedical data. The core protocol—encompassing landmark digitization, Procrustes superimposition, multivariate statistical analysis, and shape visualization—offers a robust methodology for investigating morphological relationships across diverse biomedical contexts. The integration of emerging computational approaches, particularly generative adversarial networks for data augmentation and landmark-free analysis methods, addresses traditional limitations associated with small sample sizes and manual landmarking constraints. These advances position GM as an increasingly accessible and powerful tool for biomedical researchers investigating morphological variation in contexts ranging from clinical diagnostics to evolutionary studies. As these methodologies continue to evolve, they promise to enhance our understanding of form-function relationships in biological structures through rigorous quantitative analysis.
In scientific research, particularly in fields like paleontology, archaeology, and drug development, the quality and quantity of data directly determine the validity of statistical inferences. Geometric Morphometrics (GM) is a powerful multivariate statistical toolset for the analysis of morphology, with growing importance in biology, physical anthropology, and evolutionary studies [3]. These methods employ two or three-dimensional homologous points of interest, known as landmarks, to quantify geometric variances among individuals [3]. However, GM analyses are frequently compromised by incomplete fossil records, small sample sizes, and distorted preservation, creating a critical bottleneck that limits statistical power and reliability [3].
The statistical power of an analysis is the probability that it will detect an effect when there truly is one. Inadequate sample sizes directly diminish this power, increasing the risk of Type II errors (false negatives) and reducing the reliability of predictive models [3]. This application note examines how incomplete records and small samples impact statistical power in geometric morphometrics and details protocols for leveraging generative computational learning algorithms, particularly Generative Adversarial Networks (GANs), to overcome these limitations through data augmentation.
The Impact of Limited Data on Geometric Morphometric Analyses
Fundamental Challenges in Geometric Morphometrics
Geometric Morphometric practices involve projecting landmark configurations onto a common coordinate system through Generalized Procrustes Analysis (GPA), allowing for direct comparison of shapes by quantifying minute displacements of individual landmarks in space [3]. The resulting data is typically analyzed using multivariate statistical methods such as Principal Component Analysis (PCA) and Canonical Variant Analysis (CVA) [3].
The preservation rate of fossils often results in the loss of landmarks, significantly impeding these analyses [3]. For many species, particularly in paleoanthropology, obtaining large sample sizes is extraordinarily difficult, leading to substantial sample bias and reduced predictive capacity of discriminant models [3]. The impact of this bias is directly proportional to the number of variables included in multivariate analyses, creating a fundamental constraint on research progress [3].
Quantitative Impacts of Sample Size Limitations
Table 1: Statistical Consequences of Small Sample Sizes in Geometric Morphometrics
| Challenge | Impact on Analysis | Resulting Statistical Issue |
|---|---|---|
| Incomplete Fossil Records | Loss of landmarks and morphological information [3] | Reduced variable completeness, biased shape representation |
| Small Sample Sizes | Insufficient information density for population representation [3] | Overfitting, reduced model generalizability |
| Class Imbalance | Underrepresentation of certain morphological variants or species [3] | Biased classifiers, inaccurate group discrimination |
| High-Dimensional Data | Increased variables without corresponding sample increases [3] | Exponentiated bias impact, reduced discriminant power |
Generative Algorithms for Data Augmentation in Geometric Morphometrics
Generative Adversarial Networks (GANs) Fundamentals
Generative Adversarial Networks (GANs) represent a transformative approach to addressing data scarcity challenges in morphological analyses [3] [11]. A GAN consists of two neural networks trained simultaneously: a Generator that produces synthetic data, and a Discriminator that evaluates this data for authenticity [3]. The two models engage in adversarial competition, with the generator continuously improving its output to fool the discriminator, resulting in a network capable of producing highly realistic synthetic data statistically equivalent to original training data [3].
Recent advancements have led to more sophisticated implementations, such as adaptive identity-regularized GANs that integrate identity blocks to preserve critical species-specific features during generation, coupled with species-specific loss functions designed around distinctive morphological characteristics [11]. These biologically-informed approaches ensure that synthetic data generation respects phylogenetic relationships and morphological boundaries between distinct species [11].
Workflow for Geometric Morphometric Data Augmentation
Diagram Title: GM Data Augmentation with GANs
Experimental Protocols for Geometric Morphometric Data Augmentation
Protocol 1: Standard GAN Implementation for Landmark Data
Purpose: To generate synthetic geometric morphometric data using standard Generative Adversarial Networks to augment small sample sizes.
Materials and Equipment:
- Landmark coordinate data from original specimens
- Python programming environment with TensorFlow/PyTorch
- High-performance computing resources with GPU acceleration
Procedure:
- Data Preprocessing:
- Collect landmark coordinate data from all available specimens
- Perform Generalized Procrustes Analysis to remove non-shape variation (position, orientation, scale)
- Export Procrustes coordinates as training data
GAN Architecture Configuration:
- Implement generator network with 3 fully connected hidden layers (512, 256, 512 neurons)
- Implement discriminator network with 3 fully connected hidden layers (256, 128, 64 neurons)
- Use LeakyReLU activation functions in both networks
- Configure Adam optimizers for both networks with learning rate of 0.0002
Model Training:
- Train generator and discriminator simultaneously for 10,000 epochs
- Use minibatch training with batch size of 32
- Monitor training stability to prevent mode collapse
- Save model checkpoints every 500 epochs
Synthetic Data Generation:
- Use trained generator to produce synthetic landmark data
- Generate number of synthetic specimens required to achieve target sample size
- Validate synthetic data quality through statistical comparison with original data
Statistical Validation:
- Perform Multivariate Analysis of Variance (MANOVA) to test significance between original and synthetic data distributions
- Use Principal Component Analysis to visualize overlap in morphospace
- Verify that synthetic data falls within biologically plausible range
Troubleshooting:
- For training instability: Reduce learning rate or implement gradient penalty
- For mode collapse: Add noise to discriminator inputs or use multiple discriminators
- For unrealistic outputs: Increase training epochs or adjust network architecture
Protocol 2: Adaptive Identity-Regularized GAN for Morphologically Complex Species
Purpose: To generate high-quality synthetic morphometric data for morphologically complex species while preserving essential diagnostic features.
Materials and Equipment:
- Landmark data with species identification labels
- Taxonomic reference database with diagnostic characteristics
- Python environment with custom GAN implementation capabilities
Procedure:
- Species-Specific Feature Identification:
- Consult taxonomic literature to identify species-invariant morphological features
- Label landmark constellations corresponding to diagnostic characteristics
- Establish morphological constraints for each species
Adaptive Identity Block Implementation:
- Implement identity blocks that learn to preserve species-invariant features
- Configure adaptive mechanism to modulate behavior based on input taxonomic characteristics
- Connect identity blocks in parallel with standard generator layers
Species-Specific Loss Function Formulation:
- Develop multi-component loss function incorporating:
- Morphological consistency terms
- Phylogenetic relationship constraints
- Feature preservation objectives
- Weight loss components to balance diversity and biological accuracy
- Develop multi-component loss function incorporating:
Two-Phase Training Methodology:
- Phase 1: Train identity mappings to establish stable feature preservation
- Phase 2: Introduce controlled morphological variations for augmentation
- Monitor both discriminator loss and species-specific loss components
Biological Validation:
- Engage domain experts to evaluate biological authenticity of synthetic specimens
- Calculate biological validation score through expert assessment
- Verify maintenance of diagnostic features in synthetic specimens
Troubleshooting:
- For blurred feature preservation: Increase weight of species-specific loss component
- For insufficient diversity: Adjust balance between identity and variation components
- For taxonomic inaccuracy: Review diagnostic feature identification and constraints
Research Reagent Solutions for Geometric Morphometric Data Augmentation
Table 2: Essential Research Tools for Geometric Morphometric Data Augmentation
| Research Reagent/Tool | Function | Application Example |
|---|---|---|
| Generative Adversarial Networks (GANs) | Generate synthetic landmark data statistically equivalent to original specimens [3] | Augmenting small fossil datasets for improved statistical power |
| Adaptive Identity Blocks | Preserve species-specific morphological features during generation [11] | Maintaining diagnostic characteristics in synthetic specimens of closely related species |
| Species-Specific Loss Functions | Incorporate taxonomic constraints to ensure biological plausibility [11] | Generating morphologically accurate data for rare or endangered species |
| Generalized Procrustes Analysis | Normalize landmark configurations to remove non-shape variation [3] | Preprocessing step before generative augmentation |
| Principal Component Analysis | Visualize and validate synthetic data distribution in morphospace [3] | Quality assessment of generated data |
Implementation Considerations and Limitations
While generative approaches present a valuable means of augmenting geometric morphometric datasets, several limitations must be considered. Generative Adversarial Networks are not the solution to all sample-size related issues, and excessive transformations can potentially generate unrealistic data if not properly constrained [3] [12]. Additionally, these methods require substantial computational resources and expertise to implement effectively [12].
The effectiveness of data augmentation in geometric morphometrics has been demonstrated across multiple applications. In one study, GANs using different loss functions produced multidimensional synthetic data significantly equivalent to the original training data, though Conditional Generative Adversarial Networks were notably less successful [3] [13]. Another investigation implementing adaptive identity-regularized GANs for fish classification achieved 95.1% classification accuracy, representing a 9.7% improvement over baseline methods and 6.7% improvement over traditional augmentation approaches [11].
For optimal results, generative data augmentation should be combined with other preprocessing steps and traditional statistical techniques. This integrated approach can help overcome the persistent challenges posed by incomplete records and small samples, ultimately enhancing the statistical power and reliability of geometric morphometric analyses across biological, anthropological, and pharmaceutical research domains.
Data augmentation represents a cornerstone of modern data science, providing critical methodologies for enhancing the robustness and generalizability of statistical and machine learning models. In fields characterized by data scarcity, such as geometric morphometrics (GM), these techniques are particularly invaluable [3]. Geometric morphometrics, which involves the multivariate statistical analysis of form based on Cartesian landmark coordinates, frequently grapples with limited sample sizes due to factors inherent to its common applications—notably the incomplete fossil record in paleontology or the rarity of specific biological specimens [3] [14]. This data scarcity impedes complex statistical analyses, including classification tasks and predictive modeling, often leading to overfitting and reduced model performance [3].
The evolution of data augmentation strategies has transitioned from traditional resampling techniques to advanced generative artificial intelligence (AI). Traditional methods, such as bootstrapping, artificially inflate datasets by creating copies or simple variations of existing data but fail to generate novel data points that explore the "uncharted territory" between existing samples [3]. In contrast, modern generative AI, particularly Generative Adversarial Networks (GANs), can learn the underlying probability distribution of the training data and produce highly realistic, synthetic data that significantly enhance the diversity and representativeness of datasets [3] [11] [15]. This evolution is critically important for geometric morphometrics, where generative models can create new, biologically plausible landmark configurations, thereby overcoming historical limitations and enabling more powerful morphological analyses [3].
The Limitation of Traditional Resampling Methods
Traditional resampling methods have been widely used to address issues of small sample sizes and class imbalance. Techniques such as bootstrapping (resampling with replacement) and permutation tests have been standards in statistical practice for decades, offering robustness in parameter estimation and hypothesis testing [3]. Their primary strength lies in their ability to provide inferential power about a population from a single sample without stringent distributional assumptions.
However, these methods possess a fundamental limitation: they do not create new information. Bootstrapping, for instance, generates new datasets by duplicating existing data points, thereby inflating the sample size without increasing the information density about the population's true distribution [3]. This often results in models that are prone to overfitting, as the spaces between genuine data points remain unexplored. For geometric morphometric analyses, which rely on capturing the full spectrum of morphological variation in a multidimensional feature space, this insufficiency can be particularly detrimental, limiting the predictive accuracy and generalizability of subsequent models [3].
The Rise of Generative AI in Data Augmentation
Generative AI has emerged as a transformative solution to the limitations of traditional resampling. Unlike methods that merely duplicate data, generative models learn to approximate the complex, high-dimensional probability distributions of real datasets and can then sample from this learned distribution to create novel, synthetic data [16] [15].
Core Generative Models
The landscape of generative AI for data augmentation is diverse, with several model architectures showing significant promise:
- Generative Adversarial Networks (GANs): Introduced in 2014, GANs consist of two neural networks—a Generator and a Discriminator—trained simultaneously in a competitive framework [3] [16]. The generator creates synthetic data, while the discriminator evaluates its authenticity against real training data. This adversarial process continues until the generator produces data indistinguishable from the original [3]. GANs have been successfully applied to generate synthetic geometric morphometric data, with studies showing that they can produce multidimensional data statistically equivalent to the original training set [3].
- Gaussian Mixture Models (GMM): As a probabilistic model, GMM assumes data is generated from a mixture of a finite number of Gaussian distributions. It is a robust, statistically-driven method for generating synthetic data, particularly effective for filling gaps in data distributions [17]. For example, in a study predicting soil organic carbon, augmenting the calibration set with 44 GMM-generated samples improved the Random Forest model's performance, increasing the R² value from 0.71 to 0.77 and reducing the RMSE [17].
- Diffeomorphic Transforms: This non-generative AI data augmentation method performs diffeomorphic (smooth and invertible) transformations between two samples from the same class [18]. It is particularly effective for objects with high variability in shape and texture, such as biological specimens. By mimicking natural shape changes (e.g., those experienced in a diatom's life cycle), it generates new, realistic training samples that have been shown to improve classification accuracy beyond standard augmentation techniques [18].
Quantitative Comparison of Augmentation Strategies
The table below summarizes the performance of various data augmentation strategies as documented in recent scientific literature.
Table 1: Performance Comparison of Data Augmentation Strategies
| Augmentation Method | Application Context | Model Performance Before Augmentation | Model Performance After Augmentation | Key Metric |
|---|---|---|---|---|
| Gaussian Mixture Model (GMM) | Soil Organic Carbon Prediction [17] | R² = 0.71, RMSE = 0.93% | R² = 0.77, RMSE = 0.84% | Validation Accuracy |
| Adaptive Identity-Regularized GAN | Fish Species Classification [11] | 85.4% Accuracy (Baseline) | 95.1% ± 1.0% Accuracy | Classification Accuracy |
| Diffeomorphic Transforms | Diatom Classification [18] | Baseline Accuracy (Not Specified) | +0.47% Accuracy Improvement | Increase in Accuracy |
| GANs & GMM Combination | Geometric Morphometrics [3] | N/A (Theoretical) | Produced statistically equivalent synthetic data | Statistical Equivalence |
Application Notes & Protocols for Geometric Morphometrics
Integrating generative data augmentation into a geometric morphometrics workflow requires a structured pipeline, from data preparation to model validation. The following protocol outlines the key stages for a successful implementation.
Experimental Protocol: Data Augmentation for GM Using GANs
1. Objective: To augment a limited set of landmark configurations using a Generative Adversarial Network to enhance the performance and robustness of downstream statistical analyses (e.g., classification, PCA).
2. Materials and Data Pre-processing:
- Input Data: A matrix of Procrustes-aligned landmark coordinates [3]. The data should be derived from a Generalized Procrustes Analysis (GPA), which removes the effects of translation, rotation, and scale [3].
- Data Cleaning: Address any missing landmarks using appropriate imputation techniques if necessary [3].
- Feature Space Construction (Optional): For very high-dimensional data, a preliminary dimensionality reduction via Principal Components Analysis (PCA) may be performed. The GAN is then trained on the principal component scores, which represent the major axes of shape variation [3].
3. GAN Architecture and Training:
- Model Selection: Standard GAN architectures are often sufficient, though more advanced variants like Wasserstein GANs can offer improved training stability [3].
- Generator Network: A neural network that takes a vector of random noise from a latent space (e.g., 100 dimensions) and outputs a synthetic data point with the same dimensionality as a real landmark configuration (or PC score vector).
- Discriminator Network: A binary classifier network that distinguishes between "real" (training data) and "fake" (generator output) samples.
- Training Loop: The model is trained in two alternating steps:
- Train Discriminator: Update the discriminator with a batch of real and a batch of generated data.
- Train Generator: Update the generator to produce data that "fools" the discriminator.
- Conditional GANs (cGANs): For labeled data (e.g., specimens from different species), a cGAN can be used. The class label is provided as an additional input to both the generator and discriminator, allowing for the targeted generation of synthetic data for specific groups [3].
4. Validation and Quality Control:
- Statistical Validation: The synthetic data must be validated to ensure it is representative of the true morphological space. This can be achieved using:
- Downstream Task Evaluation: The ultimate validation is performance improvement in the target application. Compare the performance of a classifier (e.g., SVM, Random Forest) or a predictive model trained on the original data versus one trained on the augmented (original + synthetic) data [3] [11].
Workflow Visualization
The following diagram illustrates the end-to-end protocol for data augmentation in geometric morphometrics using a Generative Adversarial Network.
The Scientist's Toolkit: Key Research Reagents and Materials
Table 2: Essential Materials and Computational Tools for GM Data Augmentation
| Item / Reagent | Function / Application | Example / Note |
|---|---|---|
| Landmark Digitization Software | Precisely capture 2D/3D coordinates of homologous anatomical points from specimens or images. | Examples include MorphoJ, tpsDig2. Essential for building the initial raw dataset [3]. |
| Procrustes Analysis Software | Normalize landmark configurations by scaling, translating, and rotating them into a common coordinate system. | Implemented in R (geomorph package) or standalone software. Critical pre-processing step [3]. |
| Programming Framework | Provides the environment to build, train, and validate generative models. | Python with TensorFlow/PyTorch, or R. Necessary for implementing GANs and other AI models [3] [17]. |
| High-Performance Computing (HPC) | Accelerates the computationally intensive training process of deep learning models like GANs. | GPU clusters are often essential for training on large or high-dimensional morphometric datasets [11]. |
| Generative Model Architecture | The core algorithm for generating synthetic landmark data. | GANs, cGANs, or Gaussian Mixture Models (GMM). Choice depends on data structure and goals [3] [17]. |
| Statistical Validation Suite | Tools to test the quality and fidelity of the generated synthetic data. | Multivariate statistical tests (e.g., PERMANOVA) in R or Python; visualization in morphospace [3]. |
Challenges and Future Directions
Despite their promise, generative AI methods face several challenges. Model instability, particularly in GAN training, can lead to mode collapse where the generator produces limited varieties of samples [11]. Ensuring the biological plausibility of generated data is paramount; synthetic landmark configurations must represent anatomically possible forms [3] [11]. This has led to the development of biologically-informed GANs that incorporate taxonomic constraints and species-specific loss functions to maintain morphological authenticity [11].
Future research will likely focus on leveraging 3D geometric morphometric data more comprehensively, as current 2D analyses have shown limited discriminant power [14]. Furthermore, the integration of generative AI into broader scientific workflows, such as drug development—where it can help generate synthetic data for pharmacokinetic modeling or clinical trial simulation—showcases its expanding role beyond basic science [19]. As these technologies mature, they will become an indispensable tool in the scientist's arsenal, turning data scarcity from a roadblock into a surmountable challenge.
Generative Adversarial Networks (GANs) represent a groundbreaking machine learning framework introduced by Ian Goodfellow in 2014 that has transformed the field of generative modeling [20]. This innovative approach operates within an unsupervised learning framework by utilizing deep learning techniques where two neural networks, a generator and a discriminator, work in direct opposition to each other [20]. The fundamental objective of a GAN is to generate realistic synthetic data by learning and replicating the underlying patterns from existing training datasets. The capacity of GANs to produce highly realistic data has positioned them as powerful tools across numerous research domains, including geometric morphometrics where they address critical challenges related to sample size limitations and data incompleteness commonly encountered in fossil records [3].
The application of GANs to geometric morphometrics presents a particularly promising solution to one of the field's most persistent challenges: the incompleteness and distortion of the fossil record, which often conditions the type of knowledge that can be extracted from morphological analyses [3]. Traditional statistical methods in geometric morphometrics, including Canonical Variant Analyses (CVA), are highly sensitive to small or imbalanced datasets, with the impact of bias being directly proportional to the number of variables included in multivariate analyses [3]. GANs offer a sophisticated approach to overcoming these limitations through the generation of synthetic landmark data that expands limited datasets while preserving the essential morphological variances necessary for robust statistical analysis.
Fundamental GAN Architecture and Dynamics
Core Components and Adversarial Process
The GAN architecture consists of two deep neural networks engaged in a competitive minimax game [20]. The generator network takes random noise as input and transforms it into synthetic data that aims to mimic the real data from the training set. Simultaneously, the discriminator network functions as an adversarial evaluator, analyzing both real samples from the training dataset and synthetic samples produced by the generator, then assigning a probability score that each is real [20]. This dynamic creates a continuous feedback loop where the generator strives to produce increasingly realistic data to deceive the discriminator, while the discriminator concurrently refines its ability to distinguish real from synthetic samples.
The training process involves backpropagation to optimize both networks, where the gradient of the loss function is calculated according to each network's parameters, and these parameters are adjusted to minimize their respective losses [20]. The generator utilizes feedback from the discriminator to improve its synthetic data generation capabilities. This adversarial process continues until equilibrium is reached, ideally resulting in a generator capable of producing highly realistic data that the discriminator cannot distinguish from genuine samples, at which point the discriminator would assign a probability of 0.5 to all samples [20].
GAN Dynamics Workflow
The following diagram illustrates the fundamental adversarial process between the generator and discriminator:
GAN Variants and Architectural Evolution
Key GAN Architectures for Scientific Research
The fundamental GAN architecture has evolved into numerous specialized variants, each designed to address specific challenges or application requirements. The table below summarizes the key GAN architectures relevant to geometric morphometrics and scientific research:
Table 1: Key GAN Architectures for Geometric Morphometrics and Scientific Research
| GAN Variant | Key Features | Advantages | Relevant Applications |
|---|---|---|---|
| Vanilla GAN | Basic generator-discriminator architecture using multilayer perceptrons (MLPs) [20] | Simple implementation; foundational understanding [20] | Prototyping; educational purposes |
| Conditional GAN (cGAN) | Incorporates additional labels or conditions for both generator and discriminator [20] | Enables targeted generation with specific characteristics [20] | Category-specific morphological generation |
| Deep Convolutional GAN (DCGAN) | Utilizes convolutional neural networks (CNNs) for both generator and discriminator [20] | Improved performance for image-like data; stable training [20] | 2D and 3D morphological pattern generation |
| Wasserstein GAN (WGAN) | Employs Wasserstein distance metric with gradient penalty [21] | Addresses training instability; more consistent convergence [21] | High-dimensional morphometric data |
| CycleGAN | Uses cyclic consistency with two generators and two discriminators [20] | Enables domain translation without paired training data [20] | Cross-domain morphological transformation |
Performance Comparison of GAN Architectures
Different GAN architectures demonstrate varying performance characteristics across evaluation metrics. The following table quantitatively compares their performance in key areas relevant to geometric morphometrics:
Table 2: Performance Comparison of GAN Architectures in Scientific Applications
| GAN Architecture | Training Stability | Sample Quality | Mode Coverage | Computational Efficiency | Recommended Use Cases |
|---|---|---|---|---|---|
| Vanilla GAN | Low [20] | Moderate [20] | Limited [20] | High [20] | Basic synthetic data generation |
| DCGAN | Moderate [20] | High [20] | Moderate [20] | Moderate [20] | Image-based morphometric data |
| WGAN-GP | High [21] | High [21] | High [21] | Low [21] | High-fidelity landmark generation |
| Conditional GAN | Moderate [20] | High [20] | High [20] | Moderate [20] | Category-specific augmentation |
| CycleGAN | Moderate [20] | Moderate [20] | Moderate [20] | Low [20] | Domain adaptation tasks |
Application Notes for Geometric Morphometrics
GANs for Morphometric Data Augmentation
In geometric morphometrics, GANs present a valuable solution for addressing the critical issue of sample size insufficiency that frequently impedes robust statistical analyses [3]. The field relies on the analysis of morphological variations using homologous points of interest known as landmarks, which are often scarce in paleontological and archaeological contexts due to fossil record incompleteness [3]. Traditional resampling techniques like bootstrapping merely duplicate existing data without creating new information, whereas GANs generate genuinely novel synthetic data that expands the information density of the dataset, thereby enabling more reliable statistical inferences and reducing overfitting in predictive models [3].
Experimental applications demonstrate that GANs can produce highly realistic synthetic morphometric data that is statistically equivalent to original training data, effectively overcoming limitations imposed by small sample sizes [3]. Different GAN architectures have been tested with geometric morphometric datasets, with standard GANs using various loss functions proving particularly successful in generating multidimensional synthetic data that preserves the essential morphological variances of the original specimens [3]. This capability is crucial for enhancing the reliability of statistical tests such as Canonical Variant Analyses (CVA) that are highly sensitive to dataset size and balance [3].
Comparative Analysis of Data Augmentation Methods
The table below compares traditional data augmentation approaches with GAN-based methods specifically for geometric morphometric applications:
Table 3: Data Augmentation Methods Comparison for Geometric Morphometrics
| Method | Principle | Advantages | Limitations | Effectiveness for GM |
|---|---|---|---|---|
| Bootstrapping | Resampling with replacement [3] | Simple implementation; preserves distribution [3] | Does not create new information; limited variance [3] | Low to moderate |
| Traditional Synthetic Data | Parametric distribution modeling | Controlled data generation | Relies on distribution assumptions | Moderate |
| GAN-Based Augmentation | Adversarial learning of data distribution [3] | Creates meaningful new data; reduces overfitting [3] | Computational intensity; training instability [3] | High |
| Conditional GAN | Label-guided adversarial generation [20] | Targeted category-specific generation [20] | Requires labeled data; complex architecture [20] | Very high |
Experimental Protocols for Geometric Morphometric Applications
Protocol 1: Basic GAN Implementation for Landmark Data Augmentation
Objective: To implement a GAN framework for generating synthetic landmark data to augment limited geometric morphometric datasets.
Materials and Requirements:
- Software Environment: Python with TensorFlow/PyTorch, NumPy, SciPy
- Computational Resources: GPU with minimum 8GB VRAM recommended
- Input Data: Procrustes-aligned landmark coordinates in matrix form
Procedure:
- Data Preprocessing:
- Perform Generalized Procrustes Analysis (GPA) to align all landmark configurations [3]
- Convert landmark coordinates to vector format preserving specimen identity
- Normalize data to zero mean and unit variance
Generator Network Configuration:
- Implement a multilayer perceptron (MLP) with 3-5 hidden layers
- Use leaky ReLU activation functions (α=0.2) in hidden layers
- Apply tanh activation in output layer scaled to data range
- Input: 100-dimensional random noise vector ~N(0,1)
Discriminator Network Configuration:
- Implement MLP with 3-5 hidden layers (similar to generator)
- Use leaky ReLU activation functions (α=0.2) in hidden layers
- Apply sigmoid activation in output layer for binary classification
- Input: Landmark coordinate vector (real or synthetic)
Training Protocol:
- Initialize generator and discriminator with He normal initialization
- Set Adam optimizer with learning rate 0.0002, β₁=0.5
- Train for 10,000-50,000 epochs with batch size 32-128
- Alternate between discriminator and generator updates (1:1 ratio)
- Monitor loss functions and sample quality periodically
Synthetic Data Generation:
- Use trained generator to produce synthetic landmark data
- Apply inverse transformation to restore original coordinate scale
- Validate synthetic data quality through Principal Components Analysis (PCA)
Validation Metrics:
- Average Coverage Error (ACE): For assessing distribution similarity [22]
- Procrustes Distance: Measure shape differences between real and synthetic specimens
- PCA Overlap: Compare variance explained and component loading patterns
Protocol 2: Conditional GAN for Category-Specific Morphometric Generation
Objective: To generate synthetic landmark data for specific morphological categories or taxonomic groups using conditional GANs.
Materials and Requirements:
- Software Environment: Python with deep learning frameworks supporting conditional GANs
- Input Data: Labeled landmark data with categorical variables (e.g., species, treatment groups)
- Computational Resources: GPU with minimum 12GB VRAM
Procedure:
- Data Preparation:
- Perform standard Procrustes alignment [3]
- Encode categorical variables as one-hot vectors
- Concatenate landmark coordinates with condition vectors
Conditional Generator Architecture:
- Implement MLP with conditional input concatenation at input and hidden layers
- Use conditional batch normalization for improved performance
- Input: Concatenation of noise vector and condition vector
Conditional Discriminator Architecture:
- Implement MLP with conditional input concatenation at input layer
- Use projection discriminator for conditional probability estimation
- Input: Concatenation of landmark data and condition vector
Training Protocol:
- Use Wasserstein loss with gradient penalty (λ=10) for training stability [21]
- Set learning rate 0.0001 with RMSprop optimizer
- Train with 5:1 discriminator-to-generator update ratio initially
- Apply label smoothing (0.9 for real, 0.1 for fake) to prevent discriminator overfitting
- Monitor category-specific generation quality
Quality Assessment:
- Perform discriminant analysis to verify category separation in synthetic data
- Compare within-group and between-group variances with original data
- Assess morphological plausibility through expert evaluation
Workflow for Geometric Morphometric Data Augmentation
The following diagram illustrates the complete experimental workflow for geometric morphometric data augmentation using GANs:
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 4: Essential Research Reagents and Computational Tools for GAN Implementation in Geometric Morphometrics
| Tool/Category | Specific Examples | Function/Purpose | Implementation Notes |
|---|---|---|---|
| Deep Learning Frameworks | TensorFlow, PyTorch, Keras | GAN implementation and training [20] | PyTorch recommended for research flexibility |
| Geometric Morphometrics Software | MorphoJ, PAST, R (geomorph) | Landmark processing and analysis [3] | MorphoJ for GUI-based analysis |
| Data Visualization | ggplot2, Matplotlib, Plotly | Results visualization and quality assessment | Essential for synthetic data validation |
| GAN Architecture Variants | DCGAN, WGAN-GP, Conditional GAN | Specialized generation tasks [20] [21] | WGAN-GP for training stability [21] |
| Evaluation Metrics | Average Coverage Error (ACE), FID, PCA | Synthetic data quality assessment [22] | ACE particularly suited for time-series morphological data [22] |
| Computational Hardware | GPU clusters, Cloud computing (AWS, GCP) | Accelerate GAN training process | Minimum 8GB GPU RAM recommended |
Challenges and Mitigation Strategies
Technical Limitations and Solutions
Despite their promising applications in geometric morphometrics, GANs present several significant challenges that researchers must address. Training instability remains a fundamental issue, often manifesting as mode collapse where the generator produces limited varieties of samples [22] [20]. This problem can be mitigated through architectural improvements such as Wasserstein GAN with gradient penalty (WGAN-GP) which provides more stable training dynamics and better convergence [21]. Additionally, vanishing gradients during training can impede network learning, particularly in the early stages when the discriminator becomes too proficient at distinguishing real from synthetic data [22].
For geometric morphometric applications specifically, the high dimensionality of landmark data presents unique challenges. Each landmark consists of multiple coordinates (2D or 3D), and complete configurations may involve dozens of landmarks, resulting in complex high-dimensional spaces. Recent approaches have successfully addressed this through dimensionality reduction techniques such as Principal Components Analysis (PCA) applied prior to GAN training, allowing the model to learn the essential shape parameters rather than raw coordinate data [3]. This approach aligns with standard geometric morphometric practice where shape space is typically represented by principal components.
Validation and Evaluation Framework
Robust validation of synthetic morphometric data requires multiple complementary approaches. Statistical equivalence testing should demonstrate that synthetic data preserves the multivariate distributional properties of original data [3]. Domain expert evaluation is crucial for assessing the morphological plausibility of generated specimens, particularly for paleontological applications where functional constraints must be maintained. Downstream task performance should be evaluated by comparing analytical results (e.g., classification accuracy, allometric patterns) between original and augmented datasets.
The Average Coverage Error (ACE) metric has been proposed as particularly suitable for evaluating GAN performance with time-series and morphological data, as it assesses how well the generated data covers the true distribution of the original dataset [22]. This metric can be adapted for geometric morphometrics by treating landmark configurations as multivariate observations and evaluating their coverage in the shape space.
Generative Adversarial Networks represent a transformative methodology for addressing fundamental challenges in geometric morphometrics, particularly the limitations imposed by incomplete fossil records and small sample sizes. The adversarial dynamics between generator and discriminator networks enable the creation of scientifically valid synthetic morphometric data that expands limited datasets while preserving essential morphological variances. The experimental protocols outlined provide researchers with practical frameworks for implementing GAN-based data augmentation in geometric morphometric studies.
Future research directions include the development of three-dimensional GAN architectures specifically designed for landmark data, integration with geometric deep learning approaches that respect the non-Euclidean nature of shape space, and conditional generation frameworks that can incorporate taxonomic, temporal, or environmental covariates. As these methodologies mature, GANs are poised to become indispensable tools in the geometric morphometrician's toolkit, enabling more robust statistical analyses and deeper insights into morphological evolution despite the inherent limitations of the fossil record.
Implementing Generative Algorithms for High-Fidelity Morphometric Data Augmentation
Generative Adversarial Networks (GANs) have revolutionized data augmentation across scientific domains, particularly for fields like geometric morphometrics and drug discovery where labeled data are scarce. These frameworks learn to generate synthetic data that closely mirrors the distribution of real datasets, thereby addressing fundamental challenges of sample size limitations and class imbalance. This document provides a detailed technical examination of three critical GAN architectures—Standard GANs, Conditional GANs (cGANs), and the novel Adaptive Identity-Regularized GANs—framed within the context of geometric morphometric data augmentation. We present structured performance comparisons, detailed experimental protocols, and essential reagent solutions to equip researchers with practical implementation guidelines. The architectural blueprints outlined here serve as a foundation for enhancing research in computational biology, paleontology, pharmaceutical development, and beyond, where accurate morphological representation is paramount.
Core Architectural Definitions and Applications
Standard GANs: The foundational framework consists of two neural networks, a generator (G) and a discriminator (D), engaged in a minimax game [3]. The generator creates synthetic data from random noise, while the discriminator distinguishes between real and generated samples. This architecture is particularly effective for learning general data distributions and performing basic data augmentation without class-specific conditioning [3] [23].
Conditional GANs (cGANs): An extension of standard GANs that incorporates additional conditioning information, such as class labels, to guide the generation process [23]. This conditional input is fed to both generator and discriminator, enabling targeted synthesis of data for specific categories. cGANs have demonstrated superior performance in medical imaging (e.g., fracture reduction with 88.37% satisfaction rate versus 53.49% for manual reduction) [24] and agricultural phenotyping (achieving 0.9970 segmentation accuracy) [25].
Adaptive Identity-Regularized GANs: A specialized architecture integrating adaptive identity blocks to preserve critical species-specific features during generation, coupled with species-specific loss functions incorporating morphological constraints and taxonomic relationships [26]. This biologically-informed approach is particularly valuable for fish classification and segmentation, where it achieved 95.1% classification accuracy and 89.6% mean Intersection over Union, representing significant improvements over baseline methods [26].
Quantitative Performance Comparison
Table 1: Performance Metrics of GAN Architectures Across Applications
| Architecture | Application Domain | Key Performance Metrics | Comparative Improvement |
|---|---|---|---|
| Standard GAN | Molecular Generation | AUC: 0.94 (AlexNet discriminator) [23] | Baseline for drug-like molecule generation |
| Conditional GAN | Femoral Neck Fracture Reduction | Satisfied Reduction: 88.37% [24] | +34.88% over manual reduction (53.49%) |
| Grape Berry Segmentation | Accuracy: 0.9970, IoU: 0.9813 [25] | Optimal with 6×6 kernel size | |
| Molecular Generation | Target-specific compound generation [23] | Enabled class-controlled synthesis | |
| Adaptive Identity-Regularized GAN | Fish Classification | Accuracy: 95.1% [26] | +9.7% over baseline methods |
| Fish Segmentation | mean IoU: 89.6% [26] | +12.3% over baseline methods | |
| Biological Validation | Expert Quality Score: 88.7% [26] | Morphological plausibility assurance |
Table 2: Domain-Specific Advantages and Limitations
| Architecture | Geometric Morphometrics | Drug Discovery | Medical Imaging |
|---|---|---|---|
| Standard GAN | Generates basic shape variants [3] | Creates diverse drug-like molecules [23] | Limited application in complex anatomical contexts |
| Conditional GAN | Enables class-specific shape generation | Target-specific compound design [23] | Precision anatomical manipulation (fracture reduction) [24] |
| Adaptive Identity-Regularized GAN | Preserves taxonomically relevant morphological features | Species-specific bioactive compound generation | Biologically authentic synthetic tissue generation |
Experimental Protocols
Protocol 1: Implementing Adaptive Identity-Regularized GANs for Morphological Data Augmentation
This protocol details the procedure for implementing adaptive identity-regularized GANs, specifically designed for enhancing fish classification and segmentation performance through biologically-constrained data augmentation [26].
Materials: Fish dataset with 9,000 images across 9 species (1,000 samples each), deep learning framework with GAN implementation capabilities, high-performance computing resources, taxonomic reference database.
Procedure:
- Data Preprocessing:
- Collect and annotate fish images with species labels and segmentation masks.
- Perform image normalization and augmentation using standard transformations.
- Partition data into training (70%), validation (15%), and test (15%) sets.
Model Architecture Configuration:
- Implement adaptive identity blocks within the generator network to preserve species-invariant features.
- Design species-specific loss functions incorporating morphological constraints and taxonomic relationships.
- Configure the discriminator with multi-scale feature extraction and attention mechanisms.
Two-Phase Training:
- Phase 1 (Feature Preservation): Train generator with emphasis on identity mapping to establish stable species characteristics.
- Phase 2 (Controlled Variation): Introduce morphological variations while maintaining biological plausibility through adaptive sampling.
Validation and Evaluation:
- Quantitative assessment using classification accuracy, mean IoU for segmentation.
- Biological validation by domain experts to evaluate morphological authenticity.
- Statistical significance testing with p<0.001 threshold and effect size calculation.
Troubleshooting:
- For training instability: Adjust learning rates separately for generator and discriminator.
- For mode collapse: Implement minibatch discrimination and feature matching.
- For biologically implausible outputs: Strengthen species-specific loss constraints.
Protocol 2: Conditional GANs for Geometric Morphometric Augmentation
This protocol adapts cGAN methodologies for geometric morphometric data augmentation, particularly valuable for paleontological and archaeological applications where sample sizes are limited [3] [27].
Materials: Landmark coordinate data, 3D specimen models when applicable, computing environment with support for geometric operations, reference taxonomy.
Procedure:
- Data Preparation:
- Digitize landmark coordinates following standardized geometric morphometric protocols.
- Perform Generalized Procrustes Analysis (GPA) to remove non-shape variation.
- Convert landmark data to appropriate input format for cGAN processing.
Conditional GAN Configuration:
- Implement conditional input layers for taxonomic or morphological class labels.
- Configure generator to produce synthetic landmark configurations.
- Design discriminator to evaluate authenticity of landmark sets while considering class labels.
Training Process:
- Train generator and discriminator alternately with balanced batches.
- Incorporate graph-based regularization when working with population data [28].
- Monitor training progress with validation set shape statistics.
Synthetic Data Validation:
- Assess synthetic landmark quality through Procrustes distance to real specimens.
- Evaluate preservation of morphological relationships using Principal Component Analysis.
- Test utility through downstream classification tasks with augmented datasets.
Troubleshooting:
- For unrealistic shape generation: Increase weight of shape constraint terms in loss function.
- For poor class separation: Adjust conditional input architecture and embedding dimensions.
- For landmark correspondence issues: Implement landmark synchronization algorithms.
Protocol 3: Standard GANs for Molecular Structure Generation
This protocol outlines the application of standard GAN architectures for molecular generation in drug discovery contexts, based on the FSGLD pipeline and related approaches [29] [23].
Materials: Molecular database (e.g., ChEMBL, ZINC), molecular fingerprinting software, computing resources with GPU acceleration, molecular docking software.
Procedure:
- Data Preparation:
- Curate molecular dataset with desired properties (e.g., drug-likeness, target activity).
- Convert molecular structures to appropriate representation (fingerprints, graphs, or SMILES).
- Split data into training, validation, and test sets.
GAN Implementation:
- Implement generator network that maps random noise to molecular representations.
- Design discriminator to distinguish real from generated molecular structures.
- Select appropriate architectural variants (DCGAN, WGAN) based on data characteristics.
Training and Optimization:
- Train adversarial networks with balanced sampling from real molecular dataset.
- Implement gradient penalty or other regularization for training stability.
- Monitor diversity and quality of generated structures throughout training.
Validation and Application:
- Assess chemical validity and novelty of generated molecules.
- Evaluate synthetic accessibility and drug-like properties.
- Integrate with downstream molecular docking and dynamics simulations.
Troubleshooting:
- For invalid molecular structures: Adjust representation or add validity constraints.
- For limited diversity: Implement diversity-enforcing loss terms or sampling strategies.
- For poor chemical properties: Incorporate property prediction into discriminator.
Workflow Visualization
Diagram 1: Comparative GAN workflow for data augmentation
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Research Reagents for GAN Implementation in Geometric Morphometrics and Drug Discovery
| Reagent Category | Specific Solution | Function | Implementation Example |
|---|---|---|---|
| Data Representation | Landmark Coordinates | Capture morphological shape information | Type I, II, III landmarks with semi-landmarks for curves [3] |
| Molecular Fingerprints | Represent chemical structures | Extended-Connectivity Fingerprints (ECFP6), MACCS keys [23] | |
| Image Tensors | Standardized image input | Normalized 3D arrays (e.g., 160×160×160 for CT scans) [24] | |
| Architectural Components | Adaptive Identity Blocks | Preserve invariant features during generation | Species-specific morphological feature retention [26] |
| Graph Regularization | Maintain population structure | Inter-subject similarity preservation in manifold-valued data [28] | |
| Multi-Scale Discriminators | Enhance sample discrimination | Hierarchical feature extraction for improved realism [26] | |
| Training Mechanisms | Species-Specific Loss | Incorporate biological constraints | Taxonomic relationship integration in loss calculation [26] |
| Adversarial Loss | Drive competition between networks | Standard, Wasserstein, or manifold-aware variants [28] | |
| Reconstruction Loss | Maintain input-output similarity | Mean squared error or structural similarity measures [28] | |
| Validation Tools | Biological Expert Evaluation | Assess morphological plausibility | Quality scoring by domain specialists (e.g., 88.7% score) [26] |
| Geometric Morphometric Analysis | Quantify shape characteristics | Procrustes analysis, principal component analysis [3] | |
| Molecular Docking | Evaluate binding affinity | Virtual screening of generated compounds [23] |
The architectural blueprints presented for Standard GANs, Conditional GANs, and Adaptive Identity-Regularized GANs provide a comprehensive framework for geometric morphometric data augmentation across scientific domains. Performance metrics demonstrate the progressive enhancement in capability from standard architectures (molecular generation AUC: 0.94) to conditional models (fracture reduction satisfaction: 88.37%) and finally to specialized adaptive identity implementations (fish classification accuracy: 95.1%). The experimental protocols and reagent solutions offer practical guidance for implementation, while the workflow visualization illustrates the interconnected nature of these approaches. As generative methodologies continue to evolve, these architectural foundations will enable researchers to address increasingly complex challenges in morphological analysis, pharmaceutical development, and beyond, particularly in data-limited scenarios common in specialized scientific fields.
Application Notes
The integration of generative artificial intelligence (AI) into geometric morphometrics (GM) offers a revolutionary approach to overcoming the critical limitation of small and incomplete datasets, particularly prevalent in paleontology and taxonomic studies [3]. The core challenge lies in augmenting these datasets in a way that preserves the fundamental biological shape relationships and inherent morphological constraints, ensuring that synthetic data are not just statistically plausible but also biologically meaningful [3] [30]. Geometric morphometrics provides a powerful multivariate statistical toolkit for the quantitative analysis of biological form based on Cartesian landmark coordinates, which mathematically define the geometry of a morphology [3] [31].
Generative models, such as Generative Adversarial Networks (GANs), have demonstrated significant potential in this domain. A GAN consists of two competing neural networks: a Generator that creates synthetic data and a Discriminator that evaluates its authenticity [3]. When trained on Procrustes-aligned landmark coordinates—which are shape variables independent of size, position, and orientation—these models can learn the complex, non-linear probability distribution of biological shapes in a sample [3] [31]. The success of this approach is evidenced by studies where GANs produced multidimensional synthetic data that were statistically equivalent to the original training data [3].
More recently, advanced architectures like latent diffusion models have shown even greater promise in biologically demanding contexts. For instance, MorphDiff, a transcriptome-guided latent diffusion model, simulates high-fidelity cell morphological responses to genetic and drug perturbations [32]. By using perturbed gene expression profiles as a conditioning input, the model effectively captures the intricate relationship between molecular state and phenotypic outcome, generating realistic cellular morphologies that can accurately predict mechanisms of action (MOA) for drugs [32]. This exemplifies a powerful method for incorporating rich domain knowledge (transcriptomics) directly into the generative process.
The fidelity of these models is paramount. As highlighted in taphonomic research, methods that fail to adequately represent the full spectrum of morphological variation, such as by excluding non-oval tooth pits from analyses, can produce misleading results and low classification accuracy [14]. Therefore, the key to preserving biological fidelity is the conscientious incorporation of domain knowledge, which can manifest as phylogenetic constraints, allometric growth trajectories, or functional/developmental modules [30].
Table 1: Key Generative Models for Morphometric Data Augmentation
| Model Type | Core Mechanism | Advantages in GM | Example Application |
|---|---|---|---|
| Generative Adversarial Network (GAN) [3] | Adversarial training between Generator and Discriminator | Produces highly realistic synthetic landmark data; overcomes linearity assumptions. | Augmenting fossil landmark datasets with significantly equivalent synthetic specimens. |
| Latent Diffusion Model [32] | Reverses a gradual noising process conditioned on external data. | Highly robust to noise; supports flexible conditioning (e.g., on gene expression); superior image synthesis. | Predicting cell morphology changes under unseen drug perturbations (MorphDiff). |
| Conditional GAN (cGAN) [3] | GAN architecture where generation is conditioned on specific labels. | Potentially allows for targeted generation of shapes per taxonomic group or treatment. | Noted as less successful in some GM experiments compared to other GANs. |
Experimental Protocols
Protocol 1: Data Augmentation for Fossil Landmarks Using GANs
This protocol outlines the procedure for augmenting a landmark dataset of fossil specimens using a Generative Adversarial Network, as derived from experimental applications in geometric morphometrics [3].
1. Landmarking and Shape Variable Acquisition:
- Landmark Digitization: Collect two-dimensional (2D) or three-dimensional (3D) coordinate data from homologous anatomical points (landmarks) across all specimens in the dataset. Landmarks are defined as biologically homologous points that correspond across all specimens [31].
- Procrustes Superimposition: Perform a Generalized Procrustes Analysis (GPA) to remove the non-shape variations of scale, position, and orientation from the raw landmark coordinates. This involves:
- Centering each configuration to a common origin.
- Scaling all configurations to a unit size, typically measured as Centroid Size (the square root of the sum of squared distances of all landmarks from their centroid) [33] [31].
- Rotating configurations to minimize the Procrustes distance between each specimen and the sample mean shape.
- The resulting Procrustes shape coordinates constitute the primary shape variables for analysis [31].
2. GAN Training and Data Generation:
- Input Data Preparation: Format the Procrustes shape coordinates into a single data matrix where each row represents one specimen and each column represents a shape coordinate.
- Model Configuration: Implement a GAN architecture. The generator network should take a random noise vector as input and output a vector of synthetic shape coordinates. The discriminator network should take a vector of shape coordinates (real or synthetic) and output a probability of it being real [3].
- Adversarial Training: Train the GAN models simultaneously. The generator learns to produce synthetic landmark data that the discriminator cannot distinguish from the real Procrustes-aligned training data [3].
- Synthetic Data Generation: After training, use the generator model to produce new, synthetic landmark configurations.
3. Validation and Fidelity Assessment:
- Statistical Comparison: Use robust statistical methods, such as Multivariate Analysis of Variance (MANOVA) or Procrustes distance-based tests, to verify that the synthetic data distribution is not significantly different from the original training data distribution [3].
- Visualization: Visualize the synthetic shapes using deformation grids (e.g., thin-plate splines) to qualitatively assess whether the generated forms are biologically plausible and fall within the expected morphospace [3] [31].
Protocol 2: Predicting Cellular Morphology with a Transcriptome-Guided Diffusion Model
This protocol details the methodology for MorphDiff, a state-of-the-art model that predicts cell morphological changes under perturbations using a conditioned diffusion model [32].
1. Multi-Modal Data Curation:
- Cell Morphology Imaging: Acquire high-throughput cell morphology images, for instance, using the Cell Painting assay which typically produces five-channel images (DNA, ER, RNA, AGP, Mito) [32].
- Transcriptomic Profiling: For the same cell populations under perturbation, obtain corresponding gene expression profiles. The L1000 assay is a common choice for this purpose [32].
- Data Pairing: Ensure that each cell morphology image (or a pool of images) has a paired transcriptomic profile from the same perturbation condition.
2. Morphology Latent Space Encoding:
- Train a Morphology VAE (MVAE): Construct and train a Variational Autoencoder (VAE). The encoder compresses the high-dimensional cell morphology images into a low-dimensional latent vector, and the decoder reconstructs the images from this vector [32].
- Latent Representation Extraction: Use the trained encoder to convert all cell morphology images into their latent representations. This compressed space is where the diffusion model will operate, making training more computationally efficient [32].
3. Conditional Latent Diffusion Model Training:
- Conditioning Setup: Use the paired L1000 gene expression profiles as the conditioning signal for the diffusion model.
- Diffusion Process: The Latent Diffusion Model (LDM) is trained on a two-part process:
- Noising (Forward Process): Sequentially add Gaussian noise to the latent morphology representation over T steps until it becomes pure noise.
- Denoising (Reverse Process): Train a U-Net model to recursively predict and remove the noise at each step, conditioned on the gene expression profile. The model is trained to minimize the difference between the predicted and actual noise [32].
- Implementation Detail: The gene expression condition is integrated into the U-Net via an attention mechanism, allowing the model to learn complex relationships between gene expression and morphological features [32].
4. Model Application and Downstream Analysis:
- Prediction Modes: The trained MorphDiff model can be used in two primary modes:
- G2I (Gene-to-Image): Generate a perturbed cell morphology from a random noise vector, conditioned solely on a perturbed gene expression profile.
- I2I (Image-to-Image): Transform an unperturbed cell morphology image into its predicted perturbed state, using the perturbed gene expression profile as a guide [32].
- Feature Extraction & MOA Prediction: Use image analysis tools (e.g., CellProfiler, DeepProfiler) to extract quantitative morphological features from the generated images. These features can then be used for downstream tasks such as Mechanism of Action (MOA) retrieval and analysis [32].
Workflow and Pathway Visualizations
Generative Morphometrics Workflow
MorphDiff Model Architecture
The Scientist's Toolkit
Table 2: Essential Research Reagents and Computational Tools
| Item/Tool Name | Type | Primary Function in GM & Generative AI |
|---|---|---|
| Homologous Landmarks [3] [31] | Biological Concept / Data | Anatomically corresponding points that provide the geometric foundation for shape comparison and analysis. |
| Generalized Procrustes Analysis (GPA) [33] [31] | Statistical Method | Removes differences in scale, translation, and rotation from landmark data, isolating pure shape information for analysis. |
| Generative Adversarial Network (GAN) [3] | Computational Algorithm | Learns the distribution of real shape data to generate novel, realistic synthetic specimens for data augmentation. |
| Latent Diffusion Model (LDM) [32] | Computational Algorithm | A advanced generative model that produces high-fidelity data by reversing a noising process, often conditioned on external data (e.g., gene expression). |
| Cell Painting Assay [32] | Experimental Method | A high-throughput image-based profiling platform that stains and images multiple cellular components to generate rich morphological data. |
| L1000 Assay [32] | Experimental Method | A high-throughput gene expression profiling technology used to obtain transcriptomic data for conditioning generative models. |
| CellProfiler / DeepProfiler [32] | Software Tool | Extracts quantitative, biologically relevant morphological features from cellular images for downstream analysis and validation. |
Mitochondrial morphometry provides critical insights into cellular health, metabolic states, and disease pathologies. Traditional analysis of mitochondrial ultrastructure via transmission electron microscopy (TEM) faces significant challenges, including labor-intensive manual segmentation and limited annotated datasets. This case study explores the integration of generative artificial intelligence (AI) to synthesize high-fidelity mitochondrial ultrastructural data, thereby enhancing the accuracy and efficiency of morphometric classification. Framed within broader research on geometric morphometric data augmentation, this application note details protocols and solutions for overcoming data scarcity in biomedical image analysis.
The Data Scarcity Challenge in Mitochondrial Morphometry
Quantitative analysis of mitochondrial ultrastructure is essential for understanding cellular bioenergetics and pathology [34]. However, traditional manual segmentation of TEM images is time-consuming, prone to operator-dependent variability, and struggles with the complexity of mitochondrial networks [35] [36]. Recent comparative studies reveal that machine learning (ML) methods for mitochondrial morphometry often fail to correlate with manual operator measurements, primarily due to insufficient training data and the inability to distinguish similar ultrastructural features [35]. This limitation is particularly evident in complex cellular regions where mitochondrial membranes resemble other organelle structures.
The annotation of electron microscopy data remains a bottleneck, with a single experiment requiring up to six months of manual labeling effort [37]. This scarcity of labeled data directly impacts model performance, especially for underrepresented mitochondrial morphology classes and in cross-domain applications where models trained on one dataset perform poorly on data from different tissues or species [38].
Synthetic Data Generation Framework
Generative AI Solutions
Advanced generative models offer promising solutions to data scarcity through synthetic data augmentation:
Diffusion Models: Denoising Diffusion Probabilistic Models (DDPMs) gradually add noise to data and learn to reverse this process, generating high-quality synthetic images with realistic textures and details [37]. These models can transform simple geometric models into realistic, noisy images matching experimental conditions.
Wasserstein Generative Adversarial Networks with Gradient Penalty (WGAN-GP): This generative approach addresses training instability and mode collapse issues in traditional GANs, making it particularly suitable for complex tabular and image datasets where data is limited [39].
Variational Autoencoders (VAEs): Unsupervised deep learning frameworks that identify key features of mitochondrial targeting sequences and generate novel functional sequences based on learned patterns [40].
Implementation Protocol
Multi-Class Labeling of EM Datasets Using Diffusion Models
Materials Requirements:
- Original EM datasets (e.g., EPFL dataset with mitochondrial labels)
- Computational resources with GPU acceleration
- Diffusion model framework (e.g., PyTorch)
- U-Net-like segmentation model
Procedure:
- Dataset Preparation: Curate existing EM datasets with at least one organelle class labeled. The EPFL dataset with mitochondrial labels serves as an appropriate starting point [37].
- Model Configuration: Implement a DDPM with a U-Net architecture for the reverse diffusion process. Set parameters for noise scheduling and sampling steps.
- Training: Train the diffusion model on the existing labeled data to learn the underlying distribution of mitochondrial structures and their variations.
- Synthetic Generation: Generate synthetic EM images with multi-class labels for organelles including mitochondria boundaries, vesicles, postsynaptic densities, cell membranes, and axon sheaths.
- Validation: Assess synthetic data quality using segmentation accuracy metrics (Dice coefficient) on test datasets.
Expected Outcomes: This protocol achieved a record Dice score of 0.948 for mitochondrial segmentation, surpassing previous benchmarks and demonstrating effective augmentation of the original 165-layer EPFL dataset [37].
Experimental Validation and Performance Metrics
Quantitative Performance Analysis
Table 1: Performance Comparison of Mitochondrial Segmentation Methods
| Method | Dataset | Dice Coefficient | Time Efficiency | Classes Segmented |
|---|---|---|---|---|
| Manual Segmentation [34] | Mouse skeletal muscle | Gold standard | Reference (100%) | Limited by operator |
| Traditional U-Net [37] | EPFL mitochondria | 0.917 | ~20% of manual | 1 (mitochondria) |
| Diffusion-Augmented Model [37] | EPFL6 synthetic | 0.948 | ~10% of manual | 6 organelle classes |
| Probabilistic Interactive DL [34] | Lucchi++ & muscle tissue | Comparable to manual | ~10% of manual | 1 (mitochondria) |
Morphometric Classification Enhancement
Integration of synthetic data significantly improves mitochondrial morphometry classification:
- Feature Representation: Models trained with synthetic data demonstrate enhanced capability to distinguish subtle morphological features, including cristae density and matrix organization [35].
- Domain Adaptation: Synthetic data bridges domain gaps between different tissue types and species, improving model generalizability [38].
- Rare Morphology Capture: Generative models can create examples of rare mitochondrial phenotypes, ensuring robust classification across diverse morphological states.
Integrated Workflow for Synthetic Data-Augmented Morphometry
The following diagram illustrates the complete experimental workflow for implementing synthetic data generation and validation in mitochondrial morphometry analysis:
Workflow for Synthetic Mitochondrial Morphometry
This workflow demonstrates the integration of geometric parametric models with diffusion processing to augment limited TEM datasets, ultimately enhancing mitochondrial segmentation and quantification.
Research Reagent Solutions
Table 2: Essential Research Reagents and Computational Tools for Mitochondrial Morphometry
| Category | Specific Solution | Function/Application | Reference |
|---|---|---|---|
| Sample Preparation | Glutaraldehyde (1.5-4% in 0.1M CAC) | Primary fixative for protein cross-linking | [41] |
| Osmium Tetroxide (1% in dH₂O) | Secondary fixative for lipid preservation | [41] | |
| Hexamethyldisilazane (HMDS) | Dehydrating agent with reduced surface tension | [41] | |
| Imaging & Staining | Uranyl Acetate (5%) | Heavy metal stain for EM contrast | [34] |
| Lead Citrate (1%) | Additional EM contrast enhancement | [34] | |
| Computational Tools | MitoGraph | Open-source platform for mitochondrial morphology quantification | [36] |
| U-Net Architecture | Convolutional network for biomedical image segmentation | [37] | |
| Diffusion Models (DDPM) | Generative AI for synthetic data creation | [37] | |
| Validation Metrics | Dice-Sørensen Coefficient | Segmentation accuracy assessment | [37] |
| Morphological Parameters | Mitochondrial area, length, cristae density | [35] [36] |
Validation Framework and Quality Assessment
Morphometric Validation Protocol
Procedure for Validating Synthetic Mitochondrial Data:
Segmentation Accuracy Testing:
- Compare synthetic-augmented model performance against manual segmentation gold standards
- Calculate Dice coefficients for mitochondrial segmentation overlap
- Assess boundary precision and structural continuity
Morphometric Parameter Validation:
- Quantify key parameters: mitochondrial area, aspect ratio, cristae density
- Perform statistical comparison (t-tests, ANOVA) between synthetic and real data distributions
- Validate using independent test datasets not used in training
Functional Correlation Assessment:
Cross-Domain Generalization:
- Test model performance on datasets from different tissues and species [38]
- Evaluate using domain adaptation metrics
Quality Control Criteria: Synthetic data should maintain morphological diversity, preserve ultrastructural details, and generate physically plausible mitochondrial phenotypes that fall within biologically relevant parameter spaces.
This case study demonstrates that geometric morphometric data augmentation using generative algorithms significantly enhances mitochondrial classification in TEM ultrastructural analysis. The integration of diffusion models and other generative AI approaches addresses critical data scarcity challenges, enabling more accurate, efficient, and generalizable mitochondrial morphometry. Future developments should focus on expanding multi-organelle segmentation, refining synthetic data quality assessment protocols, and developing integrated workflows that combine synthetic data generation with automated morphological quantification. These advances will accelerate research in cellular pathophysiology, drug toxicity screening, and metabolic disease characterization.
Geometric Morphometrics (GM) is a powerful multivariate statistical toolset for the analysis of morphology, traditionally used in biological and anatomical studies but increasingly applied in non-biological fields such as drug discovery [3]. These methods utilize two or three-dimensional homologous points of interest, known as landmarks, to quantify geometric variances among individuals. In drug discovery, this can include analyzing morphological changes in cells or tissues in response to compound treatments. However, a significant limitation often encountered is incomplete or distorted data, frequently resulting in insufficient sample sizes that impede complex statistical analyses, classification tasks, and predictive modeling [3] [14].
Generative computational learning algorithms, particularly Generative Adversarial Networks (GANs), present a transformative approach to overcoming these data scarcity challenges [3]. A GAN consists of two neural networks—a Generator and a Discriminator—trained simultaneously in an adversarial process. The generator creates synthetic data, while the discriminator evaluates its authenticity. Through this competition, the generator learns to produce highly realistic synthetic data that can augment existing datasets, thereby improving the robustness and predictive power of subsequent analytical models [3]. The integration of these synthetically generated samples into drug discovery pipelines can enhance tasks such as compound efficacy prediction and toxicity assessment by providing more comprehensive data for training machine learning models [42] [26].
This document details application notes and protocols for integrating landmark-based geometric morphometric data with synthetic sample generation, specifically tailored for research and development within the pharmaceutical industry.
The tables below summarize key quantitative findings from relevant studies on generative algorithms and geometric morphometrics, providing a basis for evaluating methodological performance.
Table 1: Performance Comparison of Generative and Classification Models in Morphometric and Vision Applications
| Model/Approach | Application Context | Key Performance Metric | Result | Source |
|---|---|---|---|---|
| Traditional ML (SVM, Random Forests) | Fish classification (5-20 species) | Classification Accuracy | 70-85% | [26] |
| GAN-based Augmentation (Standard) | General Data Augmentation | N/A | Outperforms conventional augmentation | [26] |
| Adaptive Identity-Regularized GAN | Fish classification (9 species) | Classification Accuracy | 95.1% ± 1.0% | [26] |
| Improvement over Baseline | +9.7% | [26] | ||
| Improvement over Traditional Augmentation | +6.7% | [26] | ||
| Segmentation (mIoU) | 89.6% ± 1.3% | [26] | ||
| Biological Validation Score | 87.4% ± 1.6% | [26] | ||
| Computer Vision (DCNN) | Tooth Mark Classification | Classification Accuracy | 81% | [14] |
| Computer Vision (FSL) | Tooth Mark Classification | Classification Accuracy | 79.52% | [14] |
| Geometric Morphometrics (2D) | Tooth Mark Classification | Classification Accuracy | <40% | [14] |
Table 2: Core Components of an Adaptive Identity-Regularized GAN for Biologically-Plausible Synthesis
| Component | Function | Application in Drug Discovery |
|---|---|---|
| Adaptive Identity Blocks | Dynamically preserves species-/structure-specific invariant features during generation. | Maintains critical cellular or subcellular morphological landmarks in generated images. |
| Species-Specific Loss Function | Incorporates morphological constraints to ensure biological plausibility of synthetic data. | Encodes domain knowledge (e.g., expected nucleus-cytoplasm ratio) into the training process. |
| Two-Phase Training | 1. Stabilizes feature preservation mappings.2. Introduces controlled phenotypic diversity. | Ensures generated synthetic cell images are diverse yet morphologically realistic. |
Experimental Protocols
Protocol 1: Landmark Data Preparation and Preprocessing
This protocol covers the initial steps of digitizing and preparing morphological data for subsequent analysis and augmentation.
A. Landmark Digitization:
- Type I Landmarks: Identify and digitize anatomical points of biological significance in your samples (e.g., cell nuclei centers, organelle endpoints) [3].
- Type II Landmarks: Digitize points of mathematical significance, such as points of maximal curvature on a cell or tissue boundary [3].
- Type III Landmarks: Construct points around outlines or in relation to other primary landmarks to adequately capture geometry. The use of "semi-landmarks" that slide over curves and surfaces is recommended to minimize bending energy [3].
- Tools: Use automated landmark digitization software where available to reduce analyst-induced error and improve reproducibility [3].
B. Generalized Procrustes Analysis (GPA):
- Objective: To project all landmark configurations into a common coordinate system for direct comparison by removing the effects of position, orientation, and scale [3].
- Procedure:
- Center: Translate all configurations so their centroids (center of mass) are at the origin.
- Scale: Scale all configurations to a unit size.
- Rotate: Rotate configurations to minimize the sum of squared distances between corresponding landmarks.
- Output: A set of "Procrustes coordinates" representing the shape of each sample.
C. Feature Space Construction via Principal Components Analysis (PCA):
- Objective: To reduce the dimensionality of the Procrustes-aligned landmarks and represent each sample as a point in a new, more manageable feature space (e.g., Principal Component scores) [3].
- Procedure: Perform PCA on the covariance matrix of the Procrustes coordinates. The resulting principal components (PCs) represent the major independent axes of shape variation within the dataset.
- Output: A matrix where each row is a sample and each column is a principal component score. This matrix is the input for subsequent statistical modeling or synthetic generation.
Protocol 2: Synthetic Data Generation using Adaptive Identity-Regularized GANs
This protocol details the procedure for generating synthetic morphometric data using an advanced GAN architecture designed to preserve biologically critical features.
A. Model Architecture Setup:
- Generator Network: Design a neural network that takes a random noise vector and a condition label (e.g., cell type, treatment class) as input and outputs a synthetic data point in the same feature space as your real data (e.g., a vector of PCA scores).
- Discriminator Network: Design a network that takes a data point (real or synthetic) and a condition label and outputs a probability that the data point is real.
- Integration of Adaptive Identity Blocks: Incorporate adaptive identity blocks into the generator. These blocks learn to preserve species- or structure-invariant morphological features during generation, preventing the synthesis of biologically implausible samples [26].
B. Loss Function Formulation:
- Adversarial Loss: Use a standard GAN loss (e.g., Wasserstein loss) to train the generator to fool the discriminator and the discriminator to correctly identify real vs. fake data.
- Species-Specific Loss: Formulate a multi-component loss function for the generator that includes:
- Morphological Consistency Term: Penalizes deviations from known morphological constraints (e.g., valid ranges for landmark distances or angles) [26].
- Phylogenetic Relationship Constraints: (If applicable) Incorporates knowledge of hierarchical relationships between different classes to ensure generated data respects these structures [26].
- Total Generator Loss: ( \mathcal{L}{total} = \mathcal{L}{adversarial} + \lambda \mathcal{L}_{species-specific} ) where ( \lambda ) is a weighting hyperparameter.
C. Two-Phase Model Training:
- Phase 1: Feature Preservation Stabilization:
- Train the GAN with an emphasis on the identity-preserving components and the species-specific loss.
- The goal is to allow the generator to learn stable mappings that reliably maintain essential diagnostic features.
- Phase 2: Controlled Diversity Introduction:
- Gradually adjust training parameters or loss weights to encourage the generator to produce a wider, but still constrained, range of morphological variations.
- Monitor output to ensure diversity does not come at the cost of biological plausibility [26].
- Phase 1: Feature Preservation Stabilization:
D. Model Evaluation and Synthetic Data Generation:
- Quality Assessment: Use the trained discriminator's failure rate as an initial metric of synthetic data quality.
- Expert Validation: Have domain experts (e.g., biologists, pathologists) evaluate a subset of the generated data for authenticity and morphological plausibility. Target a biological validation score of >85% [26].
- Downstream Task Validation: Use the synthetic data to augment your training set for a classification or segmentation task. A significant improvement in performance (e.g., >5% accuracy increase) indicates high-quality synthetic data [26].
Workflow Visualization
The following diagrams, generated with Graphviz using the specified color palette, illustrate the core integration workflow and the GAN architecture.
Diagram 1: GM and GAN integration workflow for drug discovery.
Diagram 2: Adaptive identity-regularized GAN architecture with species-specific loss.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 3: Key Reagents and Computational Tools for GM and Generative AI Workflows
| Category / Item | Function / Application |
|---|---|
| Biological & Chemical Reagents | |
| 3D Cell Culture Kits (e.g., MO:BOT platform) | Provides standardized, reproducible, and biologically relevant human tissue models for morphological screening [42]. |
| Protein Expression Kits (e.g., Nuclera's eProtein Discovery) | Enables rapid production of challenging proteins for structural analysis, moving from DNA to protein in <48 hours [42]. |
| Software & Computational Tools | |
| Intelligent Diagramming (e.g., Lucidchart) | Used for creating and managing data flow diagrams (DFDs) to visualize and optimize complex analytical workflows [43]. |
| Geometric Morphometrics Software | Applications for digitizing landmarks, performing Procrustes alignment, and conducting shape-based statistical analyses [3]. |
| Deep Learning Frameworks (e.g., TensorFlow, PyTorch) | Platforms for building and training custom Generative Adversarial Network models, including adaptive architectures [26]. |
| Data Management & Analysis | |
| Sample Management Software (e.g., Cenevo's Mosaic) | Manages physical and digital sample data, ensuring traceability and integration with AI/automation systems [42]. |
| Digital R&D Platform (e.g., Labguru) | Provides a unified platform for experimental design, data recording, and analysis, facilitating structured data for AI [42]. |
| Trusted Research Environment (e.g., Sonrai Analytics) | Integrates complex imaging and multi-omic data with advanced AI pipelines for interpretable biological insights [42]. |
Overcoming Training Instabilities and Ensuring Biological Plausibility in Generated Data
Generative Adversarial Networks (GANs) represent a powerful class of generative models capable of learning complex data distributions. However, their adversarial training framework introduces unique challenges, primary among them being mode collapse and training instability. Mode collapse occurs when the generator produces a limited variety of outputs, often collapsing to a small set of modes from the target distribution instead of capturing its full diversity [44]. Concurrently, training failures manifest as vanishing gradients and non-convergence, where the generator and discriminator fail to reach a stable equilibrium [44] [45]. Within geometric morphometric research, where capturing the full spectrum of biological shape variation is critical, these failures present significant obstacles to effective data augmentation for downstream classification and analysis tasks [13] [26]. This document outlines proven stabilization techniques and experimental protocols to mitigate these issues, with specific application to geometric morphometric data augmentation.
Understanding the Core Problems
Defining Mode Collapse
In mode collapse, the generator identifies one or a few outputs that the current discriminator classifies as "real" and subsequently over-optimizes for these outputs [44]. The generator rotates through this small set of outputs, failing to learn the complete data distribution. For geometric morphometrics, this would manifest as a generator producing only a handful of similar shapes rather than the continuous morphological variation present in biological populations [14].
Vanishing Gradients and Non-Convergence
The adversarial training process can be modeled as a minimax game with the value function: [ \minG \maxD V(D, G) = \mathbb{E}{x\sim p{data}}[\log D(x)] + \mathbb{E}{z\sim pz}[\log(1 - D(G(z)))] ] where (G) is the generator, (D) is the discriminator, (p{data}) is the real data distribution, and (pz) is the prior noise distribution [45]. A fundamental instability arises when the discriminator becomes too effective, providing minimal gradient information (vanishing gradients) for the generator to improve [44]. Non-convergence occurs when the networks oscillate without reaching a stable equilibrium [46].
Stabilization Techniques: A Comparative Analysis
Multiple technical approaches have been developed to stabilize GAN training and mitigate mode collapse. The table below summarizes the most effective techniques.
Table 1: GAN Stabilization Techniques and Their Applications
| Technique | Mechanism of Action | Impact on Mode Collapse | Implementation Considerations |
|---|---|---|---|
| Wasserstein Loss (WGAN) [44] [45] | Replaces discriminator with a critic that outputs a scalar score rather than a probability. Uses Earth-Mover distance. | Prevents mode collapse by providing meaningful gradients even when discriminator is optimal. [44] | Requires weight clipping or gradient penalty to enforce Lipschitz constraint. |
| Unrolled GANs [44] | Generator optimization incorporates future discriminator responses, preventing over-optimization. | Mitigates mode collapse by forcing generator to consider multiple future discriminator steps. [44] | Computationally expensive due to the need to unroll and optimize multiple steps. |
| Non-Saturating Loss [45] | Alternative generator loss ((-\log(D(G(z))))) prevents gradient saturation when discriminator rejects generator samples. | Addresses vanishing gradients, indirectly supporting diversity. [45] | Simple modification to standard loss function; easy to implement. |
| One-Sided Label Smoothing [45] | Replaces discriminator's "real" label (1) with a softened value (e.g., 0.9) to prevent overconfident predictions. | Stabilizes training by preventing discriminator from becoming too strong too quickly. [45] | Typically applied only to "real" labels to avoid generator focusing on dense fake regions. |
| VAE/GAN Hybrid Models (VAE-QWGAN) [47] | Integrates a Variational Autoencoder (VAE) to provide a data-informed prior for the GAN generator. | Directly addresses mode collapse by aligning latent space with true data manifold. [47] | Increases model complexity; requires training both VAE and GAN components. |
| Adaptive Identity Regularization [26] | Uses adaptive identity blocks to preserve critical, species-specific features during generation. | Ensures generated samples maintain essential diagnostic features, improving utility. [26] | Requires domain knowledge to identify which features are critical to preserve. |
| Prediction Methods [46] | Modifies stochastic gradient descent to stabilize convergence to saddle points in the loss landscape. | Reduces likelihood of total training collapse, enabling use of larger learning rates. [46] | A general optimization technique applicable to various GAN architectures. |
Experimental Protocols for Stabilization
Protocol: Implementing a Wasserstein GAN with Gradient Penalty
This protocol is fundamental for achieving stable training and is often used as a baseline in geometric morphometric applications [47].
- Network Architecture: Design a generator ((G)) and critic ((D)) following a DC-GAN architecture but remove any final sigmoid activation in the critic.
- Loss Function: Implement the Wasserstein loss. The critic's loss is (L = D(\tilde{x}) - D(x) ), where (x) is real and (\tilde{x}) is fake. The generator's loss is (-D(\tilde{x})).
- Gradient Penalty: Add a gradient penalty term to the critic loss to enforce the Lipschitz constraint: (\lambda (\lVert \nabla{\hat{x}} D(\hat{x}) \rVert2 - 1)^2), where (\hat{x}) is a random interpolation between real and fake samples, and (\lambda) is a hyperparameter (typically 10).
- Optimizer: Use RMSProp or Adam with a low beta1 (e.g., 0.5, 0.9) as the optimizer. The critic is typically trained for 5 steps per generator step.
- Evaluation: Monitor the Wasserstein loss (should converge) and calculate the Frechet Inception Distance (FID) or, for morphometrics, a measure of shape space coverage on a held-out test set.
Protocol: Integrating a VAE Prior to Prevent Mode Collapse
This hybrid approach is particularly effective for high-dimensional data like morphometric outlines [47].
- VAE Training: First, train a standard VAE on your geometric morphometric dataset (e.g., landmark coordinates, outlines). The VAE encoder (E) maps data (x) to a latent distribution (z), and the decoder (Dec) reconstructs (x).
- GAN Integration: Fuse the pre-trained VAE decoder with the quantum or classical GAN generator ((G)) into a single model with shared parameters.
- Training with Data-Dependent Latent Vectors: During GAN training, sample latent vectors (z) using the VAE encoder (E(x)) on real data, rather than from a simple random prior like (N(0,1)). This ensures the latent space is structured and aligned with the true data distribution.
- Inference: After training, to generate new data, sample from a Gaussian Mixture Model (GMM) that has been fitted to the latent vectors generated during training. This GMM serves as the informed prior for generation.
- Validation: Quantify mode collapse by comparing the variance in the generated data to the variance in the real data within principal component analysis (PCA) plots of the morphometric shape space.
Protocol: Applying Adaptive Identity Regularization
This technique is vital for preserving taxonomically relevant morphological features in synthetic data [26].
- Identity Block Design: Incorporate adaptive identity blocks within the generator network. These blocks learn to dynamically preserve species-invariant morphological features (e.g., fin ray counts, body proportions).
- Species-Specific Loss Function: Formulate a multi-component loss function for the generator:
- Adversarial Loss: Standard loss from the discriminator.
- Morphological Consistency Loss: An (L1) or (L2) loss that penalizes deviations from known morphological constraints.
- Feature Preservation Loss: A perceptual loss ensuring that key, domain-expert-identified features are maintained.
- Two-Phase Training:
- Phase 1 (Stabilization): Train the generator with a high weight on the identity and feature preservation losses to establish stable mappings.
- Phase 2 (Diversification): Gradually reduce the weight of the preservation losses and increase the adversarial loss weight to encourage controlled phenotypic variation for augmentation.
- Biological Validation: Have domain experts (e.g., marine biologists) evaluate the synthetic specimens for biological plausibility and score them on a predefined scale.
Visualization of Stabilized GAN Architectures
Core GAN Training Loop with Key Stabilization Nodes
The following diagram illustrates the standard GAN training loop, highlighting key points where the stabilization techniques from Table 1 can be applied to prevent failure.
Workflow for a Hybrid VAE-GAN Model
This diagram outlines the specific architecture and data flow for the VAE-GAN hybrid model, a powerful method for preventing mode collapse.
The Scientist's Toolkit: Essential Research Reagents
Table 2: Key Computational Reagents for Stable GAN Research
| Reagent / Solution | Function in Experiment | Example & Rationale |
|---|---|---|
| Wasserstein Loss with Gradient Penalty | Provides stable training signal for critic/generator; enforces Lipschitz constraint. | Preferred over standard minimax loss; enables training critic to optimality without vanishing gradients. [44] [45] |
| Data-Informed Latent Prior | Replaces simple noise prior to structure the generator's input space. | Using a VAE encoder or GMM on training data latents prevents mode collapse by aligning z-space with data manifold. [47] |
| Adaptive Identity Blocks | Preserves critical, domain-specific features in generated samples. | In fish morphology GANs, ensures synthetic specimens retain species-identifying traits (e.g., fin shape). [26] |
| One-Sided Label Smoothing | Regularizes the discriminator to prevent overconfident predictions. | Using a target of 0.9 for "real" labels stabilizes training by preventing an overpowered discriminator. [45] |
| Non-Saturating Generator Loss | Prevents gradient vanishing when the generator fails to fool the discriminator. | Using (-\log(D(G(z)))) instead of (\log(1-D(G(z)))) ensures sufficient learning signal. [45] |
| Frechet Inception Distance (FID) | Quantitative metric for evaluating the quality and diversity of generated images. | Standard benchmark for GAN performance; lower scores indicate better alignment with real data distribution. |
Geometric morphometrics (GM) is a powerful multivariate statistical toolset for the analysis of morphology, employing the use of two or three-dimensional homologous points of interest (landmarks) to quantify geometric variances among individuals [3]. However, when performing complex statistical analyses such as classification tasks and predictive modelling, researchers often encounter issues related to sample size limitations and data incompleteness, particularly when working with fossil records or rare specimens [3]. These limitations frequently lead to the problem of overfitting, where models learn to reproduce the training data rather than the underlying semantics of the problem, ultimately failing to generalize to new, unseen examples [48].
In high-dimensional morphometric datasets, the risk of overfitting escalates significantly as model capacity increases relative to the available training data [49]. The fundamental challenge lies in balancing model complexity with generalization capabilities, necessitating robust regularization strategies that can effectively constrain model behavior during training without compromising representational power [49]. This challenge is particularly acute in geometric morphometrics, where the number of variables in multivariate analyses can be substantial, and the impact of bias is directly proportional to the dimensionality of the data [3].
Regularization Fundamentals and Taxonomy
Regularization techniques have emerged as essential tools in the deep learning arsenal, specifically designed to combat overfitting and enhance model generalization [49]. These methods act as constraints during network training, guiding models toward simpler representations while preventing them from becoming overly complex or too closely fitted to training examples [49]. The table below summarizes the core regularization techniques applicable to morphometric data analysis:
Table 1: Fundamental Regularization Techniques for Morphometric Data Analysis
| Technique | Mechanism | Primary Use Case | Key Advantages |
|---|---|---|---|
| L1/L2 Regularization | Imposes penalties on weight magnitudes | Controlling model complexity across all architectures | Encourages weight sparsity; mathematically straightforward to implement [49] |
| Dropout | Randomly deactivates neurons during training | Fully connected layers in baseline CNNs | Creates implicit ensemble of multiple sub-networks; computationally efficient [49] |
| Data Augmentation | Artificially expands training set via transformations | All architectures, particularly with limited data | Leverages domain knowledge; generates realistic synthetic data [3] [49] |
| Batch Normalization | Normalizes layer inputs to stabilize training | Deep networks including ResNet architectures | Reduces internal covariate shift; allows higher learning rates [50] |
| Early Stopping | Halts training when validation performance deteriorates | All architectures with validation data availability | Prevents overfitting without modifying model architecture; simple to implement [49] |
The effectiveness of these regularization strategies varies significantly based on model depth, dataset characteristics, and the specific classification task, creating a complex optimization landscape that researchers must navigate [49]. For geometric morphometric applications, the choice of regularization strategy must consider both the statistical properties of the landmark data and the architectural considerations of the learning model.
Experimental Protocols for Regularization in Morphometrics
Protocol: Generative Data Augmentation for Morphometric Datasets
Purpose: To augment geometric morphometric datasets using Generative Adversarial Networks (GANs) to overcome sample size limitations and reduce overfitting [3].
Materials and Reagents:
- 3D landmark coordinate data from geometric morphometric studies
- Python programming environment with TensorFlow or PyTorch
- GAN architecture libraries (e.g., Keras, PyTorch-GAN)
- Statistical analysis software (R, PAST, MorphoJ)
Procedure:
- Data Preprocessing: Perform Generalized Procrustes Analysis (GPA) to align landmark configurations through scaling, rotation, and translation [3].
- Feature Space Construction: Use Principal Components Analysis (PCA) to project each landmark configuration as a single multidimensional point in a newly constructed feature space [3].
- GAN Architecture Selection: Implement a standard GAN architecture consisting of two neural networks trained simultaneously: a Generator to produce synthetic data and a Discriminator to evaluate authenticity [3].
- Model Training: Train the GAN in an adversarial framework where the generator works to produce data that the discriminator cannot classify as synthetic [3].
- Synthetic Data Generation: Use the trained generator to create synthetic morphometric data that maintains the statistical properties of the original training set.
- Validation: Apply robust statistical methods to evaluate whether the synthetic data is significantly equivalent to the original training data [3].
Troubleshooting Tips: Conditional GANs may not perform as successfully as standard GANs for multidimensional morphometric data generation. If model performance is inadequate, consider experimenting with different loss functions [3].
Protocol: Regularized Classification of Morphometric Data
Purpose: To implement and compare regularization techniques for classifying morphometric data using deep learning architectures.
Materials and Reagents:
- Morphometric similarity networks derived from structural data [51]
- High-performance computing resources with GPU acceleration
- Deep learning frameworks (TensorFlow, PyTorch)
- Graph convolutional network implementations
Procedure:
- Network Construction: For neuroimaging applications, construct individual morphometric similarity networks (MSNs) by calculating inter-regional similarity of various morphometric features extracted from T1-weighted MRI scans [51].
- Population Graph Formulation: Create a population graph model where nodes represent graph-theoretical measures of MSNs, and edges denote similarity between topological features of subjects [51].
- Regularization Implementation: Apply variational edge learning to adaptively optimize edge weights to capture complex relationships between brain structure and clinical conditions [51].
- Model Training with Regularization: Implement a semi-supervised approach where all node features are input into the graph convolutional network (GCN), but only a subset of labeled nodes is used in optimization [51].
- Cross-Validation: Employ k-fold cross-validation to assess model performance and generalization capability.
- Saliency Analysis: Perform post-hoc analyses to identify features and regions most relevant for classification [51].
Validation Metrics: Calculate accuracy, F1 score, Cohen's kappa, Matthews correlation coefficient, and area under the curve (AUC) to comprehensively evaluate model performance [52].
Visualization of Regularization Workflows
Morphometric Data Regularization Pipeline
GAN-Based Data Augmentation for Morphometrics
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Research Reagents and Computational Tools for Regularized Morphometric Analysis
| Tool/Reagent | Function | Application Context | Implementation Notes |
|---|---|---|---|
| Generative Adversarial Networks (GANs) | Produces highly realistic synthetic morphometric data | Overcoming sample size limitations in fossil records | Effective for creating multidimensional synthetic data significantly equivalent to original data [3] |
| Graph Convolutional Networks (GCNs) | Models complex relationships in graph-structured morphometric data | Classification of neuropsychiatric disorders using brain connectivity | Superior performance (80.85% accuracy) for schizophrenia classification using morphometric similarity [51] |
| Morphometric Similarity Networks (MSNs) | Captures individual differences in brain structure from MRI data | Identifying patterns of abnormal brain morphology in disorders | Constructed from multiple morphometric features: cortical thickness, surface area, gray matter volume [51] |
| Variational Edge Learning | Adaptively optimizes edge weights in graph networks | Capturing complex relationships between brain structure and clinical conditions | Employed in MSN-GCN framework for superior classification performance [51] |
| Deep Convolutional Neural Networks (DCNNs) | Classifies and detects patterns in complex morphometric data | Carnivore tooth pit classification with 81% accuracy | Outperforms traditional geometric morphometric methods in classification tasks [14] |
| Few-Shot Learning (FSL) Models | Learns from limited examples | Classification when sample sizes are severely constrained | Achieves 79.52% accuracy in experimental tooth pit classification, comparable to DCNNs [14] |
Comparative Analysis of Regularization Performance
The effectiveness of regularization strategies must be evaluated through systematic comparison across different architectures and datasets. Recent research has demonstrated that ResNet-18 architectures with proper regularization achieve superior validation accuracy (82.37%) compared to baseline CNNs (68.74%) for image classification tasks [49]. Furthermore, comprehensive regularization approaches have been shown to reduce overfitting and improve generalization across all scenarios, with fine-tuned models converging faster and attaining higher accuracy than those trained from scratch [49].
In geometric morphometric applications, studies comparing deep learning approaches with multiple machine learning methods using diverse metrics including AUC, F1 score, Cohen's kappa, and Matthews correlation coefficient have found that Deep Neural Networks (DNN) generally ranked higher than Support Vector Machines (SVM), which in turn outperformed other traditional machine learning methods [52]. This comparative performance highlights the importance of selecting appropriate regularization strategies matched to both the data characteristics and model architecture.
Implementation Guidelines and Best Practices
When implementing regularization strategies for high-dimensional morphometric data, researchers should consider the following evidence-based guidelines:
First, for geometric morphometric datasets suffering from limited sample sizes, GAN-based data augmentation should be employed as a preprocessing step. Research has demonstrated that GANs using different loss functions can produce multidimensional synthetic data significantly equivalent to the original training data, thereby reducing the impact of sample size-related limitations [3]. However, it's important to note that Conditional GANs have been observed to be less successful in some morphometric applications [3].
Second, the selection of regularization techniques should be aligned with the model architecture. For baseline CNNs, dropout has proven particularly effective at addressing overfitting that manifests through excessive specialization in fully connected layers [49]. For deeper ResNet architectures, techniques that specifically target residual pathways may be more beneficial, as skip connections can sometimes propagate errors [49].
Third, comprehensive evaluation using multiple metrics is essential. Studies comparing machine learning methods have demonstrated the importance of assessing performance using an array of metrics including AUC, F1 score, Cohen's kappa, and Matthews correlation coefficient, rather than relying on a single performance measure [52]. This multi-metric approach provides a more robust assessment of model generalization and regularization effectiveness.
Finally, researchers should implement sensitivity analyses for key regularization parameters. For L2 regularization, the weight decay hyperparameter λ should be systematically evaluated across a range of values, with research indicating that values around 0.01 often represent a turning point where model performance begins to significantly degrade [48]. Similarly, for dropout regularization, probabilities between 0.1 and 0.3 have been shown to maintain predictive performance while introducing beneficial stochasticity [48].
High-dimensional, small-sample-size (HDSSS) data presents a significant challenge across multiple research fields, from geometric morphometrics (GM) in paleoanthropology to single-cell RNA sequencing (scRNA-seq) and clinical trial research in biomedicine [53] [3] [54]. In geometric morphometrics, where specimens are often rare and preservation is incomplete, the limited availability of data can severely hinder the performance of complex statistical analyses and machine learning models [3] [55]. Generative Adversarial Networks (GANs) have emerged as a powerful computational tool to address these limitations by generating synthetic, realistic data that can augment existing datasets and improve analytical robustness [3]. However, the efficacy of GANs is profoundly influenced by two critical factors: the initial sample size of the training data and the dimensionality of the feature space. This article explores the complex interplay between sample size, dimensionality, and GAN performance, providing application notes and experimental protocols to guide researchers in optimizing generative models for geometric morphometric data augmentation.
Theoretical Foundations: Sample Size, Dimensionality, and GAN Performance
The HDSSS Challenge in Geometric Morphometrics
Geometric morphometrics relies on the statistical analysis of landmark coordinates to quantify and visualize morphological variation [3]. These multivariate datasets are inherently high-dimensional, with the number of variables (landmarks) often exceeding the number of available specimens in paleoanthropological contexts [55]. This HDSSS scenario creates fundamental statistical challenges:
- Limited Representation: Small samples may not adequately capture the true morphological variation present in the population, leading to biased models and overoptimistic performance estimates [3].
- Increased Overfitting Risk: With insufficient observations relative to variables, models tend to memorize training data rather than learning generalizable patterns [3] [54].
- Reduced Discriminatory Power: Statistical tests such as Canonical Variant Analyses (CVA) demonstrate heightened sensitivity to small or imbalanced datasets [3].
Traditional resampling techniques like bootstrapping merely duplicate existing data points without creating novel information, while linear interpolation methods often fail to capture the complex, non-linear relationships inherent in morphological data [3] [56].
GAN Architecture Adaptations for HDSSS Data
Standard GAN architectures frequently underperform on HDSSS data due to training instability, mode collapse, and the significant gap between simple noise priors and complex real data distributions [53] [54]. Specialized GAN variants have been developed to address these limitations:
- Cheby-Dual-GAN: Incorporates Chebyshev interpolation and a dual-net generator to handle high-dimensional dependent features while avoiding mode collapse [53].
- LSH-GAN: Uses locality-sensitive hashing to select informative data subsets as generator input, accelerating training and improving sample quality for scRNA-seq data [54].
- Wasserstein GAN (WGAN): Replaces the traditional discriminator with a critic that measures Wasserstein distance, improving training stability and mitigating mode collapse [57].
Table 1: GAN Architectures for Addressing HDSSS Challenges
| GAN Variant | Core Innovation | Target Limitation | Application Domain |
|---|---|---|---|
| Cheby-Dual-GAN | Dual-net generator with Chebyshev interpolation points | High-dimensional feature dependencies | Microarray cancer data |
| LSH-GAN | Augments noise with LSH-sampled real data | Training instability and slow convergence | scRNA-seq data |
| WGAN | Uses Wasserstein distance as training objective | Mode collapse and vanishing gradients | Clinical trial data |
| SMOGAN | Two-stage oversampling with distribution-aware refinement | Imbalanced continuous target variables | General tabular data |
Quantitative Impact Assessment
Sample Size Effects on GAN Performance
Research demonstrates a non-linear relationship between initial sample size and GAN efficacy. In geometric morphometrics, GANs can generate realistic synthetic data even from limited specimens, but performance metrics improve significantly as sample size increases to critical thresholds [3]. For most GM applications, a minimum of 20-30 specimens per group is recommended for stable GAN training, though meaningful augmentation can be achieved with even smaller samples through appropriate architectural adaptations [3].
Experimental results from clinical research show that WGANs trained on just 5-10% of population data can generate synthetic datasets that achieve statistical power comparable to full population analyses [57]. This represents a substantial improvement over traditional statistical methods, which require significantly larger sample sizes to achieve similar power.
Table 2: Sample Size Requirements Across Domains
| Application Domain | Minimum Sample Size | Recommended Sample Size | Key Performance Metrics |
|---|---|---|---|
| Geometric Morphometrics | 15-20 specimens | 30+ specimens | Procrustes distance, classification accuracy |
| scRNA-seq Analysis | 50-100 cells | 500+ cells | Gene selection stability, clustering accuracy |
| Clinical Trials | 50-100 patients | Varies by effect size | Statistical power, type I/II error rates |
| Microarray Data | 30-50 samples | 100+ samples | Prediction accuracy, F-measure |
Dimensionality Considerations
The relationship between dimensionality and GAN performance is complex. While increasing dimensionality expands the feature space and theoretical representation capacity, it also exponentially increases the data requirements for adequate coverage [53]. In geometric morphometrics, this manifests as:
- Landmark Density Effects: Datasets with more landmarks provide more comprehensive morphological representation but require larger sample sizes for stable GAN training [3].
- Dimensionality Reduction Strategies: Principal Components Analysis (PCA) is commonly employed to project landmark data into lower-dimensional spaces before GAN training, balancing information retention with computational feasibility [3].
- Feature Dependencies: High-dimensional morphological features often exhibit complex correlations that must be preserved in synthetic samples [53].
Research on microarray data demonstrates that specialized GAN architectures like Cheby-Dual-GAN can maintain prediction accuracy above 80% even with feature dimensions exceeding 10,000 and sample sizes below 100, representing a significant advancement over conventional deep learning models [53].
Application Notes for Geometric Morphometrics
Workflow for GM Data Augmentation
Implementing GANs for geometric morphometric data augmentation requires careful consideration of the unique characteristics of landmark data. The following workflow has demonstrated efficacy in paleoanthropological applications [3]:
- Data Preprocessing: Perform Generalized Procrustes Analysis (GPA) to remove non-shape variation through scaling, translation, and rotation.
- Dimensionality Assessment: Conduct PCA to evaluate variance distribution across principal components and determine appropriate dimensionality reduction.
- GAN Selection: Choose appropriate GAN architecture based on sample size, dimensionality, and research objectives.
- Model Training: Implement training with rigorous validation using holdout specimens not included in training.
- Synthetic Data Generation: Create artificial landmark configurations using the trained generator.
- Quality Validation: Statistically compare synthetic and real data distributions using Procrustes distance and other morphological metrics.
Integration with Analysis Pipelines
Synthetic GM data should be strategically integrated into analytical workflows:
- Training Augmentation: Combine real and synthetic data to enhance classifier training for morphological pattern recognition [3].
- Power Enhancement: Augment small samples to enable analytical methods that require larger sample sizes [55].
- Hypothesis Testing: Use synthetic datasets to evaluate the robustness of morphological interpretations to sampling variation.
Experimental Protocols
Protocol 1: Baseline GAN Implementation for GM Data
Purpose: To generate synthetic landmark configurations from a limited sample of 3D GM data.
Materials:
- 3D landmark coordinates from homologous anatomical points
- R or Python programming environment with tensorflow/keras or torch
- Geometric morphometrics software (MorphoJ, EVAN Toolbox, or equivalent)
Procedure:
- Data Preparation:
- Import landmark coordinates and perform GPA to align specimens [3]
- Export Procrustes coordinates as training data
- Apply PCA and retain principal components explaining 95% of cumulative variance
GAN Configuration:
- Implement WGAN with gradient penalty (WGAN-GP)
- Configure generator with 3 hidden layers (256-512-256 nodes)
- Configure critic with similar architecture
- Set learning rate: 0.0001, batch size: 16-32, epochs: 1000+
Training:
- Train on real GM data with standard train/validation split (80/20)
- Monitor Wasserstein loss for convergence
- Generate synthetic specimens at regular intervals for quality assessment
Validation:
- Compare distribution of synthetic and real specimens in shape space
- Assess morphological realism through visualization
- Test utility in downstream classification tasks
Protocol 2: Sample Size Optimization Experiment
Purpose: To determine the minimum sample size required for stable GAN performance with GM data.
Materials:
- Complete GM dataset with adequate sample size (N≥50)
- Computational resources for repeated GAN training
- Evaluation metrics pipeline
Procedure:
- Sample Subsetting:
- Create subsets of original data with sizes: 10, 20, 30, 40, 50 specimens
- Generate 5 replicates for each sample size with random sampling
GAN Training:
- Train identical WGAN architectures on each subset
- Maintain consistent hyperparameters across all trials
- Generate 100 synthetic specimens from each trained model
Evaluation:
- Measure Procrustes distance between real and synthetic distributions
- Assess preservation of population covariance structure
- Test classification accuracy using real+synthetic training vs real-only training
Analysis:
- Plot performance metrics against sample size
- Identify inflection points where performance stabilizes
- Determine minimum viable sample size for research context
Protocol 3: Dimensionality Impact Assessment
Purpose: To evaluate how landmark count and dimensionality reduction affect synthetic data quality.
Materials:
- High-density landmark dataset (30+ landmarks)
- Capacity for computational intensity monitoring
Procedure:
- Landmark Subsetting:
- Create landmark subsets: Type I only, Type I+II, Type I+II+III
- Apply semilandmark sliding where appropriate
Dimensionality Treatment:
- Process each landmark set through GPA
- Apply PCA with different variance retention thresholds (90%, 95%, 99%)
- Record number of PCs retained for each treatment
GAN Training & Evaluation:
- Train separate GANs on each dimensionality treatment
- Generate synthetic data from each model
- Evaluate reconstruction error and morphological realism
- Monitor computational requirements and training stability
Optimization:
- Identify optimal dimensionality reduction strategy
- Balance computational efficiency with morphological fidelity
- Establish guidelines for landmarking effort vs. data quality
The Scientist's Toolkit
Table 3: Essential Research Reagents and Computational Tools
| Tool/Resource | Type | Function | Application Note |
|---|---|---|---|
| MorphoJ | Software | GM analysis and visualization | Primary tool for GM data preprocessing and visualization |
| R (geomorph) | Software | Statistical analysis of GM data | Comprehensive GM analysis with advanced statistical testing |
| Python (scikit-learn) | Software | Machine learning implementation | Flexible environment for custom GAN implementation |
| LSHForest | Algorithm | Approximate nearest neighbor search | Critical for LSH-GAN implementation to sample data subsets |
| WGAN-GP | Algorithm | Stable GAN training with gradient penalty | Recommended baseline architecture for GM data |
| Monte Carlo Simulation | Method | Statistical inference and validation | Essential for validating synthetic data quality |
| Procrustes Distance | Metric | Shape difference quantification | Primary metric for assessing synthetic data fidelity |
The efficacy of GANs for geometric morphometric data augmentation is intimately connected to both sample size and dimensionality considerations. While HDSSS scenarios present significant challenges, specialized GAN architectures and methodological protocols can generate high-quality synthetic data that enhances analytical capabilities in paleoanthropology and beyond. By implementing the application notes and experimental protocols outlined herein, researchers can optimize GAN performance for their specific morphological research questions, potentially unlocking new insights from otherwise limited specimens. Future work should focus on developing domain-specific GAN architectures tailored to the unique characteristics of morphological data and establishing standardized validation frameworks for synthetic specimens in evolutionary research.
Geometric Morphometrics (GM) is a powerful multivariate statistical toolset for the analysis of morphology, employing two or three-dimensional homologous points of interest (landmarks) to quantify geometric variances among individuals [3]. Modern applications incorporate these tools into numerous fields beyond biological and anatomical studies [3]. However, like many data science fields, Geometric Morphometric techniques are often impeded by issues concerning sample size, a problem acutely felt in paleontology where the fossil record is notoriously incomplete and distorted [3] [13].
Generative computational learning algorithms, particularly Generative Adversarial Networks (GANs), present a promising solution for geometric morphometric data augmentation. These algorithms can produce highly realistic synthetic data, helping improve the quality of subsequent statistical or predictive modelling applications [3]. Nevertheless, a critical challenge remains: ensuring that synthetically generated datasets faithfully retain the meaningful biological variance present in original empirical data. Failure to maintain this variance can lead to misleading scientific conclusions, failed model generalization, and ultimately, reduced trust in synthetic data methodologies.
This Application Note details the principal validation pitfalls encountered when generating and using synthetic morphometric data and provides structured protocols to ensure biological relevance and statistical integrity are preserved throughout the augmentation pipeline.
Core Validation Pitfalls and Quantitative Frameworks
The adoption of synthetic data in biological research carries significant risks if validation is inadequate. The table below summarizes the core pitfalls and their potential impacts on research outcomes.
Table 1: Core Validation Pitfalls for Synthetic Biological Data
| Pitfall Category | Description | Impact on Research |
|---|---|---|
| Loss of Rare Morphological Variants | Generative models often mimic the center of the distribution, missing rare/critical events and temporal nuances [58]. | Models trained on this data can fail in real-world applications and miss critical biological signals, such as in-hospital patient deteriorations [58]. |
| Amplification of Existing Bias | If source data are biased, synthetic replicas can amplify inequities and create self-reinforcing feedback loops that degrade trust and widen disparities [58]. | Perpetuates and exacerbates underrepresentation of certain subgroups, compromising the fairness and generalizability of findings [58] [59]. |
| Poor Correlation Preservation | Failure to maintain complex correlation structures and multivariate relationships between different morphological landmarks [60]. | Produces biologically implausible forms and leads to unreliable predictive models, as variable interactions drive morphometric predictive power [60]. |
| Insufficient Realism for Regulatory Scrutiny | Lack of provenance; synthetic records cannot be tied to a beneficiary chart, clinician, or timestamp [58]. | Rejection by regulatory bodies (e.g., FDA, CMS) for submissions and audits, leading to financial and compliance risks [58]. |
Quantitative Validation Metrics
A robust validation strategy requires quantifying the fidelity of synthetic datasets. The following table outlines key metrics derived from statistical and machine learning validation methods.
Table 2: Key Metrics for Quantitative Validation of Synthetic Morphometric Data
| Validation Method | Key Metrics | Interpretation & Target Value |
|---|---|---|
| Distribution Comparison | Jensen-Shannon Divergence [60], Wasserstein Distance [60], Kolmogorov-Smirnov test p-value [60]. | Lower values for divergence/distance indicate closer distribution matching. p-value > 0.05 suggests acceptable similarity [60]. |
| Correlation Preservation | Frobenius Norm of the difference between correlation matrices [60]. | A value closer to 0 indicates the correlation structure between variables (landmarks) has been better preserved. |
| Discriminative Testing | Binary Classifier Accuracy (Real vs. Synthetic) [60]. | Accuracy close to 50% (random chance) indicates high-quality synthetic data that is indistinguishable from real data. |
| Comparative Model Performance | Performance Gap (e.g., difference in F1-score, Accuracy) [60]. | A smaller performance gap between models trained on real vs. synthetic data indicates higher utility of the synthetic data. |
| Dimensional Analysis | Precision-Recall AUC (Area Under the Curve) [61]. | Significant increase in AUC with augmented data vs. non-augmented data demonstrates the value of synthesis [61]. |
Experimental Protocols for Robust Validation
Protocol 1: Statistical Validation of Distribution and Correlation
Purpose: To ensure the synthetic dataset preserves the statistical properties of the original geometric morphometric data.
Materials:
- Software: Python with SciPy, scikit-learn, and NumPy libraries [60].
- Input Data: Original real-world landmark dataset (e.g., Procrustes coordinates) and generated synthetic dataset.
Methodology:
- Compare Distribution Characteristics:
- For each principal component (PC) score or landmark coordinate, generate histogram or kernel density plots for visual inspection [60].
- Quantitatively, apply the Kolmogorov-Smirnov test (e.g., using
stats.ks_2sampin SciPy) to compare the distribution of each key variable between real and synthetic sets [60]. - For a multivariate assessment, compute the Jensen-Shannon Divergence or Wasserstein Distance between the full distributions.
- Validate Correlation Preservation:
- Calculate correlation matrices (using Pearson or Spearman coefficients) for both real and synthetic datasets.
- Compute the Frobenius norm of the difference between these two matrices to obtain a single metric quantifying correlation similarity [60].
- Visualize the two correlation matrices and their difference using heatmaps to identify specific variable pairs with poor correlation preservation.
Validation Criteria:
- Kolmogorov-Smirnov p-value > 0.05 for critical morphological axes [60].
- Frobenius norm of correlation matrix difference below a pre-defined, biologically-informed threshold.
Protocol 2: Machine Learning-Based Utility Validation
Purpose: To functionally assess whether synthetic data can effectively replace real data for training predictive models.
Materials:
- Software: Python with scikit-learn, XGBoost, or other ML libraries.
- Input Data: Labeled real-world dataset (e.g., species, treatment groups), split into training and test sets. Synthetic dataset.
Methodology:
- Discriminative Testing:
- Combine real and synthetic samples with labels indicating their origin.
- Train a binary classifier (e.g., Gradient Boosting with XGBoost) to distinguish between real and synthetic samples [60].
- Use cross-validation to estimate the classifier's accuracy.
- Comparative Model Performance Analysis:
- Train two identical machine learning models (e.g., SVM, CNN-LSTM) with identical architectures and hyperparameters. Train one on the real data and the other on the synthetic data [60].
- Evaluate both models on the same, held-out test set of real data.
- Compare performance metrics relevant to the biological question (e.g., classification accuracy, F1-score, RMSE).
Validation Criteria:
- Discriminative classifier accuracy is not significantly greater than 50%.
- The performance gap between the model trained on synthetic data and the model trained on real data is minimal (e.g., <5% absolute difference in accuracy) [60].
Protocol 3: Biological Plausibility and Edge Case Audit
Purpose: To qualitatively and quantitatively ensure that synthetic data encompasses the full range of biologically plausible forms, including rare variants.
Materials:
- Software: Morphometric visualization software (e.g., MorphoJ), statistical software.
- Input Data: Original and synthetic landmark data.
Methodology:
- Dimensionality Reduction and Visualization:
- Perform a Principal Component Analysis (PCA) on the combined real and synthetic dataset.
- Visualize the data in the morphospace defined by the first few PCs, coloring points by their dataset origin (real vs. synthetic).
- Edge Case and Rare Event Analysis:
- Identify samples in the real dataset that represent rare morphological variants or fall in the extremes of the PCA.
- Check if the synthetic data generates points in these low-density regions of the morphospace.
- Use anomaly detection algorithms like Isolation Forest on the real data to identify outlier patterns. Compare the proportion and characteristics of these outliers in the synthetic data [60].
Validation Criteria:
- Synthetic data points show substantial overlap with real data in the PC morphospace without collapsing to the mean.
- The synthetic dataset contains a proportional representation of rare morphological variants and edge cases present in the original data.
Visualization of Workflows
Synthetic Data Validation Pipeline
Title: End-to-End Synthetic Data Validation Workflow
Geometric Morphometric Augmentation with GANs
Title: GAN Architecture for Morphometric Data Augmentation
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Tools for Synthetic Morphometric Data Generation and Validation
| Tool / Reagent | Type | Function in Workflow | Key Consideration |
|---|---|---|---|
| Generative Adversarial Network (GAN) [3] | Software Algorithm | Core engine for generating new synthetic landmark configurations from original data. | Different architectures (e.g., WGAN, Conditional GAN) offer trade-offs in stability and control over output. |
| Python (SciPy, scikit-learn) [60] | Software Library | Provides statistical tests (KS-test) and machine learning models for quantitative validation. | The open-source ecosystem is essential for implementing custom validation pipelines. |
| Real-World Hold-Out Dataset [59] | Data | Serves as the ground-truth benchmark for all validation protocols. | Must be representative, high-quality, and completely isolated from the synthetic data generation process. |
| Principal Component Analysis (PCA) [3] | Analytical Method | Reduces dimensionality of landmark data for visualization and analysis in morphospace. | Critical for visualizing the distribution of real vs. synthetic data and identifying coverage gaps. |
| XGBoost Classifier [60] | Software Algorithm | Used in discriminative testing to evaluate how indistinguishable synthetic data is from real data. | A high-accuracy classifier provides the most rigorous test for synthetic data quality. |
| AndroGen [62] | Open-source Software | Example of a domain-specific tool for generating synthetic sperm images, illustrating the principle. | Highlights the move towards customizable, open-source solutions for specific biological data types. |
Benchmarking Performance: Statistical Validation and Comparative Analysis of Augmentation Methods
Robust Statistical Frameworks for Evaluating Synthetic Data Quality and Equivalence
The augmentation of geometric morphometric (GM) datasets using generative algorithms presents a powerful solution to the pervasive challenge of small sample sizes in fields like paleoanthropology and drug discovery [3] [13]. Geometric Morphometrics involves the multivariate statistical analysis of morphological forms based on homologous landmarks, but its statistical power is often limited by incomplete fossil records or scarce biological samples [3]. Generative Adversarial Networks (GANs) and other generative models can produce synthetic landmark data to augment these datasets; however, the value of this augmented data is entirely contingent on the rigorous, robust statistical evaluation of its quality and equivalence to real data [63] [64]. This document outlines application notes and protocols for establishing such an evaluation framework, ensuring that synthetically augmented GM datasets are statistically sound for downstream research applications.
A Multi-Dimensional Quantitative Framework for Evaluation
Evaluating synthetic data requires a multi-faceted approach that assesses both fidelity (the statistical similarity to real data) and utility (the performance on downstream tasks) [63]. Relying on a single metric is insufficient, as different metrics capture different aspects of quality and can exhibit instability across different generative models and datasets [63].
The following table summarizes the key metrics for a comprehensive evaluation, organized into core dimensions of fidelity.
Table 1: Key Fidelity Metrics for Evaluating Synthetic Geometric Morphometric Data
| Dimension | Metric | Application in Geometric Morphometrics | Interpretation |
|---|---|---|---|
| Distance | Euclidean Distance [63] | Measures the absolute distance between landmark configurations in the multivariate space. | Lower values indicate better preservation of global shape geometry. |
| Distance | Hellinger Distance [63] | Quantifies the similarity between probability distributions of Procrustes coordinates. | Lower values indicate closer distributional alignment. |
| Correlation/Association | Feature-wise Correlation | Measures the preservation of linear relationships between pairs of landmarks. | Values near 1.0 indicate correlation structures are maintained. |
| Correlation/Association | Association Measures | Evaluates non-linear dependencies among landmarks or other variables. | Critical for maintaining complex morphological covariation. |
| Feature Similarity | Precision, Recall, F1-Score [63] | Assesses the quality and coverage of synthetic data in a classification context (e.g., species classification). | High precision/recall indicates synthetic data is realistic and diverse. |
| Multivariate Distribution | Kolmogorov-Smirnov (KS) Test [64] | Tests if univariate distributions of individual landmark coordinates come from the same distribution. | A non-significant p-value suggests distributional equivalence. |
| Multivariate Distribution | Total Variation Distance (TVD) [64] | Compares the distributions of categorical variables (e.g., classification labels). | Lower values indicate better match in categorical outcomes. |
To address the instability of individual metrics, the concept of a Super-Metric has been developed [63]. This composite metric aggregates scores from multiple dimensions (e.g., Distance, Correlation, Feature Similarity, Multivariate Distribution) into a single, weighted score that demonstrates stronger correlation with the actual utility of the synthetic data in classification tasks.
Table 2: The Super-Metric Composition for Geometric Morphometrics [63]
| Aggregated Dimension | Example Metrics | Weighting Principle |
|---|---|---|
| Distance | Euclidean, Hellinger | Automatically adjusted to maximize correlation with utility metrics (e.g., F1-score) in a specific task. |
| Correlation/Association | Feature-wise Correlation | Prioritizes dimensions most relevant to the preservation of morphological structures. |
| Feature Similarity | Precision, Recall, F1-Score | |
| Multivariate Distribution | KS Test, TVD |
Protocol: Implementing the Super-Metric for GM Data
Application Note: This protocol is designed for a dataset of Procrustes-aligned landmark coordinates.
- Data Preparation: Start with a real dataset of Procrustes coordinates ((X{real})) and a synthetically generated dataset ((X{synth})).
- Metric Calculation: For each synthetic/real data pair, compute the full suite of metrics listed in Table 1.
- Utility Baseline: Train a standard classifier (e.g., Support Vector Machine) on the synthetic data and evaluate its performance (Recall, F1-score) on a held-out set of real data. This establishes the ground-truth utility.
- Weight Optimization: Use an optimization algorithm (e.g., linear regression, evolutionary algorithms) to find the set of weights for the fidelity metrics that maximizes the correlation between the composite Super-Metric score and the utility metrics.
- Validation: The resulting Super-Metric provides a stable, single-score evaluation for future generative model comparisons.
Experimental Protocols for Statistical Equivalence Testing
Beyond fidelity metrics, a robust framework should test for statistical equivalence between the real and synthetic data distributions. The following protocol outlines a method for this purpose.
Protocol: Two-One-Sided Test (TOST) for Distributional Equivalence
Aim: To statistically demonstrate that the synthetic and real GM data are equivalent within a pre-defined margin.
- Define the Equivalence Margin (( \Delta )): This is the most critical step. The margin should be a small, clinically or scientifically meaningful difference in the multivariate space. For Procrustes coordinates, this could be based on the Procrustes distance. Justify the chosen margin explicitly.
- Calculate the Test Statistic: A common approach is to use the Mahalanobis distance between the group means of the real and synthetic data in the principal component (PC) space, using the pooled covariance matrix. Alternatively, use the maximum mean discrepancy (MMD).
- Establish Confidence Intervals: Calculate the (100(1-2\alpha)\%) confidence interval (CI) for the true difference between the distributions (e.g., for the Mahalanobis distance). A typical value is a 90% CI for a one-sided ( \alpha = 0.05 ).
- Test the Hypotheses:
- Null Hypothesis (H01): The true difference is ( \leq -\Delta ).
- Null Hypothesis (H02): The true difference is ( \geq \Delta ).
- Alternative Hypothesis (H1): The true difference is within the margin (( -\Delta < \text{difference} < \Delta )).
- Decision Rule: If the entire (100(1-2\alpha)\%) CI for the difference lies entirely within the interval ((-\Delta, \Delta)), you can reject both null hypotheses and conclude statistical equivalence.
Workflow Visualization for Synthetic Data Evaluation
The following diagram illustrates the integrated workflow for generating and evaluating synthetic geometric morphometric data, from data preparation to final validation.
Synthetic Data Quality Assessment Workflow
The Scientist's Toolkit: Research Reagent Solutions
This table details essential computational tools and materials for implementing the described robust evaluation framework.
Table 3: Essential Research Reagents for Synthetic Data Evaluation
| Research Reagent | Type / Function | Application in Protocol |
|---|---|---|
| MalDataGen Framework [63] | Modular open-source platform for generation and evaluation. | Orchestrates the entire workflow: integrates generative models (GANs, VAEs, ARF) and computes the Super-Metric. |
| Super-Metric [63] | Composite weighted fidelity score. | Provides a stable, unified score for quality assessment, reducing variability from individual metrics. |
synthpop R Package [65] |
Synthetic data generator using CART models. | Generates fully or partially synthetic versions of the original GM data for augmentation. |
StatMatch R Package [65] |
Toolbox for statistical matching. | Used to evaluate data integration utility and compare distributions between donor and recipient datasets. |
| Adversarial Random Forest (ARF) [64] | Tree-based generative model. | An alternative to GANs for generating complex, mixed-type tabular data, including GM landmarks and metadata. |
| Two-One-Sided Test (TOST) | Statistical equivalence testing procedure. | The core method for formally testing if synthetic and real data distributions are equivalent within a margin. |
| Equivalence Margin (( \Delta )) | Pre-defined, scientifically justified tolerance. | A critical parameter for the TOST procedure, defining an acceptable level of difference between datasets. |
The analysis of shape using Geometric Morphometrics (GM) is a cornerstone of research in fields like biology, anthropology, and paleontology. These methods rely on the quantitative analysis of form using coordinates of homologous landmarks [3] [66]. A pervasive challenge in this domain, however, is the limited sample sizes and class imbalance often encountered in datasets derived from fossils, rare species, or clinical populations [3] [67]. Such imbalances can severely compromise the performance of statistical and machine learning models, leading to overfitting and biased results [3] [68].
To overcome these challenges, researchers employ data-level solutions. This application note provides a comparative analysis of three fundamental strategies: traditional resampling, transformation-based augmentation, and Generative Adversarial Network (GAN)-based augmentation, with a specific focus on their application within geometric morphometrics. We summarize quantitative performance data, provide detailed experimental protocols, and offer guidance for selecting the appropriate method based on dataset characteristics and research goals.
Quantitative Performance Comparison
The following tables summarize the performance characteristics of the three data balancing strategies as evidenced by recent research.
Table 1: Overall Comparative Analysis of Balancing Methods
| Method Category | Key Examples | Key Advantages | Key Limitations | Reported Performance (Context) |
|---|---|---|---|---|
| Traditional Resampling | SMOTE, ADASYN, BSMOTE [68] [69] | Simple, computationally efficient, effective for moderately imbalanced data [69]. | Limited diversity, may introduce noise, struggles with complex distributions [68] [69]. | F1-Score: 0.51 for DoS class with BSMOTE [69]. |
| Transformation-Based Augmentation | Geometric transformations, noise injection | Simple to implement, preserves label integrity, no complex training. | Limited diversity, may not capture complex morphological variations. | Lower accuracy/F1-score compared to GANs in image-based fault diagnosis [70]. |
| GAN-Based Augmentation | Vanilla GAN, CGAN, CTGAN, Deep-CTGAN [70] [71] | Generates highly realistic, diverse synthetic data; captures complex distributions [70] [3]. | Computationally intensive, requires large samples for training, risk of mode collapse [72]. | Accuracy: 86.02%, F1-Score: 86.00% (Solar PV fault diagnosis) [70]. Accuracy: 90.1% (with YOLOv8 classifier) [70]. |
| Hybrid Methods | GAN-AHR (Adaptive Hybrid Resampling) [69] | Dynamically selects best method (e.g., CGAN or BSMOTE) based on data characteristics [69]. | Increased complexity in design and implementation. | F1-Score: 0.90 for Shellcode class [69]. |
Table 2: GAN Variants and Their Suitability for Morphometric Data
| GAN Variant | Key Mechanism | Suitability for Geometric Morphometrics |
|---|---|---|
| Vanilla GAN [71] | Basic unsupervised framework for generating synthetic data. | Foundational architecture; may struggle with structured data requirements. |
| Conditional GAN (CGAN) [71] [69] | Conditions generation on class labels, enabling targeted sample creation. | Highly suitable for generating samples for specific, under-represented morphological classes [69]. |
| Deep-CTGAN + ResNet [68] | Uses residual networks for tabular data synthesis, capturing complex patterns. | Applicable for high-dimensional morphometric data (e.g., landmark coordinates), improves feature learning [68]. |
Experimental Protocols
Protocol for GAN-Based Augmentation in GM
This protocol is adapted from studies on GM data augmentation using generative algorithms [3].
Objective: To generate synthetic landmark configurations for minority classes to balance a GM dataset.
Materials:
- A dataset of landmark configurations (e.g., from os coxae, nasal cavities) in the form of a ( n \times k \times m ) array, where ( n ) is the number of specimens, ( k ) is the number of landmarks, and ( m ) is the number of coordinates [66] [73].
- Computing environment with deep learning frameworks (e.g., TensorFlow, PyTorch).
Procedure:
- Data Preprocessing:
- Perform Generalized Procrustes Analysis (GPA) on all landmark configurations to remove variation due to position, rotation, and scale [66] [73].
- Export the Procrustes-aligned coordinates as a 2D matrix (samples × variables) for GAN training.
- Split the data by class, identifying the majority and minority classes.
GAN Training:
- Select a GAN architecture suited to the data. A Conditional GAN (CGAN) is recommended to control the class of generated output [71] [69].
- Train the GAN exclusively on the Procrustes-aligned coordinates of the minority class(es).
- The generator learns to produce synthetic landmark configurations, while the discriminator learns to distinguish them from real specimens [3].
Synthetic Data Generation and Validation:
- Use the trained generator to create a sufficient number of synthetic landmark configurations to balance the dataset.
- Validate the synthetic data using:
- Statistical Tests: Perform MANOVA or similar on real vs. synthetic data to ensure no significant statistical difference in their distributions [3].
- Downstream Task Performance: Use a "Train on Synthetic, Test on Real" (TSTR) approach [68]. Train a classifier (e.g., LDA, SVM) on the augmented dataset and test its performance on a held-out set of real data.
Protocol for Traditional Resampling in GM
Objective: To balance class distribution using interpolation-based methods.
Materials:
- A GM dataset prepared as a 2D matrix of Procrustes-aligned coordinates.
Procedure:
- Data Preparation: Prepare the Procrustes-aligned coordinates as a feature matrix with corresponding class labels.
- Resampling Application: Apply a resampling algorithm like SMOTE or Borderline-SMOTE (BSMOTE).
- Validation: Validate the resampled dataset using a classifier in a cross-validation framework and compute metrics like F1-score to assess improvement for the minority class.
Protocol for a Hybrid Resampling Approach
The GAN-AHR algorithm demonstrates an adaptive framework that can be conceptually applied to GM data [69].
Objective: To dynamically select the best resampling method (BSMOTE or CGAN) for each minority class based on its data characteristics.
Procedure:
- Compute Class Characteristics: For each minority class, compute:
- Compactness: The average intra-class distance. Low compactness indicates a sparse, spread-out class.
- Density: The number of samples per unit feature space.
- Method Selection:
- If a class has high compactness and high density, use BSMOTE.
- If a class has low compactness (sparse) and complex boundaries, use CGAN.
- Execute and Validate: Perform the selected resampling method for each class and validate the final, balanced dataset.
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Tools and Software for GM Data Augmentation Research
| Item / Reagent | Function / Purpose | Example Tools / Libraries |
|---|---|---|
| 3D Digitization & Landmarking Software | To capture and define homologous landmarks on biological specimens or their 3D models. | Viewbox 4 [66] [73], Artec Studio [66] |
| Procrustes Analysis Tool | To standardize landmark configurations by removing effects of translation, rotation, and scale. | geomorph R package [73] |
| Traditional Resampling Algorithms | To balance datasets using interpolation-based methods. | imbalanced-learn (Python), SMOTE, ADASYN [68] |
| Generative Adversarial Network Frameworks | To generate synthetic data by learning the underlying distribution of the real data. | TensorFlow, PyTorch, CTGAN [68] [71] |
| Classification & Validation Models | To evaluate the quality of synthetic data and the performance of the final model. | Support Vector Machines (SVM), Random Forest, XGBoost, TabNet [3] [68] [69] |
The choice between GANs, traditional resampling, and hybrid methods depends on the specific research context, data characteristics, and computational resources.
- Use Traditional Resampling (SMOTE/BSMOTE) for moderately imbalanced datasets where minority classes are relatively well-represented and have clear structure. This approach offers a good balance between simplicity and effectiveness [69].
- Use GAN-Based Augmentation when dealing with severe class imbalance, complex morphological distributions, or when the highest quality and diversity of synthetic data are required. GANs have proven superior in generating realistic samples that enhance model generalizability, as shown by their high accuracy and F1-scores in comparative studies [70] [3].
- Consider Hybrid Approaches like GAN-AHR for complex, real-world datasets where different minority classes exhibit varying characteristics (e.g., some are compact, others are sparse). This adaptive strategy optimizes performance by leveraging the strengths of different methods [69].
For geometric morphometrics research, where data is often high-dimensional and precious, GANs and hybrid models present a powerful avenue for overcoming the limitations of small and imbalanced samples, thereby enabling more robust and reliable morphological analyses.
Geometric Morphometrics (GM) provides a powerful statistical framework for quantifying morphological variation but is often impeded by limited sample sizes, leading to overfitting and reduced predictive performance in classification tasks. This application note details protocols for implementing generative adversarial networks (GANs) for data augmentation within a GM research context. We present quantitative evidence demonstrating significant improvements in classification accuracy and model robustness, alongside standardized experimental workflows and reagent solutions to ensure reproducible and biologically plausible synthetic data generation.
Geometric Morphometrics (GM) involves the multivariate statistical analysis of form using two or three-dimensional homologous landmarks to quantify geometric variances among individuals [3]. Modern applications now incorporate these tools into fields of non-biological origin, including archaeology and taphonomy [3] [74]. However, the fossil record is notoriously incomplete and distorted, frequently conditioning the type of knowledge that can be extracted from it [3]. This leads to significant issues when performing complex statistical analyses, such as classification tasks and predictive modeling, which are highly sensitive to small or imbalanced datasets [3] [14].
Generative Adversarial Networks (GANs) have emerged as a transformative approach to address these persistent data scarcity challenges [3] [26]. The adversarial training framework, characterized by the competitive optimization of generator and discriminator networks, has demonstrated a remarkable capacity for learning complex data distributions and synthesizing high-fidelity samples [26] [75]. This note provides a comprehensive guide to quantifying the impact of GAN-based augmentation on GM analysis, establishing rigorous protocols for evaluating enhancements in classification accuracy and predictive visualization.
Quantitative Evidence of Improvement
Empirical studies across multiple domains, including biology, medicine, and archaeology, consistently report that GAN-based data augmentation leads to substantial gains in model performance. The following tables summarize key quantitative findings.
Table 1: Summary of Classification Accuracy Improvements from GAN-based Augmentation
| Application Domain | Baseline Accuracy (%) | Accuracy with GAN Augmentation (%) | Absolute Improvement (%) | Source Model |
|---|---|---|---|---|
| Fish Species Classification | 85.4 | 95.1 | +9.7 | Adaptive Identity-Regularized GAN [26] |
| fNIRS Task Classification | ~90.0 (Traditional ML) | 96.7 | +6.7 | Conditional GAN (CGAN) [75] |
| Cancer Phenotype (Binary) | 94.0 (n=50 samples) | 98.0 | +4.0 | GAN (Transcriptomics) [76] |
| Cancer Phenotype (Tissue) | 70.0 (n=50 samples) | 94.0 | +24.0 | GAN (Transcriptomics) [76] |
| Brain Tumour Segmentation | Baseline Dice | +0.04 Dice | +0.04 (Dice) | StyleGAN2-ada [77] |
Table 2: Performance of Geometric Morphometrics vs. Computer Vision Methods
| Methodology | Reported Classification Accuracy | Key Limitations |
|---|---|---|
| 2D Geometric Morphometrics (GMM) | <40% [14] | Limited discriminant power for carnivore tooth mark identification; low accuracy and resolution. |
| Computer Vision (Deep Learning) | 81% (DCNN) [14] | High accuracy but sensitive to taphonomic alterations in the fossil record. |
| Hybrid GM & Deep Learning | >90% [74] | Successfully applied to cut and trampling mark classification, overcoming equifinality. |
Experimental Protocols
Protocol 1: Standardized Workflow for GM Data Augmentation
This protocol outlines the core procedure for augmenting geometric morphometric datasets using Generative Adversarial Networks.
I. Input Data Preparation
- Landmark Digitization: Collect 2D or 3D homologous landmarks following standardized geometric morphometric protocols. Define landmarks as Type I (anatomical points), Type II (mathematical points of curvature), or Type III (constructed points) [3].
- Generalized Procrustes Analysis (GPA): Project landmark configurations onto a common coordinate system via superimposition (scaling, rotation, translation) to enable direct comparison [3].
- Feature Space Construction: Perform Principal Components Analysis (PCA) on Procrustes-aligned coordinates to reduce dimensionality and project each specimen as a point in a multidimensional feature space (ℝn) [3]. The resulting principal component (PC) scores form the dataset for GAN training.
II. GAN Training and Data Generation
- Model Selection: Select an appropriate GAN architecture. A standard GAN or Wasserstein GAN (WGAN-GP) is recommended for initial experiments to mitigate mode collapse [3] [76].
- Conditional Generation (If applicable): For multi-class problems, use a Conditional GAN (CGAN) [75]. The generator and discriminator are conditioned on class labels (e.g., species, treatment group) to enable controlled generation of specific categories.
- Adversarial Training:
- The Generator (G) takes a random noise vector z from a Gaussian distribution and learns to map it to synthetic PC scores that resemble the real training data [75].
- The Discriminator (D) is trained to distinguish between "real" PC scores from the original dataset and "fake" ones produced by G [3] [75].
- The models are trained simultaneously in a minimax game, as defined by the objective function [76]: ( \minG \maxD L(D, G) = \mathbb{E}{x \sim p{data}}[\log D(x)] + \mathbb{E}{z \sim pz}[\log(1 - D(G(z)))] )
- Synthetic Data Generation: After training, use the trained generator to produce a large number of synthetic PC scores.
III. Downstream Task Evaluation
- Dataset Splitting: Split the original real data into training, validation, and test sets. The synthetic data should only be added to the training set.
- Classifier Training: Train a classifier (e.g., Support Vector Machine, Artificial Neural Network, Convolutional Neural Network) on two versions of the training set: (1) original data only, and (2) original data + synthetic data.
- Quantitative Assessment: Evaluate both classifiers on the held-out real test set. Compare performance using metrics such as accuracy, F1-score, Area Under the Receiver Operating Characteristic Curve (AUROC), and Dice coefficient (for segmentation) [26] [77] [75].
Protocol 2: Evaluation of Synthetic Data Fidelity and Biological Plausibility
Beyond classification accuracy, the quality of synthetic data must be validated.
I. Statistical Equivalency Testing
- Method: Use robust statistical methods, such as Multivariate Analysis of Variance (MANOVA) on the PC scores, to test for significant differences between the distribution of real and synthetic data [3]. The goal is a non-significant p-value, indicating the synthetic data is not statistically different from the real data.
- Visualization: Create scatter plots of the first two principal components, overlaying real and synthetic data points to visually assess distributional overlap.
II. Expert Validation
- Procedure: Present a shuffled mix of real and synthetic morphological visualizations (e.g., 3D models, wireframes) to domain experts (e.g., marine biologists, paleoanthropologists) for blinded evaluation [26].
- Metrics: Experts rate synthetic samples for overall quality and biological plausibility on a Likert scale. A high validation score (e.g., 87.4% as reported) confirms biological authenticity [26].
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Computational Tools and Reagents for GM Data Augmentation
| Research Reagent / Tool | Function / Description | Application Note |
|---|---|---|
| Homologous Landmarks | 2D/3D points of biological/mathematical significance defining morphology. | Categorized as Type I, II, or III; the foundational data for all subsequent analysis [3]. |
| Generalized Procrustes Analysis (GPA) | Algorithm for superimposing landmark configurations by removing non-shape differences (position, rotation, scale). | Enables direct comparison of shape by aligning specimens in a common coordinate frame [3]. |
| Principal Components Analysis (PCA) | Dimensionality reduction technique converting landmark data into a set of linearly uncorrelated variables (PC scores). | Creates a manageable feature space (ℝn) for statistical modeling and GAN training [3]. |
| Generative Adversarial Network (GAN) | Deep learning framework comprising a Generator and a Discriminator trained adversarially. | Learns the underlying probability distribution of the real GM data to generate novel, realistic synthetic samples [3] [76]. |
| Conditional GAN (CGAN) | GAN variant where generation is conditioned on auxiliary information (e.g., class labels). | Essential for generating synthetic data for specific classes (e.g., a particular fish species or type of tooth mark) [26] [75]. |
| Wasserstein GAN (WGAN-GP) | A GAN variant using the Wasserstein distance with Gradient Penalty as its loss function. | Improves training stability and mitigates mode collapse, leading to higher quality synthetic data [76]. |
| Adaptive Identity Blocks | A novel neural network component that learns to preserve species-invariant morphological features. | Critical for maintaining biological authenticity in generated samples, as demonstrated in fish classification [26]. |
Visualization of Advanced Architectures
Advanced GAN architectures incorporate domain-specific knowledge to enhance output quality. The following diagram illustrates the architecture of an Adaptive Identity-Regularized GAN.
The integration of generative algorithms, particularly GANs, into the geometric morphometrics workflow presents a robust solution to the perennial challenge of small sample sizes. The quantitative data and protocols outlined herein demonstrate that this approach can yield statistically significant improvements in classification accuracy and predictive modeling performance. By adhering to the detailed experimental protocols—encompassing rigorous data preparation, appropriate GAN training, and comprehensive evaluation of both statistical fidelity and biological plausibility—researchers can reliably augment their datasets. The provided "toolkit" and visualization of advanced architectures serve as a foundation for developing more stable and domain-aware generative models, ultimately enhancing the reliability and scope of morphological inferences in evolutionary biology, archaeology, and beyond.
Within the field of geometric morphometrics (GM), which provides a powerful multivariate statistical toolset for the quantitative analysis of form, the challenge of limited and biased fossil records often impedes robust statistical analyses [3]. To overcome issues related to small sample sizes, generative computational learning algorithms, particularly Generative Adversarial Networks (GANs), have been proposed for data augmentation [3]. These algorithms can produce highly realistic synthetic morphological data, helping to improve subsequent statistical or predictive modeling applications [3]. However, the critical question remains: how can researchers ensure that the synthetically generated specimens are not only statistically plausible but also biologically authentic?
The process of expert validation serves as a crucial bridge between computational output and biological meaning. It involves the systematic evaluation of generated morphological data by specialists with deep domain knowledge to assess its realism and adherence to known anatomical principles. This protocol outlines detailed application notes for integrating biological expert evaluation into the assessment of morphological realism for data augmented using generative algorithms, framed within a GM research context.
Experimental Design and Validation Metrics
A rigorous experimental design is paramount for meaningful expert validation. The following table summarizes the key quantitative metrics and scoring systems used to evaluate the performance of generative models and the biological realism of their output.
Table 1: Key Performance and Validation Metrics for Generative Morphometric Models
| Metric Category | Specific Metric | Reported Performance | Interpretation and Biological Significance |
|---|---|---|---|
| Model Performance | Classification Accuracy | 95.1% ± 1.0% (vs. 85.4% baseline) [26] | Measures if synthetic data improves classifier performance; indicates preservation of discriminative features. |
| Expert Quality Scores | Overall Quality Score | 88.7% ± 2.0% [26] | Overall expert rating of synthetic specimen quality and realism. |
| Biological Validation Score | 87.4% ± 1.6% [26] | Expert assessment of biological plausibility and anatomical correctness. | |
| Landmark Precision | Root Mean Square Error (RMSE) | Comparable to state-of-the-art automated methods (e.g., MALPACA) [78] | Quantifies deviation from expert-placed ground-truth landmarks; lower error indicates higher precision. |
| Statistical Analysis | p-value & Effect Size | p < 0.001 with large effect sizes [26] | Determines if improvements due to synthetic data are statistically significant and substantial. |
Detailed Experimental Protocols
Protocol 1: Implementing an Adaptive Identity-Regularized GAN for Morphological Data Augmentation
This protocol is adapted from a study that demonstrated significant improvements in fish classification and segmentation by using a GAN with biological constraints [26].
1. Principle and Application: This method involves training a novel GAN architecture that integrates adaptive identity blocks and species-specific loss functions. It is designed for augmenting GM datasets where preserving species-invariant morphological features (e.g., specific landmark configurations) is critical, while still introducing controlled phenotypic variations.
2. Reagents and Computational Tools:
- Hardware: GPU-accelerated computing station.
- Software: Python programming environment with deep learning frameworks (e.g., TensorFlow, PyTorch).
- Data: A curated dataset of landmark coordinates or 3D mesh models derived from biological specimens.
3. Step-by-Step Procedure: 1. Network Architecture Configuration: * Implement the generator network with integrated adaptive identity blocks. These blocks are designed to learn and preserve critical species-identifying morphological features during the generation process [26]. * Implement the discriminator network with enhanced, multi-scale feature extraction capabilities to better distinguish authentic and synthetic specimens. 2. Loss Function Formulation: * Develop a species-specific loss function that incorporates morphological constraints and taxonomic relationships. This function should include terms for: * Morphological consistency: Ensuring generated shapes fall within a biologically plausible range. * Phylogenetic relationship constraints: Encouraging that variations respect known evolutionary relationships. * Feature preservation: Directly penalizing the loss of key diagnostic features [26]. 3. Two-Phase Training Methodology: * Phase 1 (Feature Preservation): Train the model to establish stable identity mappings, prioritizing the accurate reconstruction of input features. * Phase 2 (Controlled Variation): Introduce controlled morphological variations for effective data augmentation, balanced against the preservation constraints from Phase 1 [26]. 4. Synthetic Data Generation: * Use the trained generator to produce synthetic landmark data or 3D models. * Apply adaptive sampling strategies to prioritize the augmentation of rare or underrepresented species in the training set.
Protocol 2: Expert Evaluation of Synthetic Morphological Realism
This protocol outlines a structured process for biological experts to qualitatively and quantitatively assess the output of generative models.
1. Principle and Application: To validate the biological authenticity of synthetically generated morphometric data through systematic scoring by domain specialists. This process is essential for ensuring that augmented data used in downstream analyses (e.g., evolutionary morphology, taxonomic classification) is scientifically valid.
2. Reagents and Computational Tools:
- Software: Visualization software for 3D morphometrics (e.g., 3D Slicer with SlicerMorph extension [78]).
- Data: A mixed set of real and synthetically generated specimens (landmarks or 3D models), presented to experts in a blinded manner.
- Materials: Standardized scoring rubrics and electronic data capture forms.
3. Step-by-Step Procedure: 1. Expert Panel Assembly: * Recruit a panel of at least three biological specialists with expertise in the taxonomy and anatomy of the group under study. 2. Blinded Evaluation Setup: * Prepare a randomized set of specimens, including both real and synthetic data, with all identifiers removed. The proportion of synthetic specimens should not be disclosed to the experts. 3. Structured Scoring: * Provide experts with a standardized scoring rubric and ask them to evaluate each specimen on several criteria using a Likert scale (e.g., 1-5). Key criteria should include: * Anatomical Plausibility: Are all structures present and correctly proportioned? * Landmark Validity: Are the defined landmarks placed in biologically homologous and meaningful positions? * Overall Realism: Does the specimen appear as a realistic, naturally occurring organism? [26] 4. Statistical Consolidation of Scores: * Collect the scores and calculate average ratings for each synthetic specimen and each criterion. * Compute overall summary metrics, such as the Overall Quality Score and Biological Validation Score, as reported in Table 1 [26]. 5. Qualitative Feedback Session: * Conduct a debriefing session with the expert panel to collect qualitative feedback on the failures and successes of the synthetic specimens, noting any recurring implausible features.
The following diagram illustrates the core workflow and logical relationships of the expert validation process:
The Scientist's Toolkit: Essential Research Reagents and Materials
The following table details key computational tools and conceptual frameworks essential for conducting research in geometric morphometric data augmentation and its validation.
Table 2: Key Research Reagents and Computational Tools for GM Data Augmentation
| Tool/Reagent | Type | Function and Application in GM Research |
|---|---|---|
| Generative Adversarial Network (GAN) [3] [26] | Computational Algorithm | A deep learning framework comprising generator and discriminator networks used to produce synthetic morphological data that is statistically similar to the training set. |
| Adaptive Identity Block [26] | Novel Neural Network Component | A module integrated into a GAN to dynamically preserve species-specific, invariant morphological features during the generation of synthetic specimens. |
| Species-Specific Loss Function [26] | Algorithmic Constraint | A customized function that incorporates taxonomic knowledge and morphological constraints into the model's training to ensure biological plausibility of outputs. |
| 3D Slicer / SlicerMorph [78] | Software Platform | An open-source software extension used for the visualization, analysis, and pre-processing of 3D biological morphology data, including landmark digitization. |
| Functional Map (FMap) Framework [78] | Geometry Processing Method | An approach for establishing dense correspondences between 3D biological shapes, which can be used to automate and standardize landmark placement. |
| Expert Validation Rubric | Assessment Protocol | A structured scoring guide used by biological domain experts to quantitatively assess the realism and plausibility of synthetically generated morphological data. |
Conclusion
Generative algorithms, particularly GANs, present a transformative approach to overcoming the pervasive challenge of data scarcity in geometric morphometrics for biomedical research. By generating high-fidelity, biologically plausible synthetic data, these methods significantly enhance the robustness of statistical analyses, improve classification model accuracy, and enable more reliable predictive modeling in drug discovery. Key takeaways include the superiority of biologically-informed GAN architectures that incorporate domain-specific constraints, the critical need for robust statistical validation frameworks, and the demonstrated capacity of synthetic data to reduce overfitting. Future directions should focus on developing standardized validation protocols specific to biomedical applications, creating more adaptable models for highly heterogeneous cell populations or tissue morphologies, and establishing clear regulatory pathways for the use of synthetic data in clinical trial support and diagnostic development. As these technologies mature, they promise to accelerate biomarker discovery, enhance digital pathology, and provide a more data-rich foundation for understanding complex morphological changes in disease and treatment.
References
- 1. Geometric Morphometrics - The Polly Lab [https://www.pollylab.org/courses/geometric-morphometrics]
- 2. Geometric Morphometrics Applied to Biological Structures [https://www.mdpi.com/journal/animals/special_issues/geometric_morphometrics_biological_structures]
- 3. Geometric Morphometric Data Augmentation Using ... [https://www.mdpi.com/2076-3417/10/24/9133]
- 4. Thirty years of geometric morphometrics - PubMed Central - NIH [https://pmc.ncbi.nlm.nih.gov/articles/PMC9545184/]
- 5. Applying Geometric Morphometrics to Digital ... [https://pubmed.ncbi.nlm.nih.gov/31823240/]
- 6. Geometric Morphometric Data Augmentation Using Generative ... [https://agris.fao.org/search/en/providers/122436/records/675aa3310ce2cede71cc7a27]
- 7. Assessing the application of landmark-free morphometrics to ... [https://bmcecolevol.biomedcentral.com/articles/10.1186/s12862-025-02377-9]
- 8. The use of the geometric morphometric method to illustrate ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7568715/]
- 9. 2.4. Geometric morphometrics and visualisation [https://bio-protocol.org/exchange/minidetail?id=8433802&type=30]
- 10. Visualizations in geometric morphometrics: how to read ... [http://www.italian-journal-of-mammalogy.it/Visualizations-in-geometric-morphometrics-how-to-read-and-how-to-make-graphs-showing,77239,0,2.html]
- 11. Adaptive identity-regularized generative adversarial networks ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12559437/]
- 12. Data Augmentation: The Ultimate Guide for 2025 [https://www.ultralytics.com/blog/the-ultimate-guide-to-data-augmentation-in-2025]
- 13. Geometric Morphometric Data Augmentation using ... [https://www.preprints.org/manuscript/202011.0696/v1]
- 14. Testing the reliability of geometric morphometric and ... [https://www.sciencedirect.com/science/article/pii/S2666033425000048]
- 15. Generative deep learning for data generation in natural ... [https://link.springer.com/article/10.1007/s10462-024-10764-9]
- 16. A Comprehensive Survey on Data Augmentation [https://arxiv.org/html/2405.09591v4]
- 17. Enhancing soil organic carbon estimation with generative ... [https://www.nature.com/articles/s41598-025-24236-9]
- 18. Diffeomorphic transforms for data augmentation of highly ... [https://www.sciencedirect.com/science/article/pii/S0169260722001614]
- 19. Advancing drug development with “Fit-for-Purpose” modeling ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12436579/]
- 20. What are Generative Adversarial Networks (GANs)? [https://www.ibm.com/think/topics/generative-adversarial-networks]
- 21. A Systematic Review of GANs for Threat Detection and ... [https://arxiv.org/html/2509.20411v2]
- 22. A Comprehensive guide to Generative Adversarial ... [https://www.sciencedirect.com/science/article/pii/S0957417424007176]
- 23. A Full-Spectrum Generative Lead Discovery (FSGLD) Pipeline ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12136187/]
- 24. Conditional GAN performs better than orthopedic surgeon in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12265285/]
- 25. Conditional generative adversarial network for ... [https://www.sciencedirect.com/science/article/pii/S0957417425016975]
- 26. Adaptive identity-regularized generative adversarial ... [https://www.nature.com/articles/s41598-025-21870-1]
- 27. Deep Learning Outperforms Geometric Morphometrics for ... [https://archaeo.peercommunityin.org/PCIArchaeology/articles/rec?id=502]
- 28. Graph‐Regularized Manifold‐Aware Conditional Wasserstein ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12358810/]
- 29. A generative framework for enhancing drug target ... [https://www.nature.com/articles/s41598-025-01589-9]
- 30. Breaking constraints: The development and evolution of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9542103/]
- 31. Advances in Geometric | Evolutionary Biology Morphometrics [https://link.springer.com/article/10.1007/s11692-009-9055-x]
- 32. Prediction of cellular morphology changes under ... [https://www.nature.com/articles/s41467-025-63478-z]
- 33. Leaf Morphology, Taxonomy and Geometric ... Morphometrics [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0025630]
- 34. Deep learning-driven automated mitochondrial segmentation for analysis of complex transmission electron microscopy images | Scientific Reports [https://www.nature.com/articles/s41598-025-03311-1]
- 35. Ultrastructural Morphometry of Mitochondria: Comparison Between Conventional Operator-Dependent and Artificial Intelligence (AI)-Operated Machine Learning Methods - PubMed [https://pubmed.ncbi.nlm.nih.gov/40156316/]
- 36. Methods for imaging mammalian mitochondrial morphology: a prospective on MitoGraph - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC6322684/]
- 37. AI Diffusion Model-Based Technology for Automating the ... [https://www.mdpi.com/2227-7080/13/4/127]
- 38. Deep learning based domain adaptation for mitochondria ... [https://www.sciencedirect.com/science/article/pii/S0169260722003315]
- 39. Data-augmented machine learning for personalized ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12624012/]
- 40. Generative AI Boosts Mitochondrial Targeting Tools [https://www.miragenews.com/generative-ai-boosts-mitochondrial-targeting-1454653/]
- 41. Guidelines for a Morphometric Analysis of Prokaryotic and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8699492/]
- 42. Inside ELRIG's Drug Discovery 2025 [https://www.drugtargetreview.com/article/190237/inside-elrigs-drug-discovery-2025/]
- 43. Data Flow Diagram Examples Symbols, Types, and Tips [https://www.lucidchart.com/blog/data-flow-diagram-tutorial]
- 44. Common Problems | Machine Learning [https://developers.google.com/machine-learning/gan/problems]
- 45. GAN convergence and stability: eight techniques explained [https://davidleonfdez.github.io/gan/2022/05/17/gan-convergence-stability.html]
- 46. Stabilizing GANs with Prediction [https://www.cs.umd.edu/~tomg/projects/stable_gans/]
- 47. VAE-QWGAN: addressing mode collapse in quantum ... [https://link.springer.com/article/10.1007/s42484-025-00314-z]
- 48. A Visual Intuition For Regularization in Deep Learning [https://medium.com/data-science/a-visual-intuition-for-regularization-in-deep-learning-fe904987abbb]
- 49. Comparative Deep Learning Analysis of Regularization ... [https://www.preprints.org/manuscript/202511.0501]
- 50. A Comparison of Regularization Techniques in Deep ... [https://www.mdpi.com/2073-8994/10/11/648]
- 51. Morphometric similarity network-based graph convolutional ... [https://www.nature.com/articles/s41598-025-19894-8]
- 52. Comparison of Deep Learning With Multiple Machine ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5741413/]
- 53. Enhancing prediction accuracy for high-dimensional small- ... [https://www.sciencedirect.com/science/article/abs/pii/S1568494625001371]
- 54. LSH-GAN enables in-silico generation of cells for small ... [https://www.nature.com/articles/s42003-022-03473-y]
- 55. Recruiting a skeleton crew-Methods for simulating and ... [https://pubmed.ncbi.nlm.nih.gov/37199044/]
- 56. SMOGAN: Synthetic Minority Oversampling with GAN ... [https://arxiv.org/html/2504.21152v2]
- 57. Implementation of a Generative AI Algorithm for Virtually ... [https://www.mdpi.com/2076-3417/14/11/4570]
- 58. Beyond the Hype: Why Synthetic Data Falls Short ... [https://www.rgnmed.com/post/beyond-the-hype-why-synthetic-data-falls-short-in-healthcare-and-how-regenmed-circles-closes-the-gap]
- 59. Synthetic data for ML: the game-changer in training for 2025 [https://cleverx.com/blog/synthetic-data-for-ml-the-game-changer-in-training-for-2025]
- 60. Master Synthetic Data Validation to Avoid AI Failure [https://galileo.ai/blog/validating-synthetic-data-ai]
- 61. Innovative data augmentation strategy for deep learning on ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12297658/]
- 62. AndroGen: Open-source synthetic data generation for ... [https://www.sciencedirect.com/science/article/pii/S0169260725005486]
- 63. Reducing Instability in Synthetic Data Evaluation with a ... [https://arxiv.org/html/2511.16373v1]
- 64. A Framework for Generating Realistic Synthetic Tabular ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12345405/]
- 65. Evaluating the utility of data integration with synthetic ... [https://www.nature.com/articles/s41598-025-01514-0]
- 66. Defining, Reconstructing and Investigating Shape Through a ... [https://journal.caa-international.org/articles/10.5334/jcaa.161]
- 67. Traditional and Artificial Intelligent Methods in Predicting ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12591827/]
- 68. An enhancement of machine learning model performance ... [https://www.nature.com/articles/s41598-025-15019-3]
- 69. A GAN-Based Adaptive Hybrid Resampling Algorithm for ... [https://www.mdpi.com/2079-9292/14/17/3476]
- 70. Comparative analysis of methods used to solve class ... [https://www.sciencedirect.com/science/article/pii/S2666202725002502]
- 71. A Systematic Mapping Study of Generative Adversarial ... [https://arxiv.org/html/2502.16535v1]
- 72. Data Augmentation via Guided Manipulation of GAN's ... [https://pubmed.ncbi.nlm.nih.gov/40889306/]
- 73. A Geometric Morphometrics Approach for Predicting Olfactory ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12565324/]
- 74. A Hybrid Geometric Morphometric Deep Learning Approach for ... [https://www.semanticscholar.org/paper/b4693e891089c74765f34eaa087d253a77c913c8]
- 75. Conditional-GAN Based Data Augmentation for Deep ... [https://www.frontiersin.org/journals/big-data/articles/10.3389/fdata.2021.659146/full]
- 76. GAN-based data augmentation for transcriptomics [https://pmc.ncbi.nlm.nih.gov/articles/PMC10311334/]
- 77. Evaluating synthetic neuroimaging data augmentation for ... [https://www.sciencedirect.com/science/article/pii/S2667242123022881]
- 78. Leveraging Descriptor Learning and Functional Map-based ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11142217/]