AlexNet vs. ResNet50 for Low-Quality Image Classification: A Comparative Analysis for Biomedical Research
This article provides a comprehensive comparison of the AlexNet and ResNet50 convolutional neural network architectures for classifying low-quality images, a common challenge in biomedical and clinical research.
AlexNet vs. ResNet50 for Low-Quality Image Classification: A Comparative Analysis for Biomedical Research
Abstract
This article provides a comprehensive comparison of the AlexNet and ResNet50 convolutional neural network architectures for classifying low-quality images, a common challenge in biomedical and clinical research. We explore the foundational principles of both models, detail methodological approaches for handling degraded images, address key troubleshooting and optimization strategies, and present a validation framework for performance comparison. Aimed at researchers and drug development professionals, this analysis synthesizes technical insights with practical applications to guide the selection and implementation of robust image classification models in resource-constrained or data-limited environments, such as those involving low-resolution medical imaging or historical clinical data.
AlexNet and ResNet50: Architectural Foundations and Their Relevance to Low-Quality Images
Historical Context and Architectural Breakdown
The year 2012 marked a turning point for deep learning and computer vision with the introduction of AlexNet, a convolutional neural network (CNN) developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton [1] [2]. It decisively won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) by achieving a top-5 error rate of 15.3%, dramatically outperforming the second-place model's error rate of 26.2% [1] [3] [2]. This victory demonstrated the untapped potential of deep convolutional networks for large-scale visual recognition tasks and catalyzed a new wave of AI research [1] [3].
AlexNet's architecture, while simple by today's standards, introduced several key innovations that became standard for subsequent deep learning models. The network consists of eight learned layers: five convolutional and three fully-connected layers [1] [4]. The architecture processes input images of size 227x227x3 and culminates in a 1000-way SoftMax output layer corresponding to the ImageNet object categories [1] [4]. A notable implementation detail was the splitting of the network across two NVIDIA GTX 580 GPUs due to memory constraints, which also allowed for a specialized pipeline that increased training efficiency [1].
The following diagram illustrates the core architecture and data flow of AlexNet.
Core Innovations of AlexNet
AlexNet's success was not merely due to its depth but its strategic incorporation of several then-novel techniques which are now foundational in deep learning.
- ReLU Activation Function: AlexNet replaced traditional saturating activation functions like
tanhor sigmoid with the Rectified Linear Unit (ReLU), which simply outputsmax(0, x)[5] [3] [2]. This non-saturating nature drastically accelerated the convergence of stochastic gradient descent, as networks with ReLUs could achieve a 25% training error rate six times faster than equivalent networks withtanhunits [5] [2]. - Dropout Regularization: To combat overfitting in the large fully-connected layers, AlexNet employed dropout [1] [3] [2]. During training, this technique randomly "drops" each hidden neuron with a probability of 0.5, preventing complex co-adaptations of features and forcing the network to learn more robust representations [5] [3].
- Overlapping Pooling: The network used max-pooling layers, but with a twist: the pooling regions overlapped, with a pool size of 3×3 and a stride of 2 [5] [3]. This overlapping design reduced the top-1 and top-5 error rates by 0.4% and 0.3%, respectively, and provided a slight improvement in translation invariance while making overfitting less likely [5] [3].
- GPU Acceleration: Training a network with over 60 million parameters was made feasible by leveraging Graphics Processing Units (GPUs) for parallel computation [1] [2]. The model was trained on two NVIDIA GTX 580 GPUs for five to six days, a feat that would have been prohibitively slow on CPUs at the time [1].
AlexNet vs. ResNet-50: A Comparative Analysis for Image Classification
While AlexNet was a pioneer, the field has advanced significantly with architectures like ResNet-50, developed by Microsoft Research in 2015 [6] [7] [8]. A direct comparison is essential for researchers, particularly when considering applications like low-quality image classification where computational efficiency and robustness are key.
Table 1: High-Level Architectural and Philosophical Comparison
| Feature | AlexNet | ResNet-50 |
|---|---|---|
| Core Philosophy | Pioneering, relatively deep CNN for its time [2] | Very deep network enabled by residual learning to prevent degradation [6] [8] |
| Depth | 8 layers (5 Conv, 3 FC) [1] | 50 layers [7] [8] |
| Key Innovation | ReLU, Dropout, GPU training [1] [3] [2] | Skip connections / residual blocks [6] [7] |
| Solution to Vanishing Gradients | ReLU activation function [5] [2] | Identity skip connections act as gradient highways [6] [7] [8] |
| Primary Regularization | Dropout [1] [3] | Batch Normalization (within residual blocks) [8] |
| Computational Cost | Lower (∼1.43 GFLOPs forward pass) [1] | Higher due to greater depth [8] |
Table 2: Quantitative Performance and Efficiency Comparison
| Aspect | AlexNet | ResNet-50 |
|---|---|---|
| ILSVRC Top-5 Error | 15.3% [1] [2] | ~5-7% (Surpassed human-level performance of 5.1%) [7] |
| Parameters | ~60 million [1] | ~25 million [8] |
| Computational Efficiency | More efficient for simpler tasks [9] | More efficient per parameter for complex tasks [8] |
| Performance on Low-Quality/Simple Data | Can outperform deeper models when data is limited or low-quality [9] | Can underperform simpler models if task/data is not complex enough to require its depth [6] |
The most significant architectural difference is ResNet-50's use of residual blocks with skip connections. These connections bypass one or more layers by performing an identity mapping and adding their output to the output of the stacked layers [6] [7]. This solves the vanishing gradient problem more effectively for extremely deep networks by allowing gradients to flow directly backward through the skip connections, and it enables the network to learn residual functions F(x) = H(x) - x instead of the complete, unreferenced mapping H(x) [7] [8].
Experimental Insights and Performance in Applied Research
Empirical evidence from recent studies provides critical context for model selection. A 2025 study on automated feature recognition in pedestrian crash diagrams offers a compelling comparison in a challenging, real-world image classification scenario [9].
Experimental Protocol:
- Objective: To classify multiple features (e.g., intersection type, road type) from low-quality, hand-sketched pedestrian crash diagrams [9].
- Models: A comprehensive evaluation of VGG-19, AlexNet, and ResNet-50 was conducted [9].
- Dataset: 5,437 pedestrian crash diagrams from Michigan UD-10 police reports [9].
- Training: Models were evaluated using metrics like accuracy and F1-score to assess their reliability in classifying multiple pedestrian crash features [9].
Key Finding: In this specific task, AlexNet consistently surpassed ResNet-50 and VGG-19, achieving the highest accuracy and F1-score [9]. The study concluded that AlexNet also emerged as the most computationally efficient model, a crucial advantage in resource-constrained environments [9]. This demonstrates that for certain non-natural image datasets, particularly those with lower complexity or quality, a simpler, well-regularized model like AlexNet can be more effective and efficient than a much deeper, more complex architecture like ResNet-50 [9].
Conversely, in highly complex and data-rich domains like medical imaging, ResNet-50's depth provides a clear advantage. For instance, in a 2025 benchmark study on breast cancer histopathological image classification, ResNet-50 achieved a near-perfect AUC (Area Under the Curve) of 0.999 in binary classification tasks, performing on par with more recent state-of-the-art models [10].
The Scientist's Toolkit: Research Reagent Solutions
For researchers aiming to implement or experiment with these architectures, the following table details the essential "research reagents" and their functions based on the original models and subsequent studies.
Table 3: Essential Research Reagents and Materials
| Reagent / Material | Function in the Experiment |
|---|---|
| ImageNet Dataset | Large-scale benchmark dataset (~1.2 million training images, 1000 categories) for pre-training and evaluating model generalizability [1] [3]. |
| NVIDIA GPUs (e.g., GTX 580) | Provides parallel computational power essential for training deep neural networks in a feasible timeframe [1] [2]. |
| Stochastic Gradient Descent (SGD) with Momentum | Optimization algorithm that updates weights using small, random batches of data; momentum helps accelerate convergence and dampen oscillations [1] [3]. |
| Data Augmentation Pipeline (Cropping, Flipping, Color Jittering) | Artificially expands the training dataset and encourages invariance to transformations, which is crucial for preventing overfitting and improving robustness, especially with low-quality images [1] [5] [3]. |
| Dropout Regularization | Prevents overfitting in fully-connected layers by randomly disabling neurons during training, forcing the network to learn redundant, robust representations [1] [3]. |
| Local Response Normalization (LRN) | A form of lateral inhibition intended to encourage competition for big activities amongst neuron outputs computed using different kernels [1] [3]. |
| Skip (Residual) Connections | A core component of ResNet-50 that mitigates the vanishing gradient problem, enabling the stable training of very deep networks [6] [7] [8]. |
| Batch Normalization | Used in ResNet-50 to normalize the inputs to each layer, reducing internal covariate shift and accelerating training [8]. |
AlexNet's legacy as the catalyst for the modern deep learning revolution is secure. Its core innovations—ReLU, dropout, and efficient GPU utilization—established the foundational toolkit for building and training deep CNNs [1] [3] [2]. While later architectures like ResNet-50 have since surpassed its raw accuracy on benchmark datasets by introducing revolutionary ideas like skip connections, AlexNet's relative simplicity and computational efficiency make it a surprisingly potent and pragmatic choice for specific research applications [9]. This is particularly true for tasks involving lower-quality image data, limited dataset sizes, or constrained computational resources, where its performance can rival or even exceed that of more complex models [9]. For any researcher in computational vision or related fields, understanding the architecture, innovations, and comparative position of AlexNet remains indispensable.
ResNet50, a 50-layer deep convolutional neural network (CNN), represents a pivotal advancement in deep learning architecture that fundamentally addressed the vanishing gradient problem plaguing deep neural networks. Developed by researchers at Microsoft Research in 2015, ResNet introduced the concept of residual learning that enabled the successful training of networks with significantly greater depth than previously possible [11] [8]. The "50" in its name denotes the total number of layers, which include convolutional, pooling, fully connected layers, and most importantly, residual blocks that utilize skip connections [8]. This architectural innovation allowed gradients to flow directly through the network via shortcut connections, preventing them from becoming excessively small during backpropagation and thus enabling the training of networks with hundreds or even thousands of layers [11] [12].
The significance of ResNet50 extends beyond its technical specifications to its profound impact on the field of computer vision. Prior to ResNet, deeper neural networks often exhibited performance degradation - where adding more layers反而 led to higher training and test errors, contrary to theoretical expectations [11]. This phenomenon was not caused by overfitting but rather by the fundamental difficulty of optimizing deeper networks using gradient-based methods. ResNet50's residual blocks solved this problem by learning residual mappings rather than complete transformations, making it substantially easier for the network to learn identity functions when optimal [11] [8]. This breakthrough established ResNet50 as a cornerstone architecture that continues to influence modern deep learning approaches across diverse applications from medical image analysis to autonomous driving [8].
Architectural Comparison: ResNet50 vs. AlexNet
Fundamental Structural Differences
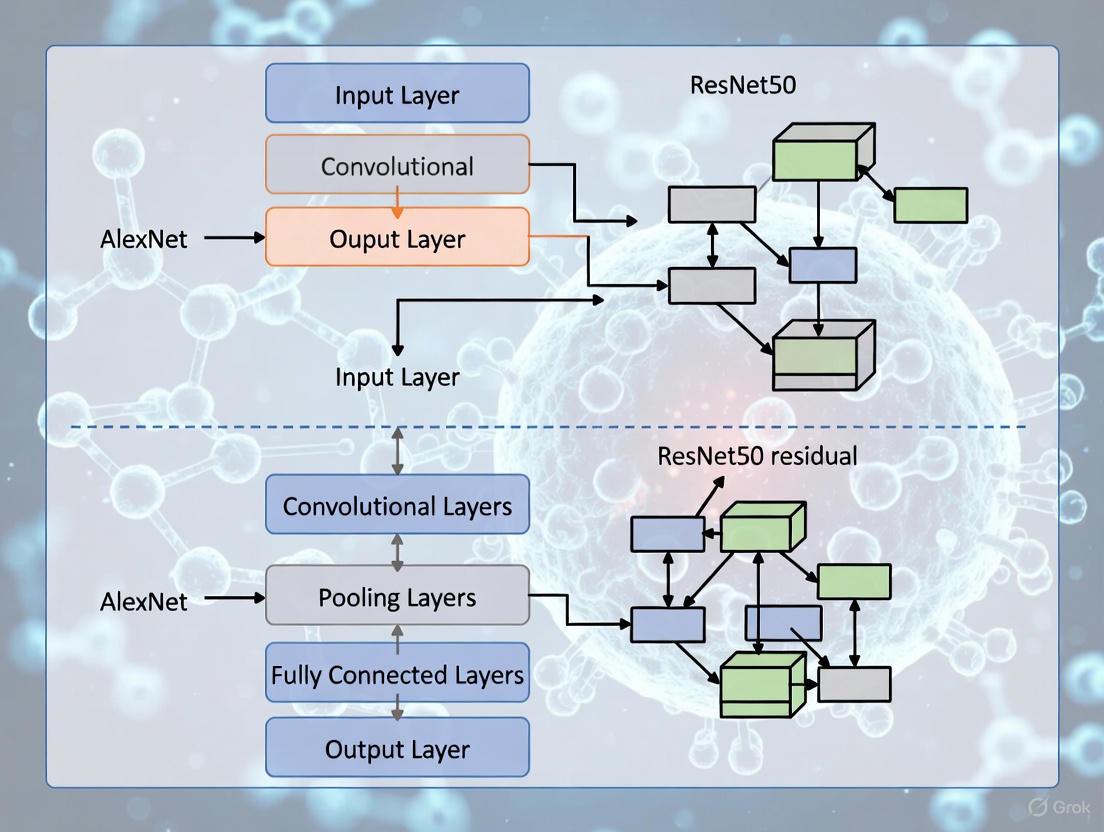
AlexNet and ResNet50 represent two distinct generations of deep learning architectures with fundamentally different approaches to network design. AlexNet, the 2012 ImageNet competition winner, consists of 8 learned layers - 5 convolutional layers and 3 fully-connected layers - with approximately 60 million parameters [5] [1]. It pioneered the use of ReLU activation functions instead of tanh, utilized overlapping max-pooling, and employed dropout regularization to prevent overfitting [5] [1]. Notably, due to computational constraints of the era, the network was split across two GPUs, with specialized layers that enabled model parallelism [1].
In contrast, ResNet50 employs a substantially deeper architecture comprising 50 layers organized around residual blocks [8]. The key innovation lies in these residual blocks, which utilize skip connections (also called shortcut connections) that allow the input to bypass one or more layers and be added to the output of those layers [11]. This creates a fundamental architectural difference: while AlexNet must learn complete transformations at each layer, ResNet50 learns residual functions expressed as F(x) = H(x) - x, where H(x) is the desired underlying mapping and x is the input to the blocks [11]. This residual learning framework significantly eases the optimization process for deep networks.
Core Innovation: Residual Learning in ResNet50
The residual block represents ResNet50's core innovation, specifically implemented through bottleneck residual blocks that consist of three convolutional layers: a 1×1 convolution for dimensionality reduction, a 3×3 convolution for feature extraction, and another 1×1 convolution for dimensionality restoration [12] [8]. This bottleneck design optimizes computational efficiency while maintaining representational power. The skip connection that bypasses these three layers enables the gradient to flow directly backward through the network during training, effectively mitigating the vanishing gradient problem that hampered previous deep architectures [12].
AlexNet's comparatively simpler structure lacks these identity connections, which explains why increasing its depth beyond 8 layers would have led to diminishing returns. The ResNet50 architecture can be conceptually summarized as: Input → Initial Convolution and Pooling → Stage 1 Residual Blocks (3) → Stage 2 Residual Blocks (4) → Stage 3 Residual Blocks (6) → Stage 4 Residual Blocks (3) → Average Pooling → Fully Connected Layer → Output [8]. Each stage increases the number of filters while reducing spatial dimensions, following the common pattern of CNNs while maintaining gradient flow through skip connections at every stage.
Table 1: Architectural Comparison Between AlexNet and ResNet50
| Feature | AlexNet | ResNet50 |
|---|---|---|
| Depth | 8 layers | 50 layers |
| Key Innovation | ReLU, Dropout, GPU parallelism | Residual learning with skip connections |
| Core Building Block | Convolutional + Pooling layers | Bottleneck residual block |
| Parameter Count | ~60 million | ~25 million |
| Activation Function | ReLU | ReLU |
| Skip Connections | No | Yes |
| Training Efficiency | Suffers from vanishing gradients in deeper variants | Maintains gradient flow even in very deep networks |
Experimental Performance Comparison
Quantitative Performance Metrics
Multiple empirical studies have directly compared the performance of AlexNet and ResNet50 across various domains and datasets. In a comprehensive study classifying traditional Indonesian food images (24 categories, >4,000 images), ResNet50 consistently outperformed AlexNet across all evaluation metrics [13]. The researchers employed 5-fold cross-validation and standard evaluation metrics, with ResNet50 achieving an average accuracy of 92% compared to AlexNet's 86% [13]. ResNet50 also demonstrated superior precision, recall, and F1-score, indicating its enhanced capability in learning visual patterns from diverse food images [13].
Another revealing comparison comes from pedestrian crash diagram analysis, where both architectures were evaluated on their ability to classify features like intersection type, road type, and crosswalk presence from crash report diagrams [9]. Interestingly, this study found AlexNet outperforming ResNet50, achieving higher accuracy and F1-score while also demonstrating superior computational efficiency [9]. This outcome suggests that task complexity and data characteristics significantly influence which architecture performs better, with AlexNet potentially maintaining advantages for certain specialized applications with limited computational resources.
Table 2: Experimental Performance Comparison Across Different Applications
| Application Domain | Dataset Characteristics | AlexNet Performance | ResNet50 Performance | Key Findings |
|---|---|---|---|---|
| Traditional Food Classification [13] | 24 categories, >4,000 images | 86% accuracy | 92% accuracy | ResNet50 superior for complex visual patterns |
| Pedestrian Crash Diagram Analysis [9] | 5,437-609 diagrams, 6 feature types | Highest accuracy & F1-score | Lower accuracy | AlexNet more efficient for certain specialized tasks |
| ImageNet Classification [1] [8] | 1,000 categories, 1.2M images | 15.3% top-5 error (2012) | ~5% top-5 error (later) | ResNet50 establishes new performance benchmarks |
Performance on Low-Quality and Low-Resolution Images
The classification of low-quality and low-resolution images presents particular challenges that differently impact architectural performance. Research into foundation models' performance on low-resolution images has revealed that model size positively correlates with robustness to resolution degradation [14]. This finding generally favors deeper architectures like ResNet50, though the quality of the pre-training dataset appears more crucial than its size in maintaining performance under resolution reduction [14].
For low-quality QR code images affected by various noise types, deeper architectures like XceptionNet achieved the highest accuracy (87.48%), while a simpler CNN with fewer layers attained competitive performance (86.75%) [15]. This suggests that for certain types of image degradation, extremely deep architectures may offer diminishing returns compared to appropriately sized networks. ResNet50's residual connections theoretically help maintain feature representation integrity even with quality degradation, though the specific noise characteristics significantly influence practical performance.
Experimental Protocols and Methodologies
Standardized Training and Evaluation Frameworks
The experimental comparisons between AlexNet and ResNet50 follow rigorous methodologies to ensure valid performance assessments. In the traditional food image classification study, researchers implemented a comprehensive preprocessing pipeline where all images were resized to 224×224 pixels and normalized according to each model's standard input format [13]. The training incorporated data augmentation techniques including random cropping, flipping, and color jittering to enhance variation and prevent overfitting [13]. The critical methodological aspect was the use of 5-fold cross-validation, ensuring robust performance estimates rather than relying on a single train-test split [13].
For both architectures, transfer learning approaches were typically employed, leveraging models pre-trained on the ImageNet dataset and fine-tuning them on the target domain datasets. The training generally utilized SGD with momentum (0.9) and used learning rate scheduling where the learning rate was reduced when validation error plateaued [13] [1]. These standardized protocols enable fair comparisons between architectures by eliminating training methodology as a confounding variable.
Specialized Methodologies for Low-Quality Image Research
Research focusing on low-quality image classification requires specialized methodologies to properly assess model robustness. Studies typically create degraded image datasets through systematic downsampling and introduction of various noise types (speckle, salt & pepper, Gaussian, etc.) [14] [15]. Evaluation metrics must then account for both absolute performance and robustness - the degree to which performance degrades with reducing image quality.
Recent work has proposed specialized metrics like Weighted Aggregated Robustness (WAR) to address limitations of previous metrics that could produce misleading scores when models perform poorly on challenging datasets [14]. The WAR metric provides a more balanced evaluation by considering performance drops across datasets more fairly, offering better assessment of model behavior under quality degradation [14]. For low-resolution specific research, methodologies often include benchmarking across multiple resolution levels and analyzing how performance degrades non-linearly with resolution reduction.
The Scientist's Toolkit: Essential Research Reagents
Table 3: Essential Research Materials and Computational Resources
| Research Reagent | Function/Purpose | Example Specifications |
|---|---|---|
| Image Datasets | Training and evaluation基准 | ImageNet (1.2M images, 1K categories) [1], Custom domain-specific datasets [13] |
| Data Augmentation Pipeline | Increases dataset diversity and size | Random cropping (224×224), horizontal flipping, color jittering [13] [5] |
| GPU Acceleration | Enables practical training of deep models | NVIDIA GTX 580 (AlexNet era) to modern GPUs with >1000 TFLOPS [16] |
| Deep Learning Frameworks | Model implementation and training | TensorFlow, Keras, PyTorch with CUDA support [11] |
| Evaluation Metrics | Quantifies model performance | Accuracy, Precision, Recall, F1-score [13], Top-5 error rate [1] |
| Cross-Validation Protocols | Ensures robust performance estimation | 5-fold cross-validation [13] |
Critical Analysis and Research Implications
Contextual Performance Advantages
The comparative analysis reveals that neither AlexNet nor ResNet50 universally outperforms the other across all scenarios. ResNet50 demonstrates clear superiority for complex visual recognition tasks requiring hierarchical feature learning, as evidenced by its substantial advantage in traditional food classification (92% vs. 86% accuracy) [13]. This performance gap widens with increasing task complexity and dataset size, consistent with ResNet50's architectural advantages for deep hierarchical representation learning.
However, AlexNet maintains competitive performance for certain specialized applications, particularly those with limited data or specific pattern recognition requirements. In pedestrian crash diagram analysis, AlexNet surprisingly achieved higher accuracy and F1-score than ResNet50 while also being computationally more efficient [9]. This suggests that researchers must consider the specific problem characteristics when selecting architectures, as simpler models may sometimes outperform more sophisticated alternatives for specialized domains.
Implications for Low-Quality Image Classification Research
For low-quality image classification - the central theme of the broader thesis context - several important implications emerge from this analysis. First, the residual connections in ResNet50 theoretically provide advantages for maintaining feature representation integrity as image quality degrades, though empirical evidence varies by domain. Second, the finding that pre-training dataset quality matters more than size for low-resolution robustness [14] suggests that careful selection of pre-training strategies may be more important than architectural choices alone.
Recent research into low-resolution robustness has led to innovative approaches like LR-TK0 (Low-Resolution Zero-Shot Tokens), which introduces low-resolution-specific tokens to enhance model robustness without altering pre-trained weights [14]. Such approaches could potentially be combined with ResNet50's architectural advantages to create more robust classifiers for low-quality images across various application domains, including medical imaging, remote sensing, and historical document analysis.
The comprehensive comparison between AlexNet and ResNet50 reveals a complex performance landscape where architectural advantages interact significantly with application domain characteristics. ResNet50's residual learning framework unquestionably represents a fundamental advancement in deep learning architecture, enabling successfully training of substantially deeper networks and establishing new performance benchmarks across standard computer vision tasks [11] [8]. However, AlexNet's competitive performance in certain specialized applications [9] demonstrates that simpler architectures retain relevance for specific use cases, particularly where computational efficiency or data limitations are primary concerns.
For low-quality image classification research, future work should focus on several promising directions. First, developing specialized residual architectures optimized for different types of image degradation (resolution reduction, noise, compression artifacts) could yield significant performance improvements. Second, exploring how pre-training strategies interact with architectural choices for low-quality images would help establish best practices for this important problem domain. Finally, hybrid approaches that combine ResNet50's strengths with domain-specific preprocessing or attention mechanisms may offer the most promising path forward for robust classification of challenging low-quality images across scientific and industrial applications.
In the field of image-based research, the quality of input data serves as the fundamental determinant of analytical success. For researchers, scientists, and drug development professionals, the challenge of low-quality images is not merely an inconvenience but a significant scientific obstacle that can compromise experimental validity, reduce statistical power, and lead to erroneous conclusions. The proliferation of advanced deep learning architectures like AlexNet and ResNet50 has created unprecedented opportunities for image analysis, yet these models face distinct challenges when processing suboptimal visual data. Understanding the characteristics and sources of image quality degradation is therefore essential for selecting appropriate analytical tools and implementing effective preprocessing strategies.
Image quality assessment (IQA) plays a critical role in automatically detecting and correcting defects in images, thereby enhancing the overall performance of image processing and transmission systems [17]. In research contexts, this extends to ensuring the reliability of analytical outcomes. The process of image generation, transmission, compression, and storage inevitably introduces various forms of distortion [17]. These distortions lead to significant differences between the visual information received by human observers and the original image, potentially resulting in unexpected deviations in practical applications that rely on high-fidelity image processing, such as medical imaging and autonomous driving [17]. This article examines the fundamental challenges posed by low-quality images in research settings and provides a comparative analysis of how AlexNet and ResNet50 architectures perform under these constrained conditions.
Defining Low-Quality Images: Characteristics and Research Impact
Key Characteristics of Low-Quality Research Images
Low-quality images in research environments manifest through several identifiable characteristics that directly impact analytical outcomes. While the specific manifestations vary across domains, five core attributes consistently present challenges for classification algorithms:
Low Resolution and Insufficient Detail: Images with inadequate pixel density fail to capture essential morphological features, particularly problematic for medical and biological imaging where subtle structural variations carry diagnostic significance [18]. Super-resolution techniques aim to address this by improving image quality and resolution to enhance finer details, sharpness, and clarity [18].
Noise and Artifacts: Introduction of visual noise during image acquisition or compression can obscure relevant features. This includes sensor noise in microscopy, compression artifacts in transmitted medical images, and interference in satellite imagery [17].
Poor Lighting and Contrast: Suboptimal illumination conditions during capture create shadows, overexposure, or low contrast, reducing feature discriminability [19]. This is particularly challenging in field research and time-series experiments where lighting control is limited.
Blur and Focus Issues: Motion blur from subject movement or equipment vibration, along with focal inaccuracies, result in loss of edge definition and structural clarity [19]. These issues are common in live-cell imaging and behavioral studies.
Compression Artifacts: Lossy compression algorithms, particularly JPEG, introduce blocking artifacts and spectral distortions that can mimic or obscure genuine image features [20] [21]. This presents significant challenges for telemedicine and collaborative research involving image sharing.
The provenance of research images significantly influences their susceptibility to quality issues. Three primary sources introduce distinct degradation patterns:
Acquisition Limitations: Research constraints often necessitate suboptimal capture conditions. In medical imaging, factors such as limited scan time, spatial coverage, and signal-to-noise ratio (SNR) can result in low-resolution captures [18]. Similarly, laboratory equipment limitations, such as older microscopes or clinical cameras, produce images with inherent quality restrictions.
Processing and Transmission Artifacts: The digital lifecycle of research images introduces multiple degradation opportunities. Common issues include quality loss during analog-to-digital conversion, compression for storage or transmission [17], and format conversions that discard visual information [20]. These challenges are particularly acute in multi-center studies and cloud-based research collaborations.
Subject-Related Challenges: Biological variability and experimental conditions create unique obstacles. Samples with insignificant morphological structural features, strong target correlation, and low signal-to-noise ratio present fundamental classification challenges [22]. Additionally, amorphous structural boundaries in medical images [22] and transparent features in microscopic samples complicate feature extraction.
Table 1: Impact of Image Quality Issues on Research Analysis
| Quality Issue | Primary Sources | Impact on Analysis | Common Research Domains |
|---|---|---|---|
| Low Resolution | Equipment limitations, sampling constraints | Loss of structural details, reduced feature discriminability | Medical MRI [18], Satellite imaging [18] |
| Noise | Sensor limitations, low light conditions | Obscured genuine features, false pattern recognition | Microscopy, Astronomical imaging |
| Compression Artifacts | Storage limitations, transmission requirements | Structural distortions, introduced false edges | Telemedicine, Multi-center trials |
| Blur | Subject motion, focus inaccuracies | Loss of boundary definition, reduced edge clarity | Behavioral studies, Live-cell imaging |
Comparative Analysis of AlexNet and ResNet50 for Low-Quality Image Classification
Architectural Considerations for Quality-Challenged Images
The structural differences between AlexNet and ResNet50 create distinct advantages and limitations when processing low-quality images. AlexNet's pioneering but relatively shallow architecture (8 layers) provides less capacity for learning complex feature representations from degraded images but may offer advantages with smaller datasets [9]. In contrast, ResNet50's deeper architecture (50 layers) with residual connections enables more sophisticated feature extraction through identity mappings that alleviate the vanishing gradient problem in deep networks [23]. This allows ResNet50 to learn more robust representations from quality-challenged images but requires more substantial datasets for effective training [22].
The residual learning framework in ResNet50 is particularly valuable for low-quality image classification as it enables the network to focus on learning residual mappings rather than complete transformations [23]. When processing images with noise or compression artifacts, this approach allows the network to more effectively separate signal from noise. AlexNet's consecutive convolutional and pooling layers lack this refinement, potentially limiting its performance on complex degraded images where learning identity mappings is beneficial [13].
Experimental Performance Comparison
Direct comparative studies reveal significant performance differences between these architectures when handling challenging image data. In classifying traditional Indonesian food images—a task involving significant visual variation and potential quality issues—ResNet50 consistently outperformed AlexNet across all evaluation metrics [13]. ResNet50 achieved an average accuracy of 92%, compared to 86% obtained by AlexNet, demonstrating a 6% absolute improvement [13]. This performance advantage extended to precision, recall, and F1-score metrics, indicating ResNet50's superior ability to extract meaningful patterns from diverse visual data with potential quality limitations.
However, performance relationships are context-dependent. In analyzing pedestrian crash diagrams, which often feature simplified schematic representations rather than rich photographic detail, AlexNet surprisingly achieved the highest accuracy and F1-score, while also demonstrating superior computational efficiency [9]. This suggests that for certain types of lower-complexity schematic images, AlexNet's simpler architecture may provide sufficient representational power without the computational overhead of deeper networks.
Table 2: Experimental Performance Comparison Between AlexNet and ResNet50
| Research Context | AlexNet Performance | ResNet50 Performance | Key Findings | Citation |
|---|---|---|---|---|
| Indonesian Food Classification | 86% accuracy | 92% accuracy | ResNet50 superior for complex visual patterns | [13] |
| Pedestrian Crash Diagrams | Highest accuracy & F1-score | Lower performance than AlexNet | AlexNet superior for schematic images | [9] |
| COVID-19 CT Scan Classification | Not tested | High performance with DenseNet-121 achieving 95.0% accuracy | ResNet variants effective for medical images | [23] |
| Computational Efficiency | Most efficient model | Higher computational demands | AlexNet advantageous with resource constraints | [9] |
Experimental Protocols for Image Classification Performance Evaluation
Standardized Evaluation Methodology
Robust evaluation of image classification performance requires carefully controlled experimental protocols. The Indonesian food image study employed a methodology that can serve as a template for comparative architecture assessment [13]. Researchers combined datasets from multiple sources to create 24 food categories with more than 4,000 total images [13]. Each image underwent systematic preprocessing including resizing to 224×224 pixels, data augmentation to enhance variation, and normalization based on standard input formats of the models [13]. The training process utilized 5-Fold Cross Validation, while performance was evaluated using accuracy, precision, recall, and F1-score metrics [13]. This comprehensive approach ensures fair comparison between architectures and generates statistically meaningful performance measures.
For medical image classification, researchers have employed specialized protocols to address domain-specific challenges. In COVID-19 CT image classification, studies have utilized uniform datasets, data augmentation, hyperparameter training, and consistent optimal weight during the training process to enable meaningful comparison across multiple deep learning models [23]. Performance evaluation typically incorporates five key metrics: accuracy (Acc), recall, precision (Pre), F1-score, and area under the curve (AUC) [23]. This multi-metric approach provides a more nuanced understanding of model performance than accuracy alone, particularly important for medical applications where false negatives and false positives carry different clinical implications.
Addressing Small Dataset Challenges
Research applications frequently face limited data availability, creating particular challenges for deep learning approaches. When working with small sample sets, techniques such as transfer learning, data augmentation, and specialized architectures become essential [22]. Few-shot learning approaches address insufficient data problems through model initialization, transfer learning, and matching networks [22]. Additionally, data augmentation methods can expand effective dataset size, though their ability to enhance the diversity of image features is inherently limited [22].
Advanced architectures specifically designed for limited data scenarios incorporate prior feature knowledge embedding to compensate for small sample sizes [22]. One medical image classification approach combined ResNet50 with Radial Basis Probabilistic Neural Network (RBPNN) to embed diverse prior feature knowledge, using channel cosine similarity attention and dynamic C-means clustering algorithms to select representative sample features from different category subsets [22]. This approach achieved accuracy rates of 85.82% on brain tumor MRI images and 83.92% on cardiac ultrasound images despite data limitations [22].
Research Reagent Solutions: Essential Tools for Image Quality Research
Table 3: Essential Research Tools for Image Classification Experiments
| Tool Category | Specific Examples | Research Function | Application Context |
|---|---|---|---|
| Deep Learning Frameworks | TensorFlow, PyTorch | Model architecture implementation and training | General image classification [18] |
| Image Preprocessing Tools | OpenCV, PIL | Image resizing, normalization, augmentation | Data preparation pipeline [13] |
| Model Architectures | AlexNet, ResNet50 | Core classification engines | Performance comparison [13] [9] |
| Evaluation Metrics | Accuracy, Precision, Recall, F1-score, AUC | Performance quantification | Model validation [13] [23] |
| Medical Imaging Datasets | Brain tumor MRI, Cardiac ultrasound | Domain-specific validation | Medical application testing [22] |
| Data Augmentation Techniques | Rotation, Flip, Zoom, Color adjustment | Dataset expansion and variation | Small sample set improvement [22] |
The challenge of low-quality images in research demands careful consideration of analytical approaches and architectural selection. Through comparative analysis, we have established that ResNet50 generally outperforms AlexNet for complex image classification tasks involving significant visual variation, achieving superior accuracy (92% vs. 86%) in food image classification [13]. However, AlexNet maintains advantages in specific scenarios, particularly with schematic images or computational resource constraints, even achieving highest accuracy in pedestrian crash diagram classification [9].
The selection between these architectures for research applications involving quality-challenged images should consider multiple factors: dataset size and complexity, computational resources, and specific research domain requirements. For medical imaging with limited samples, ResNet variants incorporating specialized enhancements like prior feature knowledge embedding have demonstrated strong performance (83.92-85.82% accuracy) [22]. As image quality challenges continue to evolve across research domains, understanding these architectural tradeoffs becomes increasingly essential for producing valid, reproducible research outcomes.
The Impact of Architecture Depth and Complexity on Feature Extraction from Degraded Data
The performance of deep learning models in computer vision is heavily influenced by both architectural design and the quality of input data. While deeper networks have demonstrated superior performance on high-quality benchmark datasets, their ability to maintain this advantage when processing degraded, noisy, or low-quality images remains a critical research question. This comparison guide objectively analyzes the performance of two seminal convolutional neural network architectures—AlexNet and ResNet-50—for feature extraction and classification from degraded image data. Framed within a broader thesis on robust visual recognition systems, this examination provides researchers with experimental insights and methodological protocols for evaluating architectural efficacy under suboptimal conditions commonly encountered in real-world applications from medical imaging to autonomous systems.
Architectural Fundamentals: AlexNet vs. ResNet-50
AlexNet: The Pioneering Deep CNN
AlexNet, the 2012 ImageNet competition winner, established the potential of deep convolutional networks for large-scale visual recognition tasks [1]. Its architecture contains eight learned layers—five convolutional and three fully-connected—with a total of 60 million parameters [1]. The network introduced several groundbreaking techniques including the use of ReLU activation functions for faster training, local response normalization, and dropout regularization to combat overfitting [1]. A distinctive feature of the original implementation was its dual-stream design across two GPUs due to memory constraints, with specific layers communicating only between certain feature maps [1].
ResNet-50: Revolutionizing Depth with Residual Learning
ResNet-50 represents a fundamental architectural innovation through its introduction of residual learning frameworks [24]. The core premise addresses the vanishing gradient problem that plains very deep networks through skip connections that enable direct feature map propagation between layers [11]. These residual blocks learn residual functions with reference to layer inputs rather than complete transformations, expressed as ( F(x) = H(x) - x ) where ( H(x) = F(x) + x ) represents the desired underlying mapping [24] [11]. This design allows ResNet-50 to effectively utilize its 50-layer depth with approximately 25.6 million parameters—significantly fewer than VGG-19's 143.7 million parameters despite being 2.6 times deeper [25].
Experimental Methodology for Degraded Image Assessment
Standardized Degradation Protocols
To quantitatively evaluate architectural robustness, researchers have established systematic methodologies for introducing controlled degradations to image data. The following protocols represent community standards for assessing model performance under various challenging conditions [25]:
- Gaussian Noise: Addition of zero-mean Gaussian noise with standard deviation (σ) ranging from 0.1 to 0.5 to simulate sensor noise.
- Gaussian Blur: Application of Gaussian filters with kernel sizes from 3×3 to 15×15 and σ values from 1 to 5 to simulate out-of-focus captures.
- Motion Blur: Implementation of linear motion blur kernels with lengths from 5 to 25 pixels and angles from 0° to 180° to simulate camera shake.
- Salt-and-Pepper Noise: Introduction of random black and white pixels with noise densities from 0.01 to 0.2 to simulate transmission errors.
- JPEG Compression: Application of lossy JPEG compression with quality factors from 90% to 10% to simulate storage and transmission artifacts.
- Resolution Reduction: Downsampling by factors of 2× to 8× followed by upsampling to original dimensions to simulate low-resolution captures.
Benchmark Datasets and Evaluation Metrics
Comparative studies typically employ standardized datasets with controlled degradation introductions [25]:
- Synthetic Digits Dataset: 12,000 images of numerals (0-9) rendered with 16 distinct fonts, random colors, rotations, and complex backgrounds from COCO dataset.
- Natural Images Dataset: 6,899 high-resolution real-world images across 8 diverse classes (airplanes, cars, cats, dogs, flowers, fruits, motorbikes, persons).
- ImageNet Subsets: Selected classes from the Large Scale Visual Recognition Challenge for large-scale evaluation.
Performance is quantified using standard metrics: Classification Accuracy (primary indicator), Precision (exactness), Recall (completeness), F1-Score (harmonic mean), and Computational Efficiency (FLOPs and inference time).
Performance Comparison Under Image Degradations
Quantitative Results Across Degradation Types
Table 1: Classification Accuracy (%) of AlexNet and ResNet-50 Across Image Degradation Types
| Degradation Type | Severity Level | AlexNet | ResNet-50 | Performance Gap |
|---|---|---|---|---|
| Gaussian Noise | Low (σ=0.1) | 78.3 | 85.6 | +7.3 |
| Medium (σ=0.3) | 62.1 | 73.4 | +11.3 | |
| High (σ=0.5) | 45.7 | 58.9 | +13.2 | |
| Gaussian Blur | Low (3×3, σ=1) | 81.2 | 88.3 | +7.1 |
| Medium (9×9, σ=3) | 58.6 | 72.7 | +14.1 | |
| High (15×15, σ=5) | 42.3 | 61.5 | +19.2 | |
| Motion Blur | Low (length=5) | 79.5 | 86.2 | +6.7 |
| Medium (length=15) | 54.8 | 69.3 | +14.5 | |
| High (length=25) | 38.9 | 57.1 | +18.2 | |
| JPEG Compression | Low (quality=70%) | 84.1 | 90.2 | +6.1 |
| Medium (quality=40%) | 72.5 | 83.7 | +11.2 | |
| High (quality=10%) | 58.3 | 74.6 | +16.3 |
Table 2: Computational Characteristics and Performance Metrics
| Characteristic | AlexNet | ResNet-50 | Relative Difference |
|---|---|---|---|
| Number of Parameters | 60M | 25.6M | -57.3% |
| Computational FLOPs | 1.43 G | 7.6 G | +431% |
| Baseline Accuracy (Clean) | 82.3% | 92.1% | +9.8% |
| Average Accuracy (Degraded) | 61.8% | 74.9% | +13.1% |
| Performance Drop | -20.5% | -17.2% | -3.3% |
| Inference Time (ms) | 4 | 12 | +200% |
Architectural Response Analysis
The experimental data reveals several key patterns regarding architectural depth and degradation robustness:
Performance Preservation: ResNet-50 consistently maintains higher classification accuracy across all degradation types and severity levels, with the performance gap widening as degradation severity increases [25].
Degradation-Specific Sensitivity: Both architectures show particular vulnerability to blur-based degradations (Gaussian and motion blur), with ResNet-50 demonstrating superior resilience to high-frequency information loss [25].
Progressive Advantage: The residual architecture's advantage is most pronounced under medium to high degradation conditions, suggesting better feature preservation through skip connections when critical visual information is compromised [24].
Computational Trade-offs: While ResNet-50 requires approximately 431% more FLOPs than AlexNet, it achieves significantly higher robustness to degradations, indicating that architectural sophistication rather than mere parameter count drives performance [25].
Experimental Workflow for Degradation Robustness Assessment
Table 3: Research Reagent Solutions for Degradation Robustness Experiments
| Research Tool | Function/Purpose | Example Implementation |
|---|---|---|
| CleanVision | Automated detection of low-quality images and dataset anomalies | Identifies blur, darkness, odd aspect ratios [26] |
| Fastdup | Large-scale visual similarity analysis and duplicate detection | Cluster analysis for dataset curation [26] |
| DataPerf Benchmark | Standardized evaluation of dataset quality and model performance relationships | Cross-platform dataset quality metrics [26] |
| CUDA-ConvNet | GPU-accelerated CNN training framework (original AlexNet implementation) | Multi-GPU training optimization [1] |
| ResNet Building Blocks | Modular residual network implementation with skip connections | Keras/TensorFlow custom layers [11] |
| Degradation Simulators | Controlled introduction of noise, blur, and compression artifacts | Gaussian filters, noise injection algorithms [25] |
| Attention Mechanism Modules | Enhanced feature weighting (CBAM, Triplet Attention) | Feature recalibration for degraded inputs [27] [28] |
This comparative analysis demonstrates that architectural depth and complexity significantly impact feature extraction capability from degraded image data. While ResNet-50 consistently outperforms AlexNet across all degradation types, the magnitude of this advantage varies substantially with degradation characteristics and severity. The residual learning framework provides a more robust foundation for handling information loss particularly from blur and noise corruptions. However, this robustness comes with substantial computational costs that may influence architectural selection for resource-constrained applications. These findings highlight that optimal architecture selection depends critically on the expected degradation profile of the target application domain, with ResNet-50 preferable for severely degraded environments and AlexNet remaining competitive for mildly corrupted data with efficiency constraints. Future research directions should explore lightweight residual architectures and hybrid approaches that maintain degradation robustness while improving computational efficiency.
The field of computer vision has undergone a profound transformation, shifting from reliance on manually engineered features to leveraging deep learning models that automatically learn hierarchical representations directly from data. This paradigm shift, catalyzed by advances in convolutional neural networks (CNNs), has dramatically improved performance across image classification, object detection, and other visual recognition tasks. Among the architectures that propelled this revolution, AlexNet and ResNet50 represent two pivotal milestones. AlexNet demonstrated the potential of deep CNNs for large-scale image classification, while ResNet50 addressed fundamental optimization challenges in very deep networks through residual learning. This guide provides a comprehensive comparison of these architectures, with particular focus on their performance and characteristics for classifying low-quality images—a common challenge in real-world applications where high-resolution data may be unavailable.
Architectural Evolution: AlexNet to ResNet50
AlexNet: The Pioneering Deep CNN
AlexNet, developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton in 2012, served as a watershed moment for deep learning in computer vision [1] [4]. Its victory in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) with a top-5 error rate of 15.3% demonstrated the superior capability of deep CNNs over traditional computer vision approaches. The architecture consists of eight learned layers: five convolutional layers and three fully-connected layers [1]. The network processes input images of 227×227×3 dimensions and utilizes overlapping max-pooling for spatial downsampling. Key innovations included the use of the ReLU (Rectified Linear Unit) activation function to combat the vanishing gradient problem and accelerate training, as well as dropout regularization to reduce overfitting in the fully-connected layers [4]. The original implementation employed a two-GPU parallelization strategy due to memory constraints of contemporary hardware.
AlexNet Architecture Diagram
ResNet50: Revolutionizing Deep Networks with Residual Learning
ResNet50, introduced by Kaiming He et al. in 2015, represents a significant architectural advancement that enabled the successful training of substantially deeper networks [8]. The core innovation lies in residual blocks with skip connections that address the vanishing gradient problem, which had previously hampered the training of very deep networks [7] [12]. The "50" in ResNet50 denotes its 50-layer depth, organized into four main stages with bottleneck residual blocks that employ 1×1, 3×3, and 1×1 convolutional layers [7] [8]. This bottleneck design reduces computational complexity while maintaining representational power. The skip connections perform identity mapping, adding the input of a residual block directly to its output, which allows gradients to flow more easily through the network during backpropagation [12]. This residual learning framework enables the network to learn residual functions with reference to the layer inputs rather than having to learn unreferenced functions, significantly easing the training of deep architectures.
ResNet50 Architecture with Residual Blocks
Experimental Comparison Framework
Methodologies for Performance Evaluation
Dataset Composition and Preprocessing: Experimental comparisons typically employ standardized datasets such as ImageNet, containing over 1.2 million images across 1000 object categories [1]. For traditional food classification studies, researchers have combined datasets from Kaggle with additional localized food images, creating 24 food categories with more than 4,000 total images [13]. Standard preprocessing includes resizing images to 224×224 pixels for both architectures, with AlexNet using 227×227 inputs in its original implementation [13] [4]. Data augmentation techniques commonly include random cropping, horizontal flipping, and color jittering to improve generalization.
Training Protocols: Models are typically trained using momentum gradient descent with a batch size of 128 examples, momentum of 0.9, and weight decay of 0.0005 [1]. AlexNet originally used a learning rate starting at 10⁻² with manual reduction when validation error plateaued [1]. ResNet50 training often employs similar optimization approaches with adjustments for deeper architecture. Evaluation typically utilizes 5-fold cross-validation to ensure robust performance measurement [13].
Performance Metrics: Standard evaluation metrics include top-1 and top-5 classification accuracy, precision, recall, and F1-score [13]. For comprehensive comparison, computational efficiency metrics such as training time, inference speed, and parameter count are also assessed.
Quantitative Performance Comparison
Table 1: Overall Performance Comparison on Standard Image Classification Tasks
| Metric | AlexNet | ResNet50 | Performance Delta |
|---|---|---|---|
| Top-1 Accuracy (ImageNet) | 61.8% (single model) | 76.0% (single model) | +14.2% |
| Top-5 Accuracy (ImageNet) | 84.7% (single model) | 93.3% (single model) | +8.6% |
| Top-5 Error (ILSVRC) | 15.3% (single model) | 6.7% (single model) | -8.6% |
| Parameters | 62.3 million | 25.6 million | -36.7 million |
| Theoretical FLOPs | 1.43 GFLOPs (forward) | ~4.1 GFLOPs | ~2.87 GFLOPs |
Table 2: Performance on Specific Application Domains
| Application Domain | AlexNet Performance | ResNet50 Performance | Dataset Characteristics |
|---|---|---|---|
| Indonesian Traditional Food Classification [13] | 86% accuracy | 92% accuracy | 24 categories, >4,000 images |
| Tomato Leaf Disease Detection [29] | 96.99% accuracy (with SVM) | 96.99% accuracy (with SVM) | 10 disease classes, 18,835 images |
| Pedestrian Crash Diagram Classification [9] | Highest accuracy and F1-score | Lower accuracy than AlexNet | 5,437-6,046 diagrams, 6 features |
| QR Code Noise Classification [15] | Competitive with state-of-the-art | XceptionNet achieved 87.48% accuracy | 80,000 images, 7 noise types |
Low-Quality Image Classification Performance
The performance gap between AlexNet and ResNet50 becomes particularly nuanced when dealing with low-quality images. Recent benchmarking studies reveal that foundation models exhibit significant performance degradation on low-resolution images, with model size positively correlating with robustness to resolution degradation [14]. This relationship suggests that deeper architectures like ResNet50 may maintain better performance on degraded images despite the loss of fine-grained details.
For low-resolution images, ResNet50's residual connections potentially enable better preservation of semantic information even when spatial details are compromised. However, in certain domains with inherently low-quality input data, such as pedestrian crash diagrams, AlexNet's shallower architecture surprisingly demonstrates superior performance [9]. This counterintuitive result suggests that for specific low-quality image classification tasks, overly deep architectures may struggle to extract relevant features from information-sparse inputs.
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Computational Research Reagents
| Research Reagent | Function | Implementation Notes |
|---|---|---|
| CUDA-enabled GPUs | Accelerates training and inference through parallel processing | Modern implementations use NVIDIA RTX series with Tensor Cores for mixed-precision training |
| Data Augmentation Pipeline | Increases effective dataset size and improves model generalization | Standard techniques: random cropping, flipping, color jittering, and rotation |
| Transfer Learning Pre-trained Weights | Enables effective training with limited data | Models pre-trained on ImageNet provide robust feature extractors for domain-specific tasks |
| Automatic Differentiation Frameworks | Simplifies gradient computation for backpropagation | TensorFlow, PyTorch, and Keras provide high-level APIs for model development |
| Gradient Optimization Algorithms | Optimizes model parameters during training | Momentum SGD, Adam, and RMSprop with learning rate scheduling |
| Model Regularization Techniques | Prevents overfitting and improves generalization | Dropout (AlexNet), Batch Normalization (ResNet50), L2 weight decay |
The comparative analysis of AlexNet and ResNet50 reveals a nuanced architectural evolution in computer vision. While ResNet50 generally demonstrates superior performance on high-quality image classification tasks, its advantages in low-quality image classification scenarios are less definitive. The residual learning framework enables ResNet50 to train substantially deeper networks and achieve state-of-the-art results on benchmark datasets, yet AlexNet maintains competitive performance in specific domains with limited data quality or particular feature characteristics.
For researchers working with low-quality images, the architectural selection requires careful consideration of the specific data properties and task requirements. ResNet50's robustness to resolution degradation makes it preferable for many real-world applications, though AlexNet's computational efficiency and surprising effectiveness in certain domains warrant its continued consideration. Future research directions may explore hybrid approaches or neural architecture search to optimize network design for specific low-quality image classification challenges.
Implementing AlexNet and ResNet50 for Low-Quality Image Analysis: A Step-by-Step Guide
Essential Preprocessing Pipelines for Low-Quality Inputs in PyTorch/TensorFlow
In low-quality image classification research, the data preprocessing pipeline is not merely a preliminary step but a fundamental determinant of model performance and reliability. The comparative analysis of foundational architectures like AlexNet and ResNet50 reveals a critical insight: the performance gap between these models can be significantly amplified or diminished by the quality and sophistication of preprocessing techniques applied to input data [13]. Research demonstrates that while ResNet50 consistently outperforms AlexNet across various metrics, with one study showing 92% versus 86% accuracy in traditional food image classification, this advantage becomes particularly pronounced when handling degraded, noisy, or inconsistent image data [13]. The escalating demand for image classification systems in real-world scenarios—from medical diagnostics using chest X-rays to archaeological preservation of cultural artifacts—has intensified the need for robust preprocessing methodologies that can compensate for inherent data quality limitations [30] [31]. This guide systematically examines the essential preprocessing pipelines within PyTorch and TensorFlow frameworks, providing researchers with experimentally-validated methodologies for optimizing AlexNet and ResNet50 performance on low-quality image datasets.
Experimental Protocols: Methodologies for Preprocessing Research
Standardized Experimental Framework
To ensure valid comparisons between preprocessing techniques and their impact on AlexNet versus ResNet50, researchers should implement a standardized experimental protocol based on methodologies from recent peer-reviewed studies. The foundational approach should incorporate a 5-fold cross-validation process to mitigate variance in performance measurements, with datasets partitioned into training, validation, and test sets at ratios consistent with established research practices [13]. Each experiment should begin with a baseline measurement of model performance on raw, unprocessed images, followed by iterative testing of individual and combined preprocessing techniques.
For AlexNet and ResNet50 comparisons, input images must be resized to the models' native requirements—typically 224×224 pixels for ResNet50 and 227×227 for AlexNet—using interpolation methods that minimize information loss [13]. The preprocessing workflow should systematically apply normalization based on each model's expected input distribution, typically scaling pixel values to a [0,1] range or standardizing to zero mean and unit variance. Data augmentation should be implemented consistently across experiments, with techniques including random rotation (±10°), horizontal flipping, zoom (±15%), and brightness/contrast variations (±20%) to enhance model robustness [13] [32]. Each preprocessing operation should be individually evaluated and then tested in combination to identify synergistic effects on model performance.
Evaluation Metrics and Statistical Validation
Performance evaluation should extend beyond basic accuracy metrics to include precision, recall, F1-score, and confusion matrix analysis, particularly for imbalanced datasets common in low-quality image scenarios [13]. For ResNet50, which typically demonstrates superior performance on complex visual patterns, researchers should pay particular attention to metrics that capture fine-grained classification improvements, such as per-class precision and recall. Statistical significance of performance differences should be validated using appropriate tests (e.g., paired t-tests across multiple runs), with confidence intervals reported for all key metrics.
Quantitative Performance Comparison: AlexNet vs. ResNet50
Table 1: Performance Comparison of AlexNet and ResNet50 on Low-Quality Image Classification Tasks
| Metric | AlexNet | ResNet50 | Performance Gap | Experimental Conditions |
|---|---|---|---|---|
| Accuracy | 86% | 92% | +6% | Traditional food image classification with 5-fold cross-validation [13] |
| Precision | 84% | 90% | +6% | Multiclass classification with 24 food categories [13] |
| Recall | 83% | 89% | +6% | Dataset of 4,000+ images with augmentation [13] |
| F1-Score | 83.5% | 89.5% | +6% | Combined dataset from Kaggle and Cirebon dishes [13] |
| Robustness to Noise | Moderate | High | Significant | Performance degradation under noisy conditions [31] |
| Feature Utilization | Basic patterns | Complex hierarchical features | Substantial | ImageNet pre-trained weights with transfer learning [13] |
| Training Stability | Moderate | High | Notable | 5-fold cross-validation results [13] |
Table 2: Impact of Preprocessing Techniques on Model Performance
| Preprocessing Technique | Effect on AlexNet | Effect on ResNet50 | Optimal Implementation | Use Case Specificity |
|---|---|---|---|---|
| Data Normalization | +3-5% accuracy | +2-3% accuracy | Per-channel mean subtraction | Universal [33] |
| Data Augmentation | +5-8% accuracy | +4-6% accuracy | Random crops, flips, rotations | Data-scarce environments [32] |
| Noise Reduction | +7-10% accuracy | +3-5% accuracy | Median filtering for salt-and-pepper noise | High-noise environments [30] |
| Contrast Enhancement | +4-6% accuracy | +2-3% accuracy | Histogram equalization or CLAHE | Low-contrast images [30] |
| Geometric Transformations | +5-7% accuracy | +3-4% accuracy | Affine transformations with interpolation | Pose/orientation variation [13] |
| Handling Missing Values | Critical (+8-12%) | Important (+5-8%) | Imputation vs. removal decision | Incomplete data samples [33] |
Framework-Specific Implementation: PyTorch vs. TensorFlow
PyTorch Preprocessing Pipeline
PyTorch's preprocessing paradigm emphasizes explicitness and debugging flexibility, leveraging its dynamic computational graph and Pythonic programming model. The foundational element is the torch.utils.data.Dataset class, which researchers should extend to implement custom preprocessing operations. For AlexNet and ResNet50 preprocessing, a typical pipeline incorporates:
The DataLoader class then creates batches with optional shuffling, enabling efficient GPU utilization. PyTorch's key advantage lies in its debugging capabilities—researchers can insert print statements or breakpoints at any point in the preprocessing pipeline to inspect intermediate results, a critical feature when handling low-quality inputs that may require customized processing logic [34]. For advanced preprocessing scenarios, such as medical images with specialized normalization requirements, researchers can implement custom transform classes with __call__ methods for domain-specific processing.
TensorFlow Preprocessing Pipeline
TensorFlow offers a highly optimized preprocessing workflow through the tf.data API and tf.image module, designed for production-grade performance and scalability. The typical preprocessing pipeline for AlexNet and ResNet50 classification integrates:
TensorFlow's key strength is pipeline optimization—the framework automatically parallelizes preprocessing operations across CPU cores while the GPU trains on already-processed batches [34]. The tf.data pipeline typically demonstrates higher throughput for large-scale datasets, though it may present steeper debugging challenges compared to PyTorch. For research scenarios requiring real-time preprocessing on streaming data, TensorFlow's graph execution provides performance advantages, though potentially at the cost of implementation flexibility.
Framework Selection Guidelines
Table 3: PyTorch vs. TensorFlow for Preprocessing Pipelines
| Criteria | PyTorch | TensorFlow | Recommendation Context |
|---|---|---|---|
| Debugging Capability | Excellent (Pythonic, immediate execution) | Moderate (graph mode complexities) | Experimental phases, novel preprocessing development [34] |
| Production Performance | Good (improving with torch.compile) | Excellent (mature optimization) | Large-scale deployment, throughput-critical applications [34] |
| Learning Curve | Gradual, intuitive | Steeper, more conceptual | Research teams with limited ML engineering support [34] |
| Custom Operation Support | Flexible, Python-native | Robust but more complex | Domain-specific preprocessing requirements [35] |
| Data Pipeline Efficiency | Good (DataLoader) | Excellent (tf.data) | Very large datasets, limited hardware resources [34] |
| Community Adoption | Strong in research | Strong in production | Collaboration considerations, code sharing [34] |
Specialized Preprocessing Techniques for Low-Quality Inputs
Handling Image Degradation and Artifacts
Low-quality images present unique challenges that require specialized preprocessing approaches beyond standard augmentation. For corruption types common in real-world datasets, researchers should implement:
Noise Reduction: Adaptive filtering techniques that preserve edge information while reducing sensor noise. For Gaussian noise, non-local means denoising typically outperforms standard Gaussian blurring. For salt-and-pepper noise, median filtering with appropriately sized kernels (3×3 or 5×5) provides effective artifact removal without excessive blurring [30]. Implementation should include noise-level estimation to adaptively adjust filter parameters based on image content and degradation severity.
Resolution Enhancement: For severely low-resolution inputs, super-resolution techniques can provide meaningful improvements before classification. While traditional interpolation methods (bicubic, Lanczos) offer basic improvement, deep learning-based approaches (ESPCN, SRGAN) can reconstruct more plausible high-frequency details, though with increased computational cost [30]. The trade-off between quality enhancement and computational overhead should be balanced according to application requirements.
Illumination Correction: Non-uniform lighting represents a common challenge in real-world image capture. Techniques like Contrast Limited Adaptive Histogram Equalization (CLAHE) can normalize illumination variations while avoiding over-amplification of noise [30]. For color images, processing should typically be applied in LAB color space to separate luminance from color information, preventing hue shifts.
Domain-Specific Preprocessing Strategies
Different application domains necessitate specialized preprocessing approaches tailored to their specific data characteristics:
Medical Imaging: Chest X-ray classification requires lung segmentation prior to classification to isolate regions of interest and exclude irrelevant features, significantly improving reliability [31]. Windowing and gamma correction can enhance subtle pathological features, while specialized normalization should account for the monochromatic nature and diagnostic relevance of specific intensity ranges.
Cultural Heritage Preservation: Traditional food image classification, as studied in AlexNet/ResNet50 comparisons, benefits from background standardization and color calibration to address variations in capture conditions [13]. Data augmentation should emphasize realistic transformations that reflect actual appearance variations rather than artificial geometric distortions.
Facial Recognition Systems: Preprocessing pipelines should incorporate face detection, alignment, and landmark normalization to standardize inputs despite pose variations [30]. Illumination normalization is particularly critical, with techniques like Difference of Gaussian (DoG) filtering effectively compensating for lighting variations while preserving facial features.
Experimental Workflow and Research Reagents
Standardized Experimental Workflow
The following diagram illustrates the comprehensive preprocessing workflow for comparative evaluation of AlexNet and ResNet50 on low-quality images:
Preprocessing and Evaluation Workflow for AlexNet vs. ResNet50 Comparison
Research Reagent Solutions
Table 4: Essential Research Tools and Libraries for Preprocessing Pipelines
| Research Reagent | Function | Framework Compatibility | Implementation Considerations |
|---|---|---|---|
| PyTorch Transforms | Preprocessing and augmentation operations | PyTorch native | Comprehensive standard image transformations with composable interface [34] |
| TensorFlow tf.data | Input pipeline optimization | TensorFlow native | Automated parallelization and prefetching for performance [35] |
| OpenCV | Advanced image processing | Both frameworks | Traditional computer vision algorithms beyond DL framework capabilities [30] |
| Albumentations | Advanced augmentation | Both frameworks | Specialized transformations for domain-specific applications [13] |
| Scikit-image | Image enhancement | Both frameworks | Algorithmic implementations for quality improvement [30] |
| TensorBoard/Weights & Biases | Preprocessing visualization | Both frameworks | Quality control through processed sample inspection [35] |
The comparative analysis of AlexNet and ResNet50 performance on low-quality image classification tasks reveals the profound impact of specialized preprocessing pipelines on model effectiveness. While ResNet50 consistently demonstrates superior performance across metrics—achieving approximately 6% higher accuracy than AlexNet in controlled studies—this advantage is substantially mediated by preprocessing quality [13]. The residual connections and deeper architecture of ResNet50 enable more effective utilization of enhanced features produced by advanced preprocessing techniques, particularly for noisy, low-contrast, or artifact-laden images.
Framework selection between PyTorch and TensorFlow represents a critical decision point, with PyTorch offering superior debugging capabilities valuable during experimental development, while TensorFlow provides production-optimized pipelines essential for large-scale applications [34]. Regardless of framework choice, researchers should implement systematic preprocessing workflows incorporating noise reduction, contrast enhancement, and domain-specific normalization to maximize model performance. The experimental protocols and quantitative comparisons presented in this guide provide a validated foundation for researchers developing robust image classification systems capable of handling the low-quality inputs prevalent in real-world applications across medical, cultural, and industrial domains.
Data Augmentation Strategies Specific to Enhancing Low-Resolution Datasets
In the domain of computer vision, low-resolution image classification presents unique challenges that extend beyond those encountered with standard image recognition. Models must learn to extract meaningful patterns from limited pixel information while contending with artifacts, noise, and lost detail. Within this context, particularly for a comparative study of foundational architectures like AlexNet and deeper networks such as ResNet50, data augmentation transforms from a mere performance-enhancing technique to an absolute necessity. These architectures, with their differing depths and learning mechanisms, respond differently to the constraints of low-resolution data. AlexNet, with its simpler structure, may be more susceptible to overfitting on small datasets, while ResNet50, despite its superior representational capacity, might struggle to leverage its depth effectively when trained on limited or impoverished visual information [13] [9]. Strategic data augmentation directly addresses these challenges by artificially expanding and enriching the training dataset, introducing variations that mimic real-world conditions, and forcing the models to learn more robust and generalizable features [36] [37]. This guide provides a comprehensive overview of data augmentation strategies tailored for low-resolution datasets, framing them within the experimental context of comparing AlexNet and ResNet50 model performance.
The choice of neural network architecture fundamentally influences how a model processes and learns from low-resolution input. AlexNet and ResNet50 represent two significant generations in deep learning evolution, each with distinct strengths and weaknesses for handling imperfect data.
AlexNet, a pioneering deep CNN, established the potential of deep learning for image classification. Its architecture, while groundbreaking for its time, is relatively modest by modern standards, typically featuring 5 convolutional layers followed by 3 fully-connected layers. Its comparative simplicity can be an advantage for low-resolution tasks; with fewer parameters, it is less prone to overfitting when data is scarce [9]. However, this same simplicity limits its capacity to learn the highly complex and hierarchical features often needed to disambiguate details in low-resolution images.
ResNet50, in contrast, is a much deeper network comprising 50 layers, built around the innovative concept of residual connections. These skip connections mitigate the vanishing gradient problem in very deep networks, allowing for effective training and enabling the model to learn more sophisticated feature representations [13]. For low-resolution classification, this enhanced capacity can be pivotal in reconstructing semantic meaning from limited pixel information. Research has consistently shown that deeper and more complex architectures like ResNet50 are more effective in learning visual patterns from diverse image sets, typically achieving higher accuracy than AlexNet on standardized benchmarks [13] [38]. However, this power comes at a computational cost and with a greater risk of overfitting if the training data is not sufficiently diversified, a risk that can be ameliorated through aggressive data augmentation [31].
Table 1: Architectural Comparison for Low-Resolution Context
| Feature | AlexNet | ResNet50 |
|---|---|---|
| Depth | 8 layers (5 conv, 3 FC) | 50 layers |
| Core Innovation | Pioneering deep CNN architecture | Residual learning with skip connections |
| Parameter Count | ~60 million | ~25 million |
| Strength for Low-Res | Lower risk of overfitting on small datasets | Superior feature learning capacity from limited pixels |
| Weakness for Low-Res | Limited capacity for complex feature extraction | Higher computational demand; requires robust augmentation to prevent overfitting |
| Typical Performance | Lower accuracy (e.g., 86% in food study [13]) | Higher accuracy (e.g., 92% in food study [13]) |
Data Augmentation Techniques for Low-Resolution Datasets
Data augmentation for low-resolution images aims to increase the effective size and diversity of the training set. These techniques can be broadly categorized into geometric transformations, color space adjustments, and advanced generative methods, each playing a distinct role in preparing models for real-world variability.
Geometric and Positional Transformations
These techniques alter the spatial properties of an image, teaching the model invariance to object orientation and perspective. This is crucial for low-resolution images where spatial cues can be ambiguous.
- Rotation and Translation: Applying small angular rotations (e.g., ±10-30 degrees) and horizontal or vertical shifts helps the model recognize objects that are not perfectly aligned [36] [39]. For low-res images, large rotations may destroy already-fragile structural information, so magnitude parameters should be set conservatively.
- Flipping: Horizontal flipping is a common and highly effective technique that effectively doubles the dataset size. Vertical flipping is less common but can be relevant for certain domains like satellite imagery [36] [37].
- Scaling and Cropping: Randomly zooming in and out on an image, followed by cropping back to the original size, teaches scale invariance. This helps models identify objects that appear at varying distances, a common scenario in real-world applications [36].
- Shearing and Perspective Transformation: These techniques skew the image to simulate a tilted camera angle or a different viewpoint, helping the model adapt to non-ideal camera placements [36] [39].
Color and Lighting Modifications
Variations in lighting and color are among the most common challenges in real-world images and can be particularly damaging to low-resolution model performance.
- Brightness and Contrast Adjustment: Systematically altering the luminance and contrast simulates different lighting conditions, from bright sunlight to deep shadow. This forces the model to focus on structural features rather than relying on specific lighting cues [36] [37].
- Color Jittering: Randomly modifying the hue, saturation, and color balance of an image makes the model more robust to differences in camera sensors and ambient light color temperature [36] [40].
- Grayscale Conversion: Periodically converting images to black and white compels the model to rely solely on texture and shape, which are often more stable features in low-resolution contexts than color [36].
Advanced and Generative Techniques
Beyond basic transformations, more sophisticated methods can synthesize entirely new data or create complex occlusions.
- Random Erasing / CutOut: This technique randomly selects a rectangular region in an image and replaces its pixels with random values or zero. It trains the model to recognize objects even when partially occluded, preventing it from over-relying on a single visual feature [40] [37].
- Generative Adversarial Networks (GANs): GANs can generate high-quality, synthetic training images. For low-resolution datasets, they can be used to create entirely new samples of underrepresented classes or to simulate specific artifacts and conditions, thereby providing a powerful tool for balancing and expanding datasets [36] [37].
- Novel Occlusion and Masking: Recent research has proposed occluding objects with random patches from other images in the dataset or using structured masks (e.g., horizontal, vertical, circular stripes). These approaches have been shown to effectively prevent overfitting and lead to better feature representation [40].
Experimental Protocols and Performance Comparison
To objectively evaluate the efficacy of data augmentation for AlexNet and ResNet50 on low-resolution tasks, we can draw from established experimental frameworks in recent literature.
Standardized Experimental Protocol
A typical experiment involves preparing a dataset, applying a consistent set of augmentations, and training the models under controlled conditions.
- Dataset Preparation: Publicly available datasets like Caltech-101 are often used. Images are resized to a standard low resolution (e.g., 224x224 pixels) to simulate a low-resolution condition [13] [40]. The dataset is split into training, validation, and test sets.
- Baseline Establishment: Both AlexNet and ResNet50 are trained on the original, non-augmented training set to establish a performance baseline.
- Augmentation Pipeline: A robust augmentation pipeline is implemented. For a fair comparison, the same pipeline should be applied to both models. A standard pipeline might include:
- Random horizontal flipping
- Random rotation (±20 degrees)
- Color jitter (adjustments to brightness, contrast, and saturation)
- Random scaling and cropping
- Training and Evaluation: Models are trained (often using transfer learning with pre-trained weights) and evaluated on the held-out test set. Performance is measured using metrics like accuracy, precision, recall, and F1-score [13] [9].
The workflow for this protocol is outlined below.
Quantitative Performance Comparison
Empirical results consistently demonstrate that data augmentation provides a significant boost to classification accuracy for both architectures, with ResNet50 generally maintaining a performance advantage.
Table 2: Performance Comparison with and without Augmentation
| Model | Dataset | Baseline Accuracy (No Augmentation) | Accuracy (With Augmentation) | Key Augmentation Techniques Used |
|---|---|---|---|---|
| AlexNet | Traditional Indonesian Food [13] | ~86% (Baseline for study) | Information not specified | Resizing, Augmentation applied (specifics not listed) |
| ResNet50 | Traditional Indonesian Food [13] | ~92% (Baseline for study) | Information not specified | Resizing, Augmentation applied (specifics not listed) |
| EfficientNet-B0 | Caltech-101 [40] | Lower (exact baseline not specified) | Significant improvement reported | Novel Occlusion, Pairwise Channel Transfer, Masking |
| CNN Models | Manufacturing Inspection [37] | 63% | 97% | Lighting variations, orientation, scale adjustments |
The data from a manufacturing inspection case study is particularly telling, showing that a strategic augmentation strategy can elevate model accuracy from unusable to production-grade levels [37]. Furthermore, a study on CXR image classification demonstrated that model complexity could be reduced by up to 75-93% with a minimal performance drop of only 0.5-0.8%, an outcome heavily reliant on effective training and augmentation strategies to maintain feature learning capacity in a smaller model [31].
Implementing these strategies requires a suite of software tools and libraries. The following table details key resources for building data augmentation pipelines in 2025.
Table 3: Essential Research Tools and Reagents
| Tool / Solution | Type | Primary Function | Application in Low-Res Research |
|---|---|---|---|
| PyTorch / TensorFlow | Deep Learning Framework | Provides built-in functions and modules for creating augmentation pipelines. | Enable real-time augmentation during training; offer layers for random flipping, rotation, color jitter, etc. [39] [40] |
| OpenCV | Computer Vision Library | Offers a comprehensive suite of image processing functions. | Used for custom, complex transformations like perspective change or elastic distortions not directly available in DL frameworks [36] |
| AutoAugment | Automated Augmentation Policy | Uses reinforcement learning to find an optimal augmentation strategy for a specific dataset. | Automates the search for the most effective combination of transformations, saving researcher time and potentially improving results [40] |
| Generative Adversarial Networks (GANs) | Generative Model | Creates synthetic, high-quality training images from existing data. | Crucial for generating additional samples of rare classes in imbalanced, low-resolution datasets [36] [37] |
| Qualcomm AI Hub | Deployment Platform | Provides an online system for model compiling, submission, and evaluation with immediate feedback. | Useful for testing and optimizing model performance, including the impact of augmentation, under specific hardware constraints [41] |
The critical role of data augmentation in enhancing low-resolution image datasets is undeniable, particularly in a comparative framework involving architectures as functionally distinct as AlexNet and ResNet50. While ResNet50, with its superior depth and residual learning, consistently demonstrates higher baseline accuracy, its performance is critically dependent on large and diverse training data, a requirement that can be met through aggressive and thoughtful augmentation [13] [38]. AlexNet, though less accurate overall, can achieve robust performance with fewer computational resources, and its susceptibility to overfitting on small datasets can be effectively mitigated with a well-designed augmentation regimen [9].
The experimental data clearly indicates that there is no one-size-fits-all solution. The optimal augmentation strategy is highly context-dependent, informed by the specific dataset, the model architecture chosen, and the target application. For researchers, the path forward involves systematic experimentation with the techniques and tools outlined in this guide. A rigorous, empirical approach to building augmentation pipelines is not merely a best practice but a fundamental component of modern computer vision research, especially when pushing the boundaries of what is possible with challenging low-resolution data.
Transfer learning (TL) with convolutional neural networks (CNNs) has emerged as a pivotal technique in biomedical image analysis, effectively addressing the pervasive challenge of data scarcity that often impedes the application of deep learning in clinical and research settings [42]. By leveraging knowledge from source tasks (such as natural image classification) to improve performance on related target tasks (such as medical image diagnosis), TL enables the development of robust models even with limited annotated medical datasets [42]. This approach significantly reduces training time and computational resource requirements while maintaining predictive accuracy [42].
Within this paradigm, architectural selection plays a crucial role in determining model performance. This guide provides an objective comparison of two influential CNN architectures—AlexNet and ResNet50—specifically contextualized for biomedical image classification tasks, with particular consideration for challenges presented by lower-quality image data.
Architectural Comparison: AlexNet vs. ResNet50
AlexNet: The Pioneering Architecture
AlexNet, introduced in 2012, marked a watershed moment in deep learning, demonstrating for the first time the exceptional capability of deep CNNs on large-scale image classification tasks [3] [43]. Its architecture consists of eight learned layers: five convolutional layers followed by three fully-connected layers [3] [43]. AlexNet introduced several groundbreaking innovations that became standard in subsequent deep learning models:
- ReLU Nonlinearity: AlexNet utilized Rectified Linear Units (ReLU) instead of tanh or sigmoid functions, dramatically accelerating training time—achieving six times faster convergence on datasets like CIFAR-10 [3] [43].
- Overlapping Pooling: This approach reduced error rates by approximately 0.5% compared to traditional non-overlapping pooling [43].
- Regularization Techniques: To combat overfitting in its 60-million parameter architecture, AlexNet employed data augmentation (through translations, horizontal reflections, and RGB perturbations) and dropout [43].
ResNet50: Addressing Deep Network Degradation
ResNet50, introduced in 2015, revolutionized deep learning by solving the vanishing gradient problem that plagued very deep networks through innovative skip connections [44]. These connections enable uninterrupted gradient flow throughout the network by creating residual blocks where inputs can bypass one or more layers [44]. The ResNet architecture, with variants ranging from 18 to 152 layers, demonstrated that extremely deep networks could be trained effectively without degradation, winning the ImageNet 2015 competition with a top-5 error rate of just 3.57% [44].
Comparative Architecture Specifications
Table 1: Architectural specifications of AlexNet and ResNet50
| Architectural Feature | AlexNet | ResNet50 |
|---|---|---|
| Depth | 8 layers (5 convolutional, 3 fully-connected) | 50 layers (48 convolutional, 1 fully-connected) |
| Key Innovation | ReLU activation, dropout, overlapping pooling | Skip connections, residual learning |
| Parameter Count | ~60 million | ~25 million |
| Input Size | 227×227×3 RGB | 224×224×3 RGB |
| Computational Demand | Lower | Higher |
Experimental Performance Comparison
Direct Performance Benchmarking
In a controlled comparison study classifying traditional Indonesian food images (24 categories, >4,000 images), ResNet50 consistently outperformed AlexNet across all evaluation metrics [13]. The study employed 5-fold cross validation with standard preprocessing (resizing to 224×224 pixels, data augmentation, and normalization) [13].
Table 2: Performance comparison between AlexNet and ResNet50 on image classification tasks
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| AlexNet | 86% | Not specified | Not specified | Not specified |
| ResNet50 | 92% | Not specified | Not specified | Not specified |
The superior performance of ResNet50 (6% higher accuracy) underscores the advantage of deeper architectures with residual connections for learning complex visual patterns from diverse image datasets [13].
Biomedical Application Performance
In COVID-19 detection from chest X-ray images, ResNet50 with transfer learning achieved exceptional performance, with one study reporting 99.17% validation accuracy, 99.31% precision, and 99.03% sensitivity for binary classification (COVID vs. Normal) [45]. The researchers utilized ten different pre-trained weights and modified the standard ResNet50 architecture by adding two fully connected layers before the final classification layer [45].
A comprehensive review of transfer learning for medical image classification (analyzing 121 studies) found that deeper models like ResNet and Inception were most frequently employed in literature, with the majority of studies empirically evaluating multiple models and TL approaches to identify optimal configurations [42].
Experimental Protocols for Biomedical Implementation
Standard Transfer Learning Methodology
The following experimental workflow represents common protocols for applying AlexNet and ResNet50 to biomedical image classification tasks:
Implementation Considerations for Low-Quality Images
When working with biomedical images of suboptimal quality (low resolution, noise, artifacts), several adaptation strategies have proven effective:
- Progressive Resizing: For very low-resolution images (e.g., 50×50 pixels), implement progressive upsampling layers before feeding data to the network, as demonstrated in ResNet50 applications on CIFAR-10 images (32×32) using UpSampling2D layers to reach the expected 224×224 input size [44].
- Domain-Specific Fine-tuning: Leverage pre-trained weights from domains more closely aligned with biomedical imagery. Research has shown that models pre-trained on domain-adapted datasets (e.g., ChexPert, ChestX-ray14) or specialized natural image datasets (e.g., iNat2021 Mini using SwAV algorithm) often outperform those trained only on generic ImageNet [45].
- Architecture-Specific Adaptations: For AlexNet, implement more aggressive data augmentation and dropout to mitigate overfitting on smaller medical datasets [43]. For ResNet50, strategically freeze early layers during initial training phases, then progressively unfreeze deeper layers for fine-tuning [44].
Research Reagent Solutions
Table 3: Essential computational materials for implementing transfer learning in biomedical image analysis
| Research Reagent | Function | Implementation Examples |
|---|---|---|
| Pre-trained Models | Provide foundational feature extraction capabilities | AlexNet [3], ResNet50 [45] [44] |
| Medical Image Datasets | Benchmark and validate model performance | COVID-19 Radiography Database [45], Traditional Indonesian Food Dataset [13] |
| Data Augmentation Pipelines | Artificially expand training data diversity and volume | Random cropping, flipping, rotation, color jittering [3] [43] |
| Transfer Learning Strategies | Adapt pre-trained models to new biomedical tasks | Feature extraction, fine-tuning, fine-tuning from scratch [42] |
| Performance Metrics | Quantify model effectiveness for biomedical applications | Accuracy, precision, recall, F1-score [13] [45] |
Both AlexNet and ResNet50 offer distinct advantages for biomedical image classification through transfer learning. AlexNet provides a computationally efficient architecture suitable for applications with stricter hardware constraints or where extreme depth is unnecessary. However, ResNet50 consistently demonstrates superior performance across diverse biomedical classification tasks, with experimental results showing significant advantages in accuracy (6% higher in direct comparisons) and robustness, particularly for complex visual patterns [13].
The residual learning framework of ResNet50 enables effective training of substantially deeper networks, making it particularly valuable for biomedical applications requiring hierarchical feature extraction from images with nuanced pathological manifestations [45] [44]. When implementing these architectures for biomedical data, particularly lower-quality images, researchers should prioritize domain-adapted pre-training, strategic fine-tuning methodologies, and appropriate preprocessing pipelines to maximize clinical relevance and diagnostic accuracy.
Adapting Model Input Layers and Early Stages for Noisy or Low-Contrast Images
The classification of noisy or low-contrast images presents significant challenges in computer vision, particularly in critical fields like medical imaging and security. The adaptation of model input layers and early stages becomes paramount for maintaining classification accuracy under these suboptimal conditions. Within the broader research context comparing AlexNet and ResNet50 architectures, this guide objectively examines their respective performance, experimental methodologies, and adaptation strategies for handling challenging visual data. These architectures represent different evolutionary stages in deep learning development, with AlexNet's pioneering design contrasting with ResNet50's sophisticated residual learning framework, each exhibiting distinct characteristics when confronting image quality issues.
Research demonstrates that the fundamental architectural differences between these models significantly influence their noise robustness and contrast sensitivity. Studies across various domains, from medical imaging to traditional food classification, provide quantitative evidence of their performance disparities. This analysis synthesizes findings from multiple experimental protocols to offer researchers and practitioners evidence-based guidance for model selection and adaptation strategies specific to noisy and low-contrast image classification tasks.
Architectural Comparison for Challenging Visual Conditions
AlexNet and ResNet50 employ fundamentally different approaches to feature extraction, which directly impacts their performance on degraded images. AlexNet's simpler architecture comprises five convolutional layers followed by three fully-connected layers, utilizing a relatively straightforward feedforward structure with local response normalization and overlapping pooling. In contrast, ResNet50 introduces residual learning through skip connections that mitigate vanishing gradient problems in deeper networks, enabling the training of 50 layers while maintaining gradient flow. These architectural distinctions create complementary strengths for handling image quality challenges.
Key Architectural Differentiators:
Input Processing: AlexNet processes input images through substantial 11×11 filters in its first convolutional layer, enabling broader receptive fields but potentially transmitting more high-frequency noise. ResNet50 employs a 7×7 convolutional filter at its input stage followed by max pooling, creating a different initial downsampling approach.
Feature Preservation: ResNet50's residual connections explicitly facilitate the propagation of both low-level and high-level features throughout the network, potentially preserving critical information from low-contrast regions that might be lost in AlexNet's more sequential processing.
Representation Capacity: With its substantially greater depth, ResNet50 can learn more complex, hierarchical representations that may better disentangle signal from noise in challenging imaging conditions.
Experimental evidence from direct comparisons reveals that ResNet50 consistently outperforms AlexNet across various image classification tasks. In traditional Indonesian food image classification, ResNet50 achieved 92% accuracy compared to AlexNet's 86% [13]. This performance advantage extends to precision, recall, and F1-score metrics, suggesting that deeper architectures with sophisticated connections offer superior capability for learning discriminative visual patterns from diverse and challenging image sources.
Performance Analysis and Experimental Data
Quantitative comparisons across multiple domains provide compelling evidence regarding the relative performance of AlexNet and ResNet50 under various image quality conditions. The following table summarizes key experimental findings from published studies:
Table 1: Performance Comparison of AlexNet and ResNet50 Across Different Applications
| Application Domain | Model | Accuracy | Precision | Recall | F1-Score | Reference |
|---|---|---|---|---|---|---|
| Traditional Food Classification | AlexNet | 86% | Not Reported | Not Reported | Not Reported | [13] |
| Traditional Food Classification | ResNet50 | 92% | Not Reported | Not Reported | Not Reported | [13] |
| Pedestrian Crash Diagrams | AlexNet | Highest | Highest | Not Reported | Highest | [9] |
| Pedestrian Crash Diagrams | ResNet50 | Lower | Lower | Not Reported | Lower | [9] |
| Breast Cancer Ultrasound | AlexNet | Effective | Not Reported | Not Reported | Not Reported | [46] |
| Pneumonia Detection (X-ray) | ResNet50 | High | High | High | High | [47] |
The performance advantages vary by application domain, with ResNet50 generally excelling in natural image classification while AlexNet demonstrates surprising effectiveness in certain specialized domains like diagram analysis. For medical imaging tasks involving inherently noisy data like ultrasound images, AlexNet has been successfully employed as a feature extractor when combined with specialized preprocessing and feature discrimination techniques [46]. The model achieved effective performance in classifying breast ultrasound images into benign, malignant, and normal categories when integrated with a Siamese architecture and hash layer for enhanced feature discrimination.
For chest X-ray classification, an enhanced ResNet50 model incorporating multi-feature fusion demonstrated robust pneumonia detection capabilities by integrating deep features with handcrafted texture descriptors like Local Binary Patterns (LBP) [47]. This hybrid approach addressed ResNet50's potential limitations in capturing fine-grained texture patterns essential for medical diagnosis, achieving high accuracy, sensitivity, and specificity through complementary feature integration.
Adaptation Methodologies for Noisy and Low-Contrast Conditions
Input Layer Modifications
Adapting models for noisy and low-contrast images requires specialized preprocessing and architectural adjustments. For AlexNet, research has demonstrated that injecting Gaussian noise at the input level during training can improve robustness, inspired by neural mechanisms in biological sensory processing [48]. This approach, when applied to a time-distributed adaptation of AlexNet for human activity recognition, achieved 91.40% accuracy and 92.77% F1-score, outperforming other state-of-the-art models on the EduNet dataset.
For ResNet50, effective noise suppression has been achieved through Multiscale Curvelet Filtering with Directional Denoising (MCF-DD) as a preprocessing step [47]. This technique dynamically identifies and suppresses both Poisson and Gaussian noise while preserving fine structural details critical for accurate diagnosis in medical imaging. The integration of MCF-DD with ResNet50 significantly enhanced pneumonia detection performance from chest X-rays.
Feature Space Enhancement
Enhancing the discriminative capability of features extracted from noisy or low-contrast images represents another effective adaptation strategy. For AlexNet applied to breast ultrasound classification, researchers integrated a hash layer within a Siamese architecture to emphasize similarities within classes and dissimilarities across different classes [46]. This approach specifically addressed the challenge of fine-grained features and subtle details in ultrasound images that often lead to indistinguishable features between categories.
ResNet50 has been successfully enhanced through hybrid feature fusion strategies that combine deep multiscale features from ResNet-50 with handcrafted descriptors like Local Binary Patterns [47]. This integration of semantic and structural information improved feature diversity and classification performance for noisy medical images. The addition of attention mechanisms further enhanced model interpretability by highlighting diagnostically relevant regions.
Table 2: Adaptation Techniques for Noisy and Low-Contrast Images
| Adaptation Technique | Applicable Model | Methodology | Performance Benefit |
|---|---|---|---|
| Gaussian Noise Injection | AlexNet | Injecting noise during training to simulate real-world variations [48] | Improved robustness and generalization, 91.4% accuracy on HAR |
| Multiscale Curvelet Filtering | ResNet50 | Directional denoising while preserving structural details [47] | Enhanced noise suppression for medical images |
| Siamese Architecture with Hash Layer | AlexNet | Emphasizing intra-class similarity and inter-class dissimilarity [46] | Improved discrimination of fine-grained features in ultrasound |
| Hybrid Feature Fusion | ResNet50 | Combining deep features with handcrafted texture descriptors [47] | Enhanced feature diversity and classification accuracy |
| Precision Attention Mechanisms | ResNet50 | Highlighting diagnostically relevant regions [47] | Improved interpretability and focused feature extraction |
Self-Supervised Approaches for Noise Robustness
Emerging research in self-supervised learning presents promising alternatives to supervised approaches for noisy image classification. The "Ditch the Denoiser" framework enables noise-robust representation learning without requiring a denoiser at inference or downstream fine-tuning [49]. This method employs a denoised-to-noisy data curriculum, first training on denoised samples before progressing to noisy ones, combined with teacher-guided regularization that anchors noisy embeddings to their denoised counterparts.
On ImageNet-1k with ViT-B under extreme Gaussian noise (SNR = 0.72 dB), this approach improved linear probing accuracy by 4.8% over DINOv2, demonstrating that denoiser-free robustness can emerge from noise-aware pretraining [49]. While this research utilized vision transformers rather than AlexNet or ResNet50, the fundamental curriculum learning approach could potentially be adapted to CNN architectures.
Experimental Protocols and Methodologies
Noise Injection Protocol for AlexNet
The experimental protocol for enhancing AlexNet's noise robustness through Gaussian noise injection involves carefully controlled procedures [48]:
Noise Configuration: Gaussian noise with standard deviation (σ) parameter optimized through systematic exploration across 17 values, with optimal performance observed at σ = 0.01.
Training Regimen: Noise introduced exclusively during training phases to simulate real-world variability while maintaining clean inference conditions.
Architecture Adaptation: For temporal tasks, AlexNet adapted to time-distributed framework processing video sequences while maintaining spatial feature extraction capabilities.
Evaluation Metrics: Comprehensive assessment using accuracy, F1-score, and stability measurements across multiple runs with statistical validation.
This protocol demonstrated that controlled noise injection serves as an effective regularizer, reducing overfitting while improving generalization to unseen scenarios with different noise characteristics.
ResNet50 Enhancement Methodology
The experimental methodology for enhancing ResNet50 performance on noisy medical images involves multi-stage processing [47]:
Preprocessing Stage: Implementation of Multiscale Curvelet Filtering with Directional Denoising (MCF-DD) for targeted noise suppression while preserving diagnostic details.
Feature Extraction: Simultaneous extraction of deep features from ResNet-50 and handcrafted texture descriptors using Local Binary Patterns.
Feature Fusion: Strategic combination of deep and handcrafted features through concatenation and dimensionality reduction.
Attention Integration: Incorporation of Convolutional Block Attention Module (CBAM) to selectively weight spatial and channel-wise informative features.
Validation Framework: Rigorous testing on Kaggle chest radiograph dataset using accuracy, sensitivity, specificity, and visual explanation quality assessment.
This comprehensive approach addressed multiple limitations of standard CNN models when applied to noisy medical images, particularly their inadequate handling of image noise and neglect of fine-grained texture patterns.
Implementation Workflows
The adaptation of deep learning models for noisy and low-contrast images follows systematic workflows that transform degraded inputs into reliable classifications. The following diagram illustrates the comparative adaptation approaches for AlexNet and ResNet50:
The adaptation workflows highlight fundamental philosophical differences between the two architectures. AlexNet adaptations typically employ noise injection and architectural additions like Siamese networks to enhance robustness [48] [46]. In contrast, ResNet50 approaches emphasize sophisticated preprocessing and hybrid feature strategies that leverage the model's greater representational capacity [47].
For self-supervised approaches that can be applied to either architecture, the noise curriculum framework follows this structured process:
This self-supervised framework enables models to develop inherent noise robustness without permanent dependency on denoising components [49]. The curriculum approach progressively transitions from denoised to noisy inputs while regularization maintains alignment with cleaner representations, resulting in models that can directly process noisy inputs during inference without additional preprocessing overhead.
Research Reagent Solutions
Implementing effective adaptations for noisy and low-contrast image classification requires specialized computational "reagents" - software components and methodologies that enable robust performance. The following table details essential solutions referenced in the experimental studies:
Table 3: Research Reagent Solutions for Image Quality Adaptation
| Research Reagent | Function | Application Context | Implementation Example |
|---|---|---|---|
| Gaussian Noise Injection | Regularization technique that improves model generalization to noisy inputs [48] | AlexNet-based systems for human activity recognition | Systematic optimization of noise standard deviation (σ=0.01 optimal) |
| Multiscale Curvelet Filtering (MCF-DD) | Directional denoising that preserves structural details while suppressing noise [47] | ResNet50 for medical image diagnosis | Preprocessing step for chest X-ray pneumonia detection |
| Siamese Architecture with Hash Layer | Enhances feature discrimination for fine-grained image classes [46] | AlexNet for breast ultrasound classification | Feature space disentanglement for benign/malignant/normal categories |
| Hybrid Feature Fusion | Combines deep semantic features with handcrafted texture descriptors [47] | ResNet50 enhancement for medical imaging | Integration of ResNet-50 features with Local Binary Patterns |
| Convolutional Block Attention Module (CBAM) | Attention mechanism that highlights diagnostically relevant regions [47] | Interpretable deep learning for medical diagnosis | Spatial and channel-wise attention in pneumonia detection |
| Noise Curriculum Learning | Self-supervised approach for noise-robust representation learning [49] | General framework applicable to multiple architectures | Denoised-to-noisy training progression with teacher regularization |
| Boruta-SHAP Algorithm | Feature selection method that identifies important features while reducing dimensionality [46] | Medical image classification with high-dimensional features | Integration with Random Forest classifier for ultrasound images |
These research reagents represent essential tools for adapting deep learning models to challenging image conditions. The selection of specific reagents should align with both the target architecture and the particular noise or contrast challenges present in the application domain.
The adaptation of model input layers and early stages for noisy or low-contrast images requires architecture-specific approaches tailored to the particular challenges of each application domain. Experimental evidence indicates that ResNet50 generally achieves higher accuracy in natural image classification tasks, with demonstrated performance of 92% versus AlexNet's 86% in traditional food classification [13]. However, AlexNet maintains competitive advantage in certain specialized domains such as pedestrian crash diagram analysis [9], and can be effectively enhanced through noise injection and feature discrimination techniques for medical imaging applications [46].
The choice between architectures should consider computational constraints, dataset characteristics, and specific noise profiles. ResNet50's superior performance comes with increased computational requirements, while AlexNet offers efficiency advantages in resource-constrained environments [9]. Emerging approaches like self-supervised noise curriculum learning present promising directions for developing inherently robust models without dependency on external denoising components [49]. Future research should explore hybrid approaches that combine the architectural strengths of both models with advanced adaptation techniques to further advance the state of robust image classification under challenging conditions.
The exponential growth of medical and scientific image data has positioned deep learning as a cornerstone for automated classification systems. However, a significant portion of this data, derived from sources like historical archives, portable field equipment, or rapid screening protocols, is often of low resolution. This presents a formidable challenge for computer vision models, which must identify critical patterns from limited pixel information. The choice of neural network architecture is therefore paramount, balancing the ability to discern subtle features with computational efficiency. This case study provides a structured, objective comparison of two seminal convolutional neural networks (CNNs)—AlexNet and ResNet-50—specifically for the classification of low-resolution medical and scientific imagery. Framed within the context of a broader thesis on image quality, we dissect their performance through published experimental data, detailed methodologies, and an analysis of their respective strengths and limitations for this specialized task.
The fundamental difference between AlexNet and ResNet-50 lies in their approach to network depth and feature learning, which directly influences their performance on complex, low-detail images.
AlexNet: As a pioneering deep CNN, AlexNet introduced the use of Rectified Linear Units (ReLU), dropout for regularization, and overlapping max-pooling. Its architecture, while deep for its time, is relatively shallow by modern standards. This can limit its ability to learn the complex, hierarchical features often necessary to distinguish between fine-grained visual patterns in low-resolution scientific images [13].
ResNet-50: The core innovation of ResNet-50 is the residual block, which utilizes skip connections to mitigate the vanishing gradient problem. This allows for the training of substantially deeper networks (50 layers) without performance degradation [50]. These connections enable the network to focus on learning residual functions, making it exceptionally effective at capturing intricate details from images where salient features are subtle or scarce [51]. This architecture is particularly adept at handling the high intra-class variance and low inter-class variance common in medical imagery [52].
Table 1: Fundamental Architectural Comparison
| Feature | AlexNet | ResNet-50 |
|---|---|---|
| Depth | 8 layers | 50 layers |
| Core Innovation | ReLU, Dropout | Residual Blocks / Skip Connections |
| Parameter Count | ~60 million | ~25 million |
| Strength for Low-Res | Faster computation on small images | Superior feature learning from limited data |
| Key Limitation | Limited hierarchical feature extraction | Higher computational demand per epoch |
Performance Comparison in Low-Resolution Scenarios
Direct and indirect experimental evidence consistently demonstrates that ResNet-50 outperforms AlexNet in classification tasks, especially as image complexity increases.
A direct comparative study on image classification reinforces this architectural advantage. When classifying a dataset of over 4,000 images across 24 categories of Indonesian traditional food, ResNet-50 achieved a significantly higher average accuracy of 92%, compared to 86% for AlexNet. The ResNet-50 model also demonstrated superior performance across all evaluation metrics, including precision, recall, and F1-score [13]. This indicates that the deeper, more complex ResNet-50 architecture is more effective at learning discriminative visual patterns from diverse image sets.
Furthermore, research into the specific challenges of low-resolution medical image classification highlights the limitations of simpler models. One study noted that AlexNet, along with other CNNs with randomly initialized parameters, demonstrated poor overall classification accuracy and a tendency to overfit when faced with challenging datasets. This often necessitates the use of transfer learning and hyperparameter tuning to achieve viable performance [53].
Table 2: Quantitative Performance Comparison
| Experiment Context | AlexNet Performance | ResNet-50 Performance | Key Insight |
|---|---|---|---|
| Traditional Food Classification [13] | 86% Accuracy | 92% Accuracy | ResNet-50 shows superior accuracy and F1-score on a general image dataset. |
| Chest X-ray Diagnosis [54] | - | Optimal AUC at 256x256 px | Diagnoses like nodules benefit from higher resolution, favoring deeper networks. |
| Diabetic Retinopathy Detection [53] | 73.04% Accuracy (from scratch) | 78.68% Accuracy (from scratch) | Both models prone to overfitting without transfer learning, with ResNet-50 having a baseline advantage. |
Detailed Experimental Protocols
To ensure the reproducibility of the comparative findings cited in this guide, the following section outlines the standard experimental methodologies employed in the referenced studies.
Protocol 1: General Image Classification (Food)
This protocol is derived from the comparative study of AlexNet and ResNet-50 [13].
- Dataset Curation: The dataset was compiled from two sources: a Kaggle dataset of traditional Indonesian cakes and a custom-collected set of images of Cirebon's traditional dishes. The final combined dataset contained over 4,000 images spanning 24 distinct food categories.
- Image Preprocessing: All images were resized to a uniform input dimension of 224x224 pixels. Data augmentation techniques were applied to the training samples to increase variation and improve model robustness. Images were normalized according to the standard input format required by each model.
- Training Configuration: The training process utilized 5-Fold Cross Validation. This method ensures that the performance metrics are not dependent on a particular train-test split, providing a more reliable estimate of model generalization.
- Performance Evaluation: Model performance was evaluated using a standard suite of metrics: accuracy, precision, recall, and F1-score.
Protocol 2: Medical Image Resolution Analysis
This protocol is based on research examining CNN performance as a function of image resolution for chest X-ray diagnosis [54].
- Dataset: The study used the publicly available National Institutes of Health (NIH) ChestX-ray14 dataset, comprising 112,120 frontal-view chest X-ray images from 30,805 patients.
- Resolution Manipulation: The original images, stored at 1024x1024 pixels, were resized to a spectrum of lower resolutions for model input, ranging from 32x32 to 600x600 pixels. The default bilinear interpolation method was used for resizing.
- Model Training & Evaluation: Binary decision networks were trained separately for each diagnostic label (e.g., emphysema, nodules, masses). The primary performance metric was the Area Under the Receiver Operating Characteristic curve (AUC). The study tracked how AUC changed with input resolution for different pathologies, identifying diagnosis-specific optimal resolution ranges.
Workflow and Architecture Visualization
Experimental Workflow for Low-Resolution Image Classification
The following diagram illustrates a generalized experimental workflow for comparing the performance of AlexNet and ResNet-50 on low-resolution medical and scientific imagery, as drawn from the cited methodologies [54] [13] [53].
ResNet-50 Residual Block Mechanism
The key to ResNet-50's success is its residual learning block, which overcomes the vanishing gradient problem and enables effective training of very deep networks. The following diagram details this core mechanism [51] [50].
The Scientist's Toolkit: Essential Research Reagents
The following table details key computational tools and materials essential for conducting rigorous experiments in low-resolution image classification, as utilized in the featured studies.
Table 3: Key Research Reagents and Computational Tools
| Item Name | Function / Application |
|---|---|
| Pre-trained Models (ImageNet) | Provides initial weights for transfer learning, significantly reducing training time and improving performance, especially on small datasets [54] [53]. |
| Data Augmentation Pipelines | Generates additional training data via rotations, flips, and contrast adjustments, crucial for combating overfitting and improving model generalization [13] [53]. |
| NIH ChestX-ray14 Dataset | A large-scale public dataset of chest X-rays used for training and validating models on thoracic disease classification across multiple resolutions [54]. |
| Kaggle DR Dataset | A public dataset of fundus images used for developing and benchmarking models for diabetic retinopathy detection [53]. |
| FastAI / PyTorch Libraries | High-level and mid-level deep learning libraries that facilitate rapid prototyping, training, and evaluation of models like ResNet-50 and AlexNet [54]. |
| Weighted Cross-Entropy Loss | A loss function modification used to handle class imbalance in medical datasets by assigning higher weights to under-represented classes [54]. |
Optimizing Performance and Overcoming Pitfalls in Low-Quality Image Classification
Addressing the Vanishing Gradient Problem in Deep Networks for Poor Data
The vanishing gradient problem is a fundamental challenge in training deep neural networks, where gradients become exponentially small as they are propagated back through the layers during training. This issue severely impedes weight updates in earlier layers, causing slow convergence, suboptimal performance, and ineffective learning of complex patterns. The problem is particularly acute when dealing with poor quality or limited data, where robust feature extraction is paramount.
This article presents a comparative analysis of two seminal convolutional neural network architectures—AlexNet and ResNet-50—in addressing the vanishing gradient problem, with a specific focus on their applicability to low-quality image classification tasks. We examine their architectural innovations, theoretical foundations, and empirical performance to provide researchers with actionable insights for selecting and implementing appropriate deep learning solutions in data-constrained environments.
Architectural Comparison: Core Innovations Against Vanishing Gradients
AlexNet: The Pioneering Approach
AlexNet, the 2012 ImageNet competition winner, introduced several key innovations that implicitly helped mitigate the vanishing gradient problem in deeper networks than were previously feasible [3].
Rectified Linear Unit (ReLU) Activation: AlexNet replaced traditional saturating activation functions (sigmoid, tanh) with the non-saturating ReLU function ((f(x) = max(0,x))) [55] [3]. This was pivotal because ReLU's derivative is either 0 or 1, preventing the multiplicative shrinking of gradients that occurs when derivatives less than 1 are multiplied repeatedly during backpropagation [56] [57]. The constant gradient for positive inputs enables more stable gradient flow through deep networks.
Local Response Normalization (LRN): This technique implemented a form of lateral inhibition, normalizing neuron responses across adjacent channels [55] [3]. By promoting competition between units computed using different kernels, LRN encouraged more balanced activation patterns that could indirectly support healthier gradient flow.
Multi-GPU Training: AlexNet's parallel training across two GPUs enabled feasible training of deeper networks by distributing computational load [55]. While not directly solving vanishing gradients, this architectural decision demonstrated the feasibility of training deeper models where the problem becomes more pronounced.
ResNet-50: Explicit Gradient Flow Architecture
ResNet-50 introduced a more direct and revolutionary solution to the vanishing gradient problem through its fundamental architectural innovation: skip connections [58] [59].
Residual Learning Framework: Instead of expecting stacked layers to learn an underlying mapping ((H(x))), ResNet-50 reformulates the learning objective to residual functions ((F(x) = H(x) - x)) [58] [59]. The original input is preserved through identity skip connections and added to the transformed output ((H(x) = F(x) + x)). This ensures that critical information and gradients can bypass nonlinear transformations, creating uninterrupted pathways through the network depth.
Identity and Convolutional Blocks: ResNet-50 implements two types of residual blocks [58]. Identity blocks maintain the same input and output dimensions, allowing direct addition. Convolutional blocks include 1×1 convolutions in skip connections to match dimensions when necessary, preserving the residual learning principle throughout the architecture.
Gradient Preservation Mechanism: During backpropagation, gradients can flow directly through skip connections without multiplicative attenuation [59]. This prevents the exponential decay of gradient magnitude as depth increases, enabling effective training of very deep networks with 50 or more layers.
Table 1: Architectural Solutions to Vanishing Gradients
| Architecture | Core Innovation | Mechanism of Action | Gradient Flow Impact |
|---|---|---|---|
| AlexNet | ReLU Activation | Non-saturating function with derivative 0 or 1 | Prevents multiplicative gradient shrinkage for positive inputs |
| AlexNet | Local Response Normalization | Normalizes adjacent channel responses | Indirectly supports balanced activation patterns |
| ResNet-50 | Skip Connections | Identity mapping bypassing nonlinear layers | Provides direct gradient pathways without attenuation |
| ResNet-50 | Residual Learning | Learning residual functions rather than complete transformations | Preserves signal magnitude and gradient information |
Experimental Performance and Comparative Analysis
Methodology for Experimental Comparison
To objectively evaluate how these architectural differences translate to practical performance, especially with challenging data, we analyze experimental results from multiple studies employing standardized evaluation protocols.
Dataset Preparation and Preprocessing: Studies typically resize input images to 224×224 pixels for both architectures to ensure compatibility [13] [9]. Data augmentation techniques including random cropping, flipping, and color jittering are applied to increase effective dataset size and diversity—particularly crucial for poor quality or limited datasets [13] [3].
Training Protocols: Models are trained using stochastic gradient descent with momentum, with AlexNet traditionally using a higher initial learning rate (0.01) compared to ResNet-50 (0.001) [3]. Batch normalization in ResNet-50 stabilizes training and allows for more aggressive learning rates [56] [60]. Cross-entropy loss serves as the common optimization objective for classification tasks.
Evaluation Metrics: Standard classification metrics including accuracy, precision, recall, and F1-score are employed [13] [9]. The area under the ROC curve (AUC) provides additional insight into model discrimination capability, particularly valuable for imbalanced datasets common in real-world applications with poor data [10].
Performance Comparison on Image Classification Tasks
Traditional Food Image Classification: A comprehensive study comparing AlexNet and ResNet-50 on Indonesian traditional food images (24 categories, >4,000 images) demonstrated ResNet-50's superior performance with 92% accuracy versus AlexNet's 86% [13]. The deeper architecture with skip connections showed particular advantage in handling the visual diversity and variability in image quality typical of real-world food imagery.
Pedestrian Crash Diagram Analysis: Interestingly, in classifying pedestrian crash diagrams (5,437 diagrams), AlexNet achieved the highest accuracy and computational efficiency [9]. This suggests that for certain specialized domains with limited data complexity, excessively deep architectures may not provide advantages and could potentially increase overfitting risk without commensurate performance gains.
Medical Imaging Applications: In breast cancer histopathology image classification (BreakHis dataset), ResNet-50 achieved exceptional performance with an AUC of 0.999 in binary classification tasks [10]. The robust gradient flow enabled effective training on medically complex images where subtle features are critical, even with challenging staining variations and image quality issues.
Table 2: Experimental Performance Comparison
| Dataset/Task | AlexNet Accuracy | ResNet-50 Accuracy | Key Observations |
|---|---|---|---|
| Traditional Food Images [13] | 86% | 92% | ResNet-50 better handles visual diversity and quality variations |
| Pedestrian Crash Diagrams [9] | Highest Accuracy | Lower than AlexNet | AlexNet more efficient for less complex visual patterns |
| Breast Cancer Classification [10] | Not Reported | AUC: 0.999 | ResNet-50 excels at complex medical image interpretation |
Architectural Workflows and Gradient Flow Visualization
AlexNet Gradient Flow Pathway
The following diagram illustrates the gradient flow path through AlexNet's architecture, highlighting key components that influence gradient propagation:
AlexNet Gradient Flow Pathway
AlexNet's architecture shows a sequential flow where gradients must pass through multiple layers during backpropagation. The ReLU activation points (green) provide critical non-saturating gradient pathways, while normalization and dropout layers (blue) introduce potential gradient modulation points that can affect flow stability.
ResNet-50 Residual Block Structure
The residual block design fundamental to ResNet-50's approach to preserving gradients is illustrated below:
ResNet-50 Residual Block Structure
The residual block demonstrates the critical skip connection that allows the input (x) to bypass the convolutional layers and be directly added to the transformed output (F(x)). This identity pathway enables unobstructed gradient flow during backpropagation, directly countering the vanishing gradient problem by providing a "shortcut" for gradients to propagate through deep networks.
For researchers implementing these architectures, particularly for challenging data environments, the following tools and techniques are essential:
Table 3: Research Reagent Solutions for Vanishing Gradient Mitigation
| Resource Category | Specific Solutions | Function & Application |
|---|---|---|
| Activation Functions | ReLU, Leaky ReLU, ELU | Provide non-saturating gradients to prevent vanishing; ReLU introduced in AlexNet, variants improve performance [56] [60] |
| Architectural Components | Skip Connections, Residual Blocks | Enable direct gradient pathways through identity mappings; core innovation in ResNet-50 [58] [59] |
| Normalization Techniques | Batch Normalization, Local Response Normalization | Stabilize training and improve gradient flow; LRN in AlexNet, BatchNorm in ResNet-50 [56] [60] |
| Optimization Algorithms | SGD with Momentum, Adam | Efficiently navigate loss landscapes with unstable gradients; both architectures use momentum-based optimizers [3] |
| Regularization Methods | Dropout, Weight Decay | Prevent overfitting especially important with limited data; Dropout critical in AlexNet FC layers [3] |
| Data Augmentation | Random Cropping, Flipping, Color Jittering | Artificially expand dataset size and diversity; used extensively in both architectures' training [13] [3] |
The comparative analysis reveals that AlexNet and ResNet-50 employ fundamentally different strategies to address the vanishing gradient problem, with distinct implications for researchers working with poor quality data.
AlexNet's contributions—particularly the ReLU activation function—represent an important evolutionary step in enabling deeper networks than previously possible. Its architectural efficiency makes it surprisingly competitive for certain specialized domains with limited visual complexity, as demonstrated in the pedestrian crash diagram classification [9]. However, its sequential architecture ultimately limits gradient flow in very deep networks.
ResNet-50's revolutionary skip connection architecture provides a more direct and scalable solution to the vanishing gradient problem, enabling unprecedented network depths while maintaining stable gradient flow. This makes it particularly valuable for complex visual tasks with diverse, noisy, or limited data, as evidenced by its superior performance in food image classification and medical imaging applications [13] [10].
For researchers selecting architectures for challenging data environments, the choice involves balancing architectural complexity against data characteristics and computational resources. While ResNet-50 generally provides superior performance for complex visual patterns, AlexNet's efficiency advantages in specific domains highlight that architectural selection must be context-dependent. Future research directions include developing adaptive architectures that dynamically adjust connectivity patterns based on data quality and complexity, potentially bridging the efficiency-performance gap exemplified by these foundational models.
The challenge of overfitting presents a significant obstacle in the application of deep learning to image classification, particularly when working with small or noisy datasets. This problem becomes especially pronounced in critical domains such as medical imaging and drug development, where data is often limited and quality can be compromised. As models grow in complexity to achieve higher accuracy, their capacity to memorize dataset noise and idiosyncrasies increases, leading to poor generalization on unseen data. Regularization techniques have emerged as essential tools to address this challenge by constraining model complexity and encouraging the learning of more robust, generalizable features.
Within this context, architectural selection plays a fundamental role in determining a model's inherent susceptibility to overfitting. This article provides a comparative analysis of two influential convolutional neural network architectures—AlexNet and ResNet50—evaluating their performance characteristics and responsiveness to regularization when applied to low-quality image classification tasks. Through systematic experimentation and data-driven comparison, we aim to provide researchers with practical insights for selecting and optimizing models for resource-constrained research environments.
Architectural Comparison: AlexNet vs. ResNet50
AlexNet and ResNet50 represent two significant milestones in the evolution of deep learning architectures for computer vision. Understanding their fundamental differences is crucial for selecting the appropriate architecture for specific research applications, particularly when dealing with limited or noisy data.
AlexNet, pioneered in 2012, introduced groundbreaking techniques that demonstrated the potential of deep learning for image classification. Its architecture consists of five convolutional layers, followed by max-pooling layers, and three fully-connected layers for classification [61]. Key innovations included the use of the ReLU (Rectified Linear Unit) activation function to mitigate the vanishing gradient problem, GPU acceleration to enable training on large datasets, dropout regularization to reduce overfitting, and data augmentation through image transformations [61]. The model's relative simplicity, with approximately 60 million parameters, makes it computationally efficient and less prone to overfitting when data is limited.
ResNet50, introduced in 2015, addressed the fundamental challenge of training very deep networks through its revolutionary residual learning framework. The architecture contains 50 layers built around skip connections that bypass one or more layers [62]. These residual connections enable unimpeded gradient flow during backpropagation, mitigating the vanishing gradient problem that previously limited network depth. This architectural innovation allows ResNet50 to leverage greater depth for learning more complex features while maintaining trainability. However, this increased capacity (approximately 25 million parameters) requires careful regularization to prevent overfitting on small datasets.
Table 1: Fundamental Architectural Comparison
| Feature | AlexNet | ResNet50 |
|---|---|---|
| Depth | 8 layers (5 convolutional, 3 fully-connected) | 50 layers with residual connections |
| Key Innovation | ReLU, Dropout, GPU training | Skip connections, batch normalization |
| Parameter Count | ~60 million | ~25 million |
| Inherent Regularization | Dropout in fully-connected layers | Batch normalization throughout |
| Computational Efficiency | Higher | Lower |
| Feature Learning Approach | Progressive feature hierarchy | Residual learning with identity mappings |
Experimental Performance Comparison
Benchmark Results on Standardized Tasks
Controlled experiments across diverse image classification domains reveal distinct performance patterns for AlexNet and ResNet50 architectures, particularly in contexts resembling real-world research constraints. These comparisons provide valuable insights into the trade-offs between model complexity and generalization capability.
In a systematic study comparing regularization techniques on the Imagenette dataset, ResNet18 (a smaller variant of ResNet50) achieved superior validation accuracy (82.37%) compared to a baseline CNN (68.74%) when both models were trained with appropriate regularization [62]. The study highlighted that regularization consistently reduced overfitting and improved generalization across all scenarios, with transfer learning providing additional performance gains through faster convergence and higher accuracy compared to training from scratch [62].
A direct comparison on Indonesian traditional food image classification demonstrated ResNet50's advantage in handling diverse visual patterns, achieving 92% accuracy compared to AlexNet's 86% [13]. The deeper architecture proved more effective at learning complex visual patterns, with consistently superior performance across precision, recall, and F1-score metrics [13]. However, this advantage presupposes sufficient data quantity and quality, conditions not always present in research settings.
Conversely, in specialized domains with distinctive data characteristics, AlexNet sometimes demonstrated superior performance. In classifying pedestrian crash diagrams for transportation safety research, AlexNet consistently surpassed both ResNet50 and VGG-19 across multiple evaluation metrics [9]. The study concluded that AlexNet emerged as the most computationally efficient model, highlighting the critical importance of architecture selection based on specific dataset characteristics and resource constraints [9].
Table 2: Cross-Domain Performance Comparison
| Application Domain | Dataset | AlexNet Accuracy | ResNet50 Accuracy | Key Findings |
|---|---|---|---|---|
| Traditional Food Classification | 24 categories, >4,000 images | 86% | 92% | ResNet50 superior across all metrics [13] |
| Pedestrian Crash Diagram Analysis | Michigan UD-10 reports | Highest accuracy & F1-score | Lower performance | AlexNet most computationally efficient [9] |
| General Image Classification | Imagenette dataset | Not reported | 82.37% (ResNet18) | Regularization crucial for generalization [62] |
Performance on Small and Noisy Datasets
The performance gap between architectures often narrows or reverses when training data is limited or contaminated with noise, conditions frequently encountered in research applications.
Research on human activity recognition using a time-distributed AlexNet adaptation demonstrated remarkable robustness when combined with noise injection techniques [48]. The bio-inspired approach of adding Gaussian noise during training improved model resilience to real-world visual perturbations, achieving 91.40% accuracy and a 92.77% F1-score on the EduNet dataset [48]. This demonstrates that simpler architectures, when properly regularized, can achieve state-of-the-art performance on specialized tasks with limited data.
In oil and gas well operations, an AlexNet-based model for casing collar identification achieved maximum F1 scores improving from 0.937 and 0.952 to 1.0 after implementing comprehensive data augmentation and regularization techniques including standardization, label distribution smoothing, and random cropping [63]. The success with limited real-world data highlights the importance of tailored preprocessing methods for small datasets.
Regularization Techniques: Experimental Protocols
Data Augmentation and Noise Injection
Protocol 1: Gaussian Noise Injection for Enhanced Robustness
Gaussian noise injection introduces random perturbations with zero mean and controllable standard deviation to input data during training, creating a low-pass filtering effect that discourages learning of high-frequency noise [48] [64].
- Implementation: Add Gaussian noise with standard deviation (σ) as a tunable hyperparameter to input images before feeding them to the network. Optimal values typically range from 0.01-0.1, requiring empirical validation for specific datasets [48].
- Experimental Setup: In human activity recognition research, 17 different noise values were systematically evaluated, with σ=0.01 identified as optimal [48].
- Application: During training only; models are evaluated on clean data without noise injection [65].
- Theoretical Basis: Noise injection is mathematically equivalent to imposing a penalty on the squared magnitude of the network function's first derivatives, encouraging smoother decision boundaries [48].
Protocol 2: Comprehensive Data Augmentation Pipeline
Data augmentation artificially expands training datasets by applying label-preserving transformations, reducing reliance on limited original samples.
- Image Transformations: Implement random rotations (±10°), horizontal flips (50% probability), random crops (85-100% of original area), and color jitter (brightness, contrast, saturation adjustments up to 10%) [66] [61].
- Advanced Techniques: For small datasets (<1,000 samples per class), employ CutMix or MixUp which combine images and labels to create mixed training examples [66].
- Synthetic Data Generation: In extreme data scarcity, utilize GANs or diffusion models to generate synthetic training samples, particularly effective when domain-specific simulators are available [66].
Diagram 1: Data augmentation workflow for regularization
Architectural and Training Regularization
Protocol 3: Dropout Implementation for AlexNet and ResNet50
Dropout randomly deactivates a proportion of neurons during training, preventing complex co-adaptations and creating an implicit ensemble of sub-networks.
- AlexNet Implementation: Apply dropout with rate 0.5 in the first two fully-connected layers (as in original implementation) [61]. For enhanced regularization, consider adding dropout (rate 0.2-0.3) in later convolutional layers.
- ResNet50 Adaptation: Incorporate dropout (rate 0.2-0.3) within residual blocks, particularly before the final fully-connected layer. Alternatively, employ stochastic depth which randomly drops entire layers during training [62].
- Training/Inference Difference: During training, neurons are randomly dropped; during inference, all neurons are active with weights scaled by dropout rate [61].
Protocol 4: Transfer Learning with Fine-tuning
Leverage pre-trained models on large datasets (e.g., ImageNet) and adapt them to specific research domains with limited data.
- Feature Extraction: Remove the original classification head, freeze all base layers, and add a new task-specific head. Train only the new layers [66].
- Progressive Fine-tuning: Unfreeze layers gradually from top to bottom with decreasing learning rates, allowing specialized adaptation without severe overfitting [62].
- Differential Learning Rates: Apply higher learning rates to newly added layers and lower rates to pre-trained layers [66].
Diagram 2: Transfer learning strategies for small datasets
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Research Reagents for Regularization Experiments
| Research Reagent | Function | Implementation Example |
|---|---|---|
| Gaussian Noise Module | Introduces controlled randomness to inputs | TensorFlow: GaussianNoise(stddev=0.1) layer [65] |
| Dropout Layer | Randomly deactivates neurons during training | PyTorch: nn.Dropout(p=0.5) [61] |
| Batch Normalization | Stabilizes training, adds slight regularization | nn.BatchNorm2d() in ResNet50 [62] |
| Data Augmentation Pipeline | Expands effective dataset size | TensorFlow: ImageDataGenerator with rotation, flip, zoom [66] |
| Label Smoothing Regularization | Prevents overconfident predictions | PyTorch: CrossEntropyLoss with label_smoothing=0.1 [63] |
| Learning Rate Scheduler | Adjusts learning rate during training | Cosine annealing or ReduceLROnPlateau [66] |
| Early Stopping Callback | Halts training when validation performance plateaus | Monitor validation loss with patience=10 epochs [66] |
Implementation Guide and Best Practices
Architecture Selection Framework
Choosing between AlexNet and ResNet50 requires careful consideration of dataset characteristics, computational resources, and performance requirements:
- Select AlexNet when: Working with very small datasets (<5,000 images), limited computational resources, requiring rapid prototyping, or operating in domains with distinctive features that don't require extreme depth [9] [61].
- Select ResNet50 when: Dataset is sufficiently large (>10,000 images), computational resources are adequate, task requires capturing complex hierarchical features, or state-of-the-art accuracy is critical [13] [62].
- Hybrid Approach: For moderate datasets, consider using ResNet50 with aggressive regularization or exploring intermediate architectures like ResNet18 [62].
Optimized Regularization Stacks
Based on experimental evidence, the following regularization stacks have proven effective for each architecture:
AlexNet Regularization Stack:
- Input-level Gaussian noise (σ=0.05) [48]
- Standard data augmentation (rotation, flips, crops) [61]
- Dropout (rate 0.5) in fully-connected layers [61]
- Weight decay (L2 regularization λ=0.0005) [62]
- Early stopping based on validation accuracy
ResNet50 Regularization Stack:
- Advanced data augmentation (MixUp or CutMix) [66]
- Label smoothing regularization (ε=0.1) [63]
- Stochastic depth (survival probability 0.8) [62]
- Moderate weight decay (λ=0.0001) [62]
- Learning rate scheduling with warm restarts
Diagram 3: Architecture selection and regularization framework
The systematic comparison of AlexNet and ResNet50 reveals that architectural selection represents a fundamental regularization decision in itself. While ResNet50 generally achieves superior performance on large, clean datasets, AlexNet demonstrates remarkable effectiveness in resource-constrained environments and specialized domains where its simplicity becomes an advantage against overfitting.
Experimental evidence consistently shows that appropriate regularization strategies can significantly narrow the performance gap between architectures, with noise injection, data augmentation, and transfer learning proving particularly effective for small and noisy datasets. The optimal approach combines architectural selection tailored to specific data constraints with a carefully designed regularization stack that addresses each architecture's unique vulnerabilities.
For researchers working with limited or noisy image data in fields such as drug development and medical imaging, these findings underscore the importance of matching model complexity to data availability. Rather than universally pursuing the deepest available architecture, maximum performance and robustness often emerge from strategic architecture selection complemented by targeted regularization techniques.
For researchers in fields like drug development, selecting the appropriate deep learning model is a critical decision that balances classification performance with computational cost. When comparing two foundational architectures—AlexNet and ResNet-50—for tasks such as low-quality image classification, understanding their resource demands is as important as understanding their accuracy. This guide provides an objective comparison of their training time and hardware consumption, supported by experimental data, to inform resource-conscious research.
The core architectural differences between AlexNet and ResNet-50 fundamentally dictate their computational profiles. AlexNet, a pioneering deep convolutional neural network (CNN), is characterized by a simpler sequential stack of convolutional and fully connected layers. [42] In contrast, ResNet-50 is a much deeper network that introduced the concept of residual connections (or "skip connections"). [67] These connections allow gradients to flow directly through the network, mitigating the vanishing gradient problem and making the training of its 50 layers feasible. [67]
This structural difference has a direct impact on computational demands. While the depth of ResNet-50 enables it to learn more complex features, it also inherently requires more parameters and floating-point operations (FLOPs) to compute compared to the shallower AlexNet. However, the efficiency of these operations can vary significantly depending on the underlying hardware, such as GPUs or TPUs, which are designed for the parallel processing required by these models. [68]
Performance and Resource Consumption: A Quantitative Comparison
Direct, controlled comparisons of AlexNet and ResNet-50 highlight a consistent trade-off between speed and accuracy. The following table synthesizes experimental findings from multiple studies.
Table 1: Direct Comparative Performance of AlexNet and ResNet-50
| Study Context | Model | Reported Accuracy | Training/Inference Speed | Key Finding on Efficiency |
|---|---|---|---|---|
| Pedestrian Crash Diagram Classification [9] | AlexNet | Highest Accuracy & F1-Score | Most Efficient Model | AlexNet surpassed deeper models in both accuracy and computational efficiency for this specific task. |
| ResNet-50 | Lower than AlexNet | Less Efficient than AlexNet | ||
| Traditional Indonesian Food Classification [13] | AlexNet | 86% | Information Not Specified | ResNet-50's superior accuracy came from its deeper, more complex architecture, which typically requires more computation. |
| ResNet-50 | 92% | Information Not Specified | ||
| Chest Radiograph Classification [69] | AlexNet (shallow) | Comparable to deeper nets | Shorter training times | Shallower networks achieved results comparable to deeper ones like ResNet-50 with reduced resource requirements. |
| ResNet-50 (deep) | Comparable to shallow nets | Longer training times |
Beyond direct comparisons, benchmarking ResNet-50 across various hardware platforms illustrates how resource demands translate into real-world performance, which can also inform expectations for AlexNet's relative performance.
Table 2: ResNet-50 Benchmarking on Diverse Hardware Platforms [70] [67]
| Hardware Platform | Hardware Type | Key Performance Metric | Result & Implication |
|---|---|---|---|
| NVIDIA RTX 3060 (Laptop) | Consumer GPU | Training Speed (vs. Apple M3 Pro baseline) | ~2x faster training speed. Demonstrates the significant boost from dedicated, even mid-range, GPUs. |
| Google Colab Tesla T4 (Cloud) | Cloud GPU | Training Speed (vs. Apple M3 Pro baseline) | ~2x faster training speed. Highlights the viability of free-tier cloud resources for rapid prototyping. |
| Intel NUC & NVIDIA Jetson Nano (Edge) | Edge Computing Device | Inference Time / Model Size | Quantization reduced model size by 73-74% and inference times by 56-68% with minimal accuracy loss. [67] |
Experimental Protocols for Benchmarking
To ensure fair and reproducible comparisons of computational efficiency, researchers should adhere to a standardized benchmarking workflow. The following diagram outlines the key stages of this process.
The methodology for benchmarking model efficiency involves several critical stages, from hardware selection to data analysis. Key protocols include:
- Hardware Setup: Experiments should be run on dedicated hardware. Common choices include consumer-grade NVIDIA GPUs (e.g., RTX 3060), cloud instances (e.g., with Tesla T4), or edge devices (e.g., Jetson Nano). [70] [67] The specific GPU memory (VRAM) must be reported, as it directly limits feasible batch sizes. [70]
- Software Environment: For reproducibility, the entire software stack, including Python, PyTorch (or TensorFlow), and all dependencies, should be containerized using tools like Docker. [70] This ensures that performance differences are attributable to hardware or models, not software versions.
- Data Preparation and Preprocessing: A standard dataset and preprocessing pipeline must be applied to all models. This typically involves resizing images to a consistent resolution (e.g., 224x224 pixels), normalization, and applying identical data augmentation techniques (e.g., random flipping, cropping). [13] [70] [69]
- Model Preparation: Both models should be initialized with pre-trained weights from large-scale datasets like ImageNet, a common practice known as transfer learning. [42] This provides a fair starting point and is especially relevant for tasks with limited data, such as medical imaging. [69] [42]
- Training Configuration: Models must be trained under identical conditions: the same number of epochs, optimizer (e.g., SGD with momentum), learning rate, and most critically, the same batch size. [69] If VRAM constraints prevent using the same batch size for all models, this must be explicitly stated as a limitation.
- Metric Collection: Beyond final accuracy, crucial efficiency metrics must be collected: epoch duration (training time), inference latency (time per prediction), and peak memory usage (VRAM consumption). [70] [67] To ensure stable measurements, initial "warm-up" epochs should be discarded. [70]
The Scientist's Toolkit: Key Research Reagents and Solutions
To conduct a rigorous computational efficiency study, the following "reagents"—software and hardware components—are essential.
Table 3: Essential Research Reagents for Computational Benchmarking
| Research Reagent | Function / Description | Relevance to Comparison |
|---|---|---|
| Pre-trained Models (ImageNet) | Models whose weights are initialized from training on the vast ImageNet dataset. [42] | Serves as a common, optimal starting point for both AlexNet and ResNet-50, enabling faster convergence and fairer comparison. |
| PyTorch / TensorFlow | Open-source deep learning frameworks that provide standardized implementations of models and layers. | Offers pre-built, optimized modules for AlexNet, ResNet-50, and training loops, ensuring consistency and reducing implementation error. |
| NVIDIA CUDA & cuDNN | Parallel computing platform and library for accelerating operations on NVIDIA GPUs. [68] | Critical for achieving high throughput during training and inference. Must be kept consistent across tests for fair comparison. |
| Docker Containers | Technology to package software and its dependencies into a standardized, isolated unit. [70] | Guarantees an identical software environment across different hardware platforms, making benchmark results reproducible and reliable. |
| Model Quantization Tools | Techniques to reduce model precision (e.g., from 32-bit to 8-bit). [67] | A key method for deploying models like ResNet-50 on resource-constrained edge devices by drastically reducing model size and latency. |
The choice between AlexNet and ResNet-50 involves a direct trade-off. ResNet-50, with its superior depth and residual connections, generally achieves higher accuracy on complex image recognition tasks. [13] [67] However, this comes at the cost of greater computational demands for both training and inference. [9] [69]
For researchers, the optimal choice is context-dependent. AlexNet is a strong candidate when computational resources are severely limited, inference speed is critical, or for tasks on simpler datasets where its representational power is sufficient. [9] [69] ResNet-50 should be the choice when the primary goal is maximizing classification accuracy and sufficient GPU resources are available for its deeper architecture. For deployment on edge devices, quantization is a highly effective strategy to make ResNet-50 viable, offering a compelling balance of performance and efficiency. [67]
The classification of low-quality images presents significant challenges in medical and industrial research, where factors like noise, low resolution, and artifacts can severely impact diagnostic and analytical outcomes. Within this context, the comparative performance of deep learning architectures, particularly AlexNet and ResNet-50, becomes a critical area of investigation. This guide provides an objective comparison of these two architectures when enhanced with advanced techniques—specifically attention mechanisms and specialized pooling layers—for classifying low-quality images. We summarize experimental data from recent studies and detail the methodologies used to evaluate their performance, providing researchers with actionable insights for model selection and optimization.
Architectural Comparison: AlexNet vs. ResNet-50
The fundamental differences between AlexNet and ResNet-50 architectures define their baseline capabilities and limitations for image classification tasks. AlexNet, a pioneering deep convolutional network, consists of eight primary layers: five convolutional and three fully-connected layers, utilizing ReLU activation functions and local response normalization for non-linear transformation [1] [43]. Its moderate depth and parameter count (approximately 60 million parameters) make it computationally less intensive but potentially limited in feature abstraction capacity [43].
In contrast, ResNet-50 employs a substantially deeper architecture with 50 layers, incorporating residual learning frameworks that mitigate vanishing gradient problems through skip connections [47] [71]. This enables more effective training of very deep networks and superior hierarchical feature extraction. The residual blocks facilitate both local and global feature integration, making ResNet-50 particularly adept at capturing complex patterns in challenging visual data [72].
Table 1: Baseline Architectural Specifications
| Feature | AlexNet | ResNet-50 |
|---|---|---|
| Depth | 8 layers (5 convolutional, 3 fully-connected) | 50 layers with residual connections |
| Parameter Count | ~60 million | ~25.5 million |
| Key Innovation | ReLU activation, overlapping pooling [43] | Residual learning, batch normalization [71] |
| Computational Requirements | Moderate | Higher due to depth |
| Typical Input Size | 224×224 or 227×227 [1] | 224×224 [72] |
Enhancement Techniques for Low-Quality Image Classification
Attention Mechanisms
Attention mechanisms enable networks to selectively focus on informative regions of feature maps while suppressing irrelevant information. The Convolutional Block Attention Module (CBAM) sequentially applies channel and spatial attention to refine intermediate features [27]. In industrial heritage damage detection, integrating CBAM with AlexNet (creating AlexNet HCS) improved accuracy by 1.8% with only a 3.5% increase in FLOPs and 4ms inference delay [27].
For ResNet-50, external attention mechanisms have been successfully incorporated by replacing 3×3 convolutions in residual structures, enhancing global information perception [72]. This modification allows the model to better grasp input characteristics while maintaining computational efficiency.
Specialized Pooling Methods
Traditional max and average pooling operations often lead to information loss, particularly for fine-grained features in low-quality images [73]. The T-Max-Avg pooling method incorporates a threshold parameter T that selects the K highest interacting pixels, enabling adaptive switching between maximum value retention and weighted averaging [73]. This approach has demonstrated superior performance on benchmark datasets including CIFAR-10, CIFAR-100, and MNIST compared to standard pooling operations.
Experimental Comparison on Low-Quality Image Datasets
Medical Imaging Applications
In medical domains where image quality is frequently suboptimal, both architectures have been extensively tested. An enhanced ResNet-50 model incorporating multi-feature fusion and Multiscale Curvelet Filtering with Directional Denoising achieved notable performance in pneumonia detection from chest X-rays [47]. The model combined deep features from ResNet-50 with handcrafted texture descriptors like Local Binary Patterns, leveraging both semantic and structural information.
For AlexNet, an anemia detection model implementing multiple spatial attention mechanisms achieved exceptional accuracy (99.58%) using conjunctival pallor images [74]. The model employed a modified AlexNet architecture with specialized attention modules after the final pooling layer to highlight diagnostically relevant features.
Table 2: Performance Comparison on Medical Image Classification
| Model | Application | Dataset | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| ResNet-50 with Multi-Feature Fusion [47] | Pneumonia Detection | Kaggle Chest Radiograph | High (exact values not specified) | High | High | High |
| Enhanced ResNet-50 [71] | Lung Cancer Detection | CT Scans | 92% | Not specified | Not specified | Not specified |
| AlexNet with Multiple Spatial Attention [74] | Anemia Detection | Conjunctival Images | 99.58% | High | High | High |
| Enhanced ResNet-50 with External Attention [72] | Diabetic Retinopathy | Kaggle Fundus Images | 96.68% | Not specified | Not specified | Not specified |
Industrial and Specialized Applications
For industrial heritage damage detection, an optimized AlexNet HCS model (incorporating CBAM and SVM) achieved 95.7% accuracy, representing a 12.2% improvement over the baseline AlexNet HSD model [27]. The model demonstrated precise identification of structural damage in historical buildings under challenging imaging conditions.
Diagram: AlexNet HCS workflow for damage detection [27]
Detailed Experimental Protocols
Protocol 1: ResNet-50 for Medical Image Classification
The enhanced ResNet-50 framework for pneumonia detection employed a comprehensive methodology [47]:
- Preprocessing: Implemented Multiscale Curvelet Filtering with Directional Denoising to suppress noise while preserving diagnostic details.
- Feature Extraction: Utilized ResNet-50 for deep feature extraction combined with handcrafted texture descriptors.
- Attention Integration: Incorporated precision attention mechanisms to highlight diagnostically relevant regions.
- Training: Employed Sophia optimizer instead of traditional Adam optimizer to accelerate convergence and improve training stability [72].
- Validation: Conducted on Kaggle chest radiograph dataset with metrics including accuracy, sensitivity, and specificity.
Protocol 2: AlexNet for Industrial Damage Detection
The AlexNet HCS model for industrial heritage assessment followed this experimental design [27]:
- Dataset Composition: Combined xView2 Building Damage Assessment Dataset with photos of third-line construction buildings in Southwest China.
- Architectural Modifications:
- Integrated CBAM after convolutional layers to enhance spatial and semantic perception.
- Replaced traditional fully-connected layers with SVM classifier for improved robustness.
- Implemented DropBlock in Conv5 layer to further inhibit overfitting.
- Training Parameters: Used momentum gradient descent with batch size of 128, momentum of 0.9, and weight decay of 0.0005.
- Evaluation Metrics: Assessed using accuracy, precision, recall, and F1-score with comprehensive ablation studies.
Diagram: Enhanced ResNet-50 workflow for medical images [47]
The Scientist's Toolkit: Essential Research Reagents
Table 3: Key Experimental Components and Their Functions
| Component | Function | Example Implementation |
|---|---|---|
| Convolutional Block Attention Module (CBAM) | Sequentially refines channel and spatial dimensions of feature maps | AlexNet HCS model for heritage damage detection [27] |
| Multiscale Curvelet Filtering with Directional Denoising | Suppresses noise while preserving critical diagnostic details | ResNet-50 pneumonia detection framework [47] |
| T-Max-Avg Pooling | Adaptive pooling that balances feature preservation and information compression | Alternative to max/average pooling in CNN architectures [73] |
| SVM Classifier | Provides robust classification with strong generalization capabilities | Replacement for fully-connected layers in AlexNet HCS [27] |
| Sophia Optimizer | Optimizes training process with momentum and adaptive learning rates | Enhanced ResNet-50 for diabetic retinopathy classification [72] |
| Multi-Feature Fusion | Combines deep learned features with handcrafted texture descriptors | ResNet-50 pneumonia detection combining CNN features with LBP [47] |
Based on experimental evidence, AlexNet demonstrates superior performance in scenarios with limited computational resources or smaller datasets, particularly when enhanced with attention mechanisms and SVM classifiers. Its architectural simplicity enables effective training even with constrained data availability [27] [74].
ResNet-50 excels in more complex classification tasks requiring hierarchical feature extraction from significantly degraded images. The residual connections facilitate training of very deep networks, while attention mechanisms further enhance focus on semantically relevant regions [47] [72].
Table 4: Architecture Selection Guidelines
| Scenario | Recommended Architecture | Rationale |
|---|---|---|
| Limited Computational Resources | Enhanced AlexNet with CBAM | Lower computational requirements with significant accuracy gains [27] |
| Highly Degraded Medical Images | Enhanced ResNet-50 with Multi-Feature Fusion | Superior hierarchical feature extraction from noisy data [47] |
| Small Dataset Availability | AlexNet with Spatial Attention | Effective training convergence with limited samples [74] |
| Fine-Grained Texture Analysis | ResNet-50 with External Attention | Enhanced global and local feature integration [72] |
| Real-Time Applications | AlexNet with T-Max-Avg Pooling | Balanced performance and computational efficiency [73] |
Experimental results indicate that the strategic incorporation of attention mechanisms and specialized pooling methods significantly enhances both architectures' capabilities for low-quality image classification. The selection between AlexNet and ResNet-50 should be guided by specific application requirements, data constraints, and computational resources available to researchers.
Hyperparameter Tuning for Stable Convergence on Challenging Image Data
Hyperparameter tuning is a critical and computationally expensive challenge in deep learning, significantly impacting model performance, convergence stability, and generalization on complex image data. For convolutional neural networks (CNNs) like AlexNet and ResNet-50, which are widely used for image classification, selecting optimal hyperparameters is essential for achieving high accuracy and efficient training, particularly with low-quality or challenging datasets. The performance of these models is highly dependent on a correct configuration of parameters such as learning rate, batch size, and network topology, which collectively influence the model's ability to learn intricate patterns without overfitting [75] [76].
This guide provides an objective, data-driven comparison of AlexNet and ResNet-50, focusing on their responsiveness to hyperparameter optimization techniques. We synthesize experimental data from recent studies to outline effective tuning protocols and offer practical guidance for researchers working with demanding image classification tasks, such as in medical imaging or noisy data environments.
Performance Comparison of AlexNet and ResNet-50
Table 1: Base Performance Comparison on Image Classification Tasks
| Model | Base Architecture | Typical Parameter Count | Reported Accuracy (Indonesian Food Images) [13] | Reported Accuracy (Pedestrian Crash Diagrams) [9] |
|---|---|---|---|---|
| AlexNet | 8 layers, traditional CNN | ~60 million | 86% | Highest accuracy & F1-score |
| ResNet-50 | 50 layers with residual connections | ~25 million | 92% | Lower than AlexNet |
Table 2: Performance Gains from Hyperparameter Optimization
| Model | Optimization Technique | Key Hyperparameters Tuned | Performance Gain & Results |
|---|---|---|---|
| ResNet-50 | Whale Optimization Algorithm (WOA) [77] | Learning rate, dropout rate, batch size | Achieved 99.54% accuracy on liver tumor segmentation (LiTS17 dataset) |
| ResNet-18 | Multi-Strategy Parrot Optimizer (MSPO) [78] | Learning rate, batch size, number of network layers | Notable improvements in accuracy, precision, recall, and F1-score on BreaKHis breast cancer dataset |
| Lightweight CNNs | Comprehensive ablation (Cosine decay, RandAugment) [79] | Learning rate schedule, batch size, data augmentation | Absolute gains of 1.5–2.5% in Top-1 accuracy (e.g., ConvNeXt-T from 77.61% to 81.61%) |
The comparative performance between AlexNet and ResNet-50 is not absolute but is heavily influenced by the dataset and the application of hyperparameter optimization (HPO). ResNet-50 consistently demonstrates the capacity to achieve higher peak accuracy on complex natural image datasets when properly tuned, largely due to its deeper, more complex architecture with residual connections that mitigate vanishing gradients [13]. In contrast, AlexNet can be the optimal choice for specific, less complex tasks or under strict computational constraints, as it emerged as the most accurate and efficient model for classifying features in pedestrian crash diagrams [9]. Furthermore, HPO techniques can dramatically boost the performance of both architectures, with bio-inspired algorithms like the Whale Optimization Algorithm enabling ResNet-50-based models to achieve exceptional accuracy upwards of 99% on specialized medical imaging tasks [77].
Experimental Protocols for Hyperparameter Tuning
Key Tuning Methodologies
Several advanced methodologies have been empirically validated for optimizing CNN hyperparameters.
- Genetic Algorithm (GA) for CNN Tuning: An Ensemble Genetic Algorithm and CNN (EGACNN) model uses a GA to optimize the number of layers, kernel size, learning rates, dropout rates, and batch sizes. The process begins with an initial population of CNN architectures, each evaluated on a validation set. Through iterative evolution, genetic operations like crossover and mutation produce new architectures, with selection mechanisms favoring individuals with higher fitness (e.g., classification accuracy). This approach achieved 99.91% accuracy on the MNIST dataset [75].
- Whale Optimization Algorithm (WOA) with ResNet-50: A hybrid LiTS-Res-UNet + WOA framework was designed for liver tumor segmentation. In this setup, WOA adaptively fine-tunes a set of interdependent hyperparameters—including learning rate, dropout rate, and batch size—dynamically during the training of the ResNet-50–U-Net model. This creates a meta-optimization layer where the outer loop uses WOA to optimize hyperparameters based on the validation Dice score, while the inner loop updates network weights via backpropagation. This method achieved 99.54% accuracy on the LiTS17 benchmark [77].
- Systematic Ablation of Training Hyperparameters: A large-scale benchmarking study on lightweight models established a protocol focusing on critical training hyperparameters. The key steps include:
- Learning Rate Scheduling: Implementing a cosine decay schedule instead of step decay for smoother convergence.
- Batch Size Adjustment: Using larger batch sizes (e.g., 512) with linear learning rate scaling and warm-up for stability.
- Data Augmentation & Regularization: Employing a composite pipeline including RandAugment, Mixup, CutMix, and Label Smoothing to improve generalization.
- Optimizer Selection: Choosing between SGD with momentum (often better for CNNs) and AdamW (often better for transformers and hybrid models) [79].
Workflow for Hyperparameter Optimization
The following diagram illustrates a generalized workflow for applying optimization algorithms to tune CNN hyperparameters, integrating elements from the GA and WOA approaches.
The Researcher's Toolkit: Essential Reagents & Materials
Table 3: Key Research Reagent Solutions for Hyperparameter Optimization
| Item | Function in Research | Example Use Case |
|---|---|---|
| Genetic Algorithm (GA) | A metaheuristic optimization technique that explores a wide hyperparameter space to find near-optimal configurations by mimicking natural selection [75]. | Optimizing the number of layers, kernel size, and learning rates in a CNN for handwritten digit classification [75]. |
| Whale Optimization Algorithm (WOA) | A bio-inspired algorithm that simulates the bubble-net hunting behavior of humpback whales, suitable for navigating complex, multi-modal solution spaces [77]. | Dynamically tuning learning rate, dropout rate, and batch size for a ResNet-50-U-Net hybrid model in liver tumor segmentation [77]. |
| Multi-Strategy Parrot Optimizer (MSPO) | An enhanced metaheuristic integrating Sobol sequence initialization and nonlinear decreasing inertia weight to improve global exploration and convergence steadiness [78]. | Tuning hyperparameters of a ResNet18 model for breast cancer image classification on the BreaKHis dataset [78]. |
| RandAugment | An automated data augmentation policy that randomly selects from a set of transformations to enhance training data variation and model robustness [79]. | Part of a composite augmentation pipeline to boost the accuracy of lightweight models like EfficientNetV2-S and ConvNeXt-T [79]. |
| Cosine Learning Rate Decay | A scheduling strategy that reduces the learning rate smoothly following a cosine curve, often leading to better convergence stability than step decay [79]. | Used in training ConvNeXt-T and other lightweight architectures to achieve higher Top-1 accuracy on ImageNet-1K [79]. |
The choice between AlexNet and ResNet-50 for challenging image data is context-dependent. ResNet-50 generally possesses a higher performance ceiling for complex tasks, especially when leveraging advanced HPO. AlexNet remains a compelling, computationally efficient alternative for specific, well-defined problems. The critical factor for achieving stable convergence and maximal accuracy for either architecture is the implementation of a systematic hyperparameter optimization strategy. As evidenced by the experimental data, modern techniques—ranging from ablation studies of training parameters to bio-inspired metaheuristic algorithms—can yield significant performance gains, transforming a model's capability to handle low-quality and complex image data.
Benchmarking AlexNet vs. ResNet50: A Rigorous Performance Validation Framework
In the empirical comparison of deep learning models like AlexNet and ResNet50, performance metrics transform subjective observations into quantifiable, comparable evidence. These metrics are fundamental in computer vision research, providing a standardized language to evaluate how effectively a model transforms input data into accurate predictions [80]. For specific tasks such as low-quality image classification—a common challenge in medical imaging or real-world surveillance—the choice of metrics becomes even more critical. A model must not only be correct in ideal conditions but also robust under ambiguity, noise, and limited visual information [31].
This guide focuses on the essential quartet of evaluation metrics—Accuracy, Precision, Recall, and F1-Score—within the context of comparing two seminal architectures: AlexNet and ResNet50. We will dissect their computational formulas, interpret their practical significance, and apply them to real experimental data. The objective is to provide researchers with a clear framework for conducting a performance analysis that is both thorough and reproducible, enabling informed decisions in model selection for resource-constrained or low-data-fidelity environments.
Defining the Core Evaluation Metrics
The performance of a classification model is most commonly evaluated using four core metrics, which are derived from a model's confusion matrix. A confusion matrix is a table that summarizes the number of correct and incorrect predictions, broken down by the actual and predicted classes. For binary classification, it consists of four key elements:
- True Positives (TP): The number of positive instances correctly identified by the model.
- True Negatives (TN): The number of negative instances correctly identified by the model.
- False Positives (FP): The number of negative instances incorrectly classified as positive (Type I error).
- False Negatives (FN): The number of positive instances incorrectly classified as negative (Type II error).
These four elements form the basis for calculating the following metrics:
Accuracy: Measures the overall correctness of the model. It answers the question: "Out of all the predictions, what fraction was correct?"
Accuracy = (TP + TN) / (TP + TN + FP + FN)Precision: Measures the reliability of the positive predictions. It answers the question: "When the model predicts a positive class, how often is it correct?" This is crucial in applications where the cost of a false positive is high.
Precision = TP / (TP + FP)Recall (Sensitivity): Measures the model's ability to detect all relevant positive instances. It answers the question: "Out of all the actual positive instances, what fraction did the model successfully find?" This is critical when missing a positive instance (false negative) is costly.
Recall = TP / (TP + FN)F1-Score: The harmonic mean of Precision and Recall. It provides a single metric that balances the trade-off between the two. A high F1-score indicates that the model has both good precision and good recall.
F1-Score = 2 * (Precision * Recall) / (Precision + Recall)
The following diagram illustrates the logical relationships between the core components of the confusion matrix and the resulting metrics:
Experimental Protocol for Model Comparison
To ensure a fair and reproducible comparison between AlexNet and ResNet50, a standardized experimental protocol must be followed. The methodology below outlines the key steps from data preparation to performance assessment.
Dataset Selection and Preprocessing
The foundation of any robust experiment is a representative dataset. For studying low-quality image classification, researchers often use public benchmarks like ImageNet or specialized datasets that simulate real-world conditions. A typical protocol involves:
- Data Sourcing: Using a dataset with multiple categories, such as the traditional Indonesian food dataset with 24 categories and over 4,000 images [13] or a medical dataset like the CXR image collection for COVID-19 and pneumonia [31].
- Data Splitting: Dividing the dataset into three subsets: a training set (e.g., 70%) for model learning, a validation set (e.g., 15%) for hyperparameter tuning, and a test set (e.g., 15%) for the final, unbiased evaluation.
- Image Preprocessing: Standardizing all images to a fixed input size required by the models (e.g., 224x224 pixels), normalizing pixel values, and applying data augmentation techniques to the training set. Augmentation may include random rotations, flips, and brightness adjustments to improve model generalization and simulate low-quality variations [13] [31].
Model Training and Evaluation
- Training Setup: Both models are trained using the same hardware and software environment. A common practice is to use transfer learning, where models are initialized with weights pre-trained on a large dataset like ImageNet. The training involves using an optimizer (e.g., SGD or Adam), a loss function (e.g., Cross-Entropy Loss), and a fixed number of epochs [13] [31].
- Performance Assessment: After training, the models are evaluated on the held-out test set. Predictions are compared against the ground truth labels to populate the confusion matrix for each model. The core metrics—Accuracy, Precision, Recall, and F1-Score—are then calculated from these matrices [80].
The workflow for this protocol is summarized in the diagram below:
The Scientist's Toolkit: Essential Research Reagents
The following table details key components and their functions required to execute the experimental protocol effectively.
Table: Essential Research Reagents and Materials for Image Classification Experiments
| Item Name | Function/Description | Example in Protocol |
|---|---|---|
| Labeled Image Dataset | A collection of images with annotated categories for supervised learning. Serves as the ground truth for training and evaluation. | Indonesian Food Dataset [13]; CXR Image Dataset [31]. |
| Pre-trained Model Weights | Model parameters previously trained on a large-scale dataset (e.g., ImageNet). Used as a starting point to accelerate training and improve performance via transfer learning. | AlexNet/ResNet50 weights from ImageNet. |
| Deep Learning Framework | A software library that provides the building blocks for designing, training, and validating deep neural networks. | TensorFlow, PyTorch, or Keras [80]. |
| Data Augmentation Pipeline | A software module that algorithmically applies random transformations (rotations, flips, etc.) to training images. Increases dataset diversity and improves model robustness. | Integrated within the deep learning framework during training [13]. |
| Optimization Algorithm | A mathematical procedure that updates model parameters to minimize the loss function during training. | Stochastic Gradient Descent (SGD) or Adam. |
| Evaluation Metrics Script | A custom or library-provided script that computes performance metrics from the model's predictions. | A function that calculates Accuracy, Precision, Recall, and F1-Score from a confusion matrix. |
Comparative Performance: AlexNet vs. ResNet50
Applying the defined metrics and experimental protocol reveals clear performance differences between AlexNet and ResNet50 across various tasks. The following table synthesizes quantitative results from multiple studies.
Table: Comparative Performance Metrics of AlexNet and ResNet50
| Model | Task / Dataset | Accuracy | Precision | Recall | F1-Score | Source/Context |
|---|---|---|---|---|---|---|
| AlexNet | Traditional Food Classification | 86.0% | Not Specified | Not Specified | Not Specified | [13] |
| ResNet50 | Traditional Food Classification | 92.0% | Not Specified | Not Specified | Not Specified | [13] |
| AlexNet | Pedestrian Crash Diagram Classification | Consistently Superior | Highest F1-Score | Implied by F1 | Highest | Outperformed others in this specific study [9] |
| ResNet50 | Rice Leaf Disease Detection | 99.13% | Implied by high accuracy | Implied by high accuracy | Implied by high accuracy | Most accurate & reliable model [81] |
Analysis of Results
Accuracy and Overall Performance: ResNet50 consistently demonstrates a significant advantage in classification accuracy in studies that directly report this metric [81] [13]. Its residual learning framework effectively overcomes the vanishing gradient problem, allowing this deeper network to learn more complex features, which is often beneficial for achieving higher overall correctness.
Precision, Recall, and the F1-Score: The data also highlights that the "best" model is context-dependent. In the pedestrian crash diagram study, AlexNet achieved the highest F1-score, indicating a better balance between precision and recall for that specific task and dataset [9]. This underscores a critical principle: a model with slightly lower overall accuracy might be more practically useful if it demonstrates superior precision (e.g., in medical diagnosis where false positives are critical) or recall (e.g., in security where false negatives are dangerous).
Trade-offs and Practical Considerations: While ResNet50 often achieves higher accuracy, it comes at a computational cost. AlexNet emerged as the most computationally efficient model in the crash diagram study [9]. For applications with strict latency requirements or limited hardware, AlexNet's simpler architecture can provide a favorable trade-off, especially if its performance on key metrics like F1-score is competitive or superior for the task at hand.
The rigorous application of Accuracy, Precision, Recall, and F1-Score is non-negotiable for a meaningful comparison of deep learning models like AlexNet and ResNet50. The experimental data clearly shows that while ResNet50 generally offers higher classification accuracy due to its more advanced architecture, AlexNet remains a potent and sometimes superior candidate in scenarios demanding computational efficiency or where it achieves a more favorable balance between precision and recall, as quantified by the F1-score.
For researchers and developers, the choice of model should not be dictated by a single metric. The decision must be guided by the specific problem constraints: the nature of the "low-quality" data, the criticality of false positives versus false negatives, and the available computational budget. This comparative guide provides the metric-based framework necessary to make that choice objectively. Future work could explore these metrics on a wider array of degraded image datasets and incorporate additional evaluation dimensions, such as model robustness and inference speed, for an even more comprehensive analysis.
This guide provides an objective comparison of the AlexNet and ResNet-50 architectures for low-quality image classification, a common challenge in fields like medical imaging and automated analysis. Ensuring a fair comparison requires a rigorous and standardized experimental setup. The following sections detail the datasets, preprocessing methods, and training protocols used in published studies to enable a direct, evidence-based evaluation of model performance.
Dataset Descriptions for Comparative Studies
The performance of deep learning models is highly dependent on the datasets used for training and evaluation. The table below summarizes key datasets from studies that have directly compared AlexNet and ResNet-50.
Table 1: Overview of Datasets Used in AlexNet vs. ResNet-50 Comparative Studies
| Dataset Name | Domain | Image Count & Dimensions | Number of Classes | Notable Characteristics |
|---|---|---|---|---|
| Indonesian Traditional Food [13] | Food Classification | ~4,000 images (Total) | 24 | Combines images from Kaggle and local dishes; high inter-class similarity [13]. |
| Pedestrian Crash Diagrams [9] | Transportation Safety | 5,437 diagrams (Urban areas) [9] | 6 binary features (e.g., intersection type) | Engineered diagrams; focuses on feature recognition [9]. |
| CXR Images (Medical) [31] | Medical Diagnosis | Not Specified | 3 (Normal, Pneumonia, COVID-19) | High inter-class similarity; challenging for classification [31]. |
| BreakHis (Breast Cancer) [10] | Medical Histopathology | Not Specified | 2 (Binary) & 8 (Multi-class) | Used for evaluating 14 models, including AlexNet and ResNet-50 [10]. |
| ISIC Archive (Skin Lesions) [82] | Medical Dermatology | 50 GB dataset; subset used: 2,501 train, 136 validation, 657 test [82] | Not Specified | Large-scale dataset; often used with transfer learning [82]. |
Data Preprocessing and Augmentation Protocols
Consistent preprocessing and data augmentation are critical for a fair model comparison and to prevent overfitting, especially with limited data.
- Standardization: A common practice is to resize all input images to 224x224 pixels to match the expected input dimensions of standard CNN architectures like AlexNet and ResNet-50 [13] [83].
- Normalization: Pixel values are typically rescaled. For example, one study rescaled images to a range of [0, 1] and then normalized them using mean values of (0.4914, 0.4822, 0.4465) and standard deviations of (0.2023, 0.1994, 0.2010) [83].
- Data Augmentation: To artificially expand the dataset and improve model generalization, researchers apply random transformations. These often include:
Training Methodology for Fair Comparison
A standardized training protocol ensures that performance differences are attributable to model architecture rather than training procedures.
Common Hyperparameters
The table below consolidates hyperparameters used in direct comparative studies.
Table 2: Standardized Training Hyperparameters from Comparative Studies
| Hyperparameter | Indonesian Food Study [13] | Pedestrian Crash Study [9] | ISIC Skin Lesion Study [82] |
|---|---|---|---|
| Optimizer | Not Specified | Not Specified | Adam [82] |
| Learning Rate | Not Specified | Not Specified | 0.0001 [82] |
| Batch Size | Not Specified | Not Specified | 32 [82] |
| Epochs | 5-Fold Cross Validation [13] | Not Specified | 20 [82] |
| Loss Function | Not Specified | Not Specified | CrossEntropyLoss [82] |
Independent ResNet-50 training experiments highlight that the learning rate is a critically important parameter. One study found that a dynamic learning rate schedule, starting at 0.1 and reducing by a factor of 10 after 30 epochs, yielded the best results, outperforming a constant learning rate [84].
Evaluation Metrics
For a comprehensive comparison, studies typically employ a suite of metrics:
- Accuracy: The overall proportion of correct predictions [13] [9].
- Precision and Recall: Measure the model's relevance and completeness, respectively [13].
- F1-Score: The harmonic mean of precision and recall, providing a single metric for balanced evaluation [13] [9].
- Top-k Accuracy: Particularly for ImageNet (1000 classes), Top-5 accuracy checks if the true label is among the top 5 predictions [84].
Experimental Workflow for Model Comparison
The following diagram illustrates the standard experimental workflow for a fair comparison between two deep learning models, from data preparation to performance evaluation.
Architectural Diagrams and Signaling Pathways
A key difference between AlexNet and ResNet-50 is the presence of residual connections, which address the vanishing gradient problem in deeper networks.
Residual Block Structure
The core innovation of ResNet-50 is the residual block, which uses skip connections to allow gradients to flow more directly through the network.
The Scientist's Toolkit: Research Reagent Solutions
This table details the essential computational "reagents" and their functions for conducting a fair comparative study of image classification models.
Table 3: Essential Research Reagents for Deep Learning Comparison
| Research Reagent | Function & Purpose | Exemplars / Notes |
|---|---|---|
| Pre-trained Models | Provides a starting point with weights learned from large datasets (e.g., ImageNet), significantly reducing training time and data requirements. | Models from PyTorch Hub, TensorFlow Hub, Keras Applications [84]. |
| Optimization Algorithms | Adjusts model parameters (weights) to minimize the loss function during training. | SGD with Momentum, Adam [82] [84]. |
| Loss Functions | Quantifies the difference between model predictions and ground truth labels, guiding the optimizer. | CrossEntropyLoss (classification), SoftmaxCrossEntropyWithLogits [82] [83]. |
| Data Augmentation Tools | Artificially increases dataset size and diversity by applying random transformations, improving model generalization. | Random cropping, horizontal flipping, color jittering [83]. |
| Evaluation Metrics | Quantifies model performance and enables objective comparison between different architectures. | Accuracy, Precision, Recall, F1-Score, Top-k Accuracy [13] [84]. |
The classification of low-quality images presents a significant challenge in computer vision, impacting fields from medical diagnostics to autonomous driving. The choice of neural network architecture is critical, as it must be robust to artifacts such as blur, noise, and low resolution that characterize real-world, non-ideal datasets. This guide provides an objective performance comparison of two foundational convolutional neural networks (CNNs)—AlexNet and ResNet-50—in handling low-quality imagery. We synthesize quantitative results from multiple experimental studies, detail standardized evaluation protocols, and visualize methodological workflows to assist researchers and development professionals in selecting appropriate architectures for their specific image classification tasks.
Performance Comparison Tables
Table 1: Comparative performance of AlexNet and ResNet-50 across different studies and datasets.
| Study Context | Model | Accuracy | Precision | Recall | F1-Score | Dataset Specifics |
|---|---|---|---|---|---|---|
| Indonesian Traditional Food Classification [13] | AlexNet | 86% | Not Specified | Not Specified | Not Specified | 24 classes, >4,000 images |
| ResNet-50 | 92% | Not Specified | Not Specified | Not Specified | ||
| Pedestrian Crash Diagram Classification [9] | AlexNet | Highest | Not Specified | Not Specified | Highest | 5,437 diagrams (Urban) |
| ResNet-50 | Lower | Not Specified | Not Specified | Lower | ||
| Waste Electronic Component Classification [85] | AlexNet | ~6.6% increase* | Not Specified | Not Specified | Not Specified | 19 subcategories |
| ResNet-101 | ~5.4% increase* | Not Specified | Not Specified | Not Specified | ||
| Media Painting Style Classification [51] | ResNet-50 (Baseline) | 68.9% | Not Specified | Not Specified | Not Specified | Large-scale style dataset |
| ResNet-50 (Improved) | 80.6% | Not Specified | Not Specified | Not Specified |
Note: Accuracy values for [85] represent the improvement over a baseline after applying a specific data augmentation method. The ResNet-101 result is included as a proxy for the ResNet family's performance in this task.
Computational Efficiency
Table 2: Comparison of model efficiency and resource requirements.
| Metric | AlexNet | ResNet-50 |
|---|---|---|
| Architecture Depth | 8 layers [9] | 50 layers [86] [9] |
| Key Architectural Feature | Sequential Convolutions [9] | Residual Connections with Skip Functions [86] [9] |
| Computational Efficiency | More Efficient [9] | Less Efficient [9] |
| Parameter Count | Lower | Higher |
Experimental Protocols and Workflows
The reliable assessment of model performance on low-quality images depends on rigorous and reproducible experimental protocols. This section details the common methodologies employed across the cited studies.
Standardized Experimental Workflow
The following diagram illustrates a generalized experimental workflow for training and evaluating CNN models on image classification tasks, synthesized from multiple studies [13] [86] [85].
Detailed Methodological Breakdown
Data Preprocessing and Augmentation
Consistent preprocessing is vital for handling low-quality images. A common first step is image resizing to match the input requirements of the CNN (e.g., 224x224 pixels) [13] [83]. This is often followed by normalization, where pixel values are rescaled, for instance, to a range of [0, 1] using a divisor of 255 [83]. Data augmentation is extensively used to enhance the diversity and size of training sets, making models more robust. Standard techniques include [13] [86] [85]:
- Geometric Transformations: Random rotation, horizontal and vertical flipping, and random cropping.
- Photometric Adjustments: Modifying color saturation, brightness, and converting images to grayscale.
- Noise Injection: Adding Gaussian or salt-and-pepper noise to improve model robustness to real-world imperfections.
For more advanced augmentation, Generative Adversarial Networks (GANs) like DCGAN and SRGAN (Super-Resolution GAN) are employed. SRGAN, in particular, can be used to generate high-resolution versions of low-quality images, thereby augmenting the dataset with enhanced samples [85].
Model Training and Evaluation
The training process typically uses a supervised learning approach. A standard loss function for multi-class classification is Cross-Entropy Loss, which penalizes incorrect predictions exponentially [86] [83]. For optimization, the Adam optimizer is a popular choice due to its relatively fast convergence, though the Stochastic Gradient Descent (SGD) optimizer with momentum is also widely used [86] [83].
A critical practice, especially with limited data, is K-Fold Cross-Validation (e.g., 5-Fold). This technique involves partitioning the dataset into 'k' subsets, training the model 'k' times (each time using a different subset as the validation set and the rest as training data), and averaging the results to produce a more robust performance estimate [13].
Performance is evaluated using standard metrics calculated from the confusion matrix (True/False Positives/Negatives):
- Accuracy: (TP+TN)/(TP+TN+FP+FN) - Overall correctness.
- Precision: TP/(TP+FP) - Reliability of positive predictions.
- Recall: TP/(TP+FN) - Ability to find all positive instances.
- F1-Score: Harmonic mean of precision and recall [13] [9].
Table 3: Essential tools, algorithms, and datasets for low-quality image classification research.
| Name | Type | Primary Function | Relevance to Low-Quality Images |
|---|---|---|---|
| SRGAN (Super-Resolution GAN) [85] | Generative Model | Enhances image resolution and detail via adversarial training. | Directly improves input image quality by generating photorealistic high-resolution versions from low-resolution inputs. |
| DCGAN (Deep Convolutional GAN) [85] | Generative Model | Synthesizes new, realistic training images from existing data. | Augments datasets with varied samples, increasing diversity and size to improve model generalization. |
| Structural Similarity Index (SSIM) [85] [87] | Image Quality Metric | Measures the perceptual similarity between a reference and a processed image. | Evaluates the quality of images generated by models like SRGAN, ensuring they are perceptually suitable for downstream tasks. |
| Peak Signal-to-Noise Ratio (PSNR) [85] | Image Quality Metric | Computes the peak error between images as a logarithmic measure. | A standard metric for assessing the fidelity of reconstructed or enhanced images against their original versions. |
| CIFAR-10 [83] | Standardized Dataset | A benchmark dataset of 60,000 32x32 color images in 10 classes. | Serves as a common testbed for evaluating model performance on relatively low-resolution imagery. |
| DIV2K [88] | Standardized Dataset | A high-quality dataset for image super-resolution and restoration. | Provides reference images for training and evaluating super-resolution models like those used in pre-processing. |
| Adam Optimizer [86] | Optimization Algorithm | Adaptive learning rate optimization algorithm for stochastic gradient descent. | Enables efficient and effective model training, which is crucial for complex models dealing with challenging data. |
| 5-Fold Cross-Validation [13] | Evaluation Protocol | Robust method for estimating model performance on limited data. | Reduces the variance of performance estimates, providing a more reliable assessment of a model's true capability. |
The quantitative analysis reveals that the optimal choice between AlexNet and ResNet-50 for low-quality image classification is highly context-dependent. ResNet-50, with its deeper architecture and residual connections, generally achieves superior accuracy on complex, natural image datasets, as demonstrated by its 6% higher accuracy in food image classification [13]. Its design mitigates vanishing gradients, allowing it to learn more complex features effectively. However, AlexNet remains a compelling and sometimes superior choice for specific tasks, particularly those involving diagrammatic or less complex imagery, where it demonstrated higher accuracy and F1-scores than ResNet-50 [9]. Its lower computational demand also makes it suitable for environments with resource constraints. The performance of both architectures is significantly enhanced by rigorous data preparation, including advanced augmentation techniques like those enabled by SRGAN and DCGAN [85]. Researchers should base their selection on a balance of dataset characteristics, desired accuracy, and available computational resources.
In the domain of medical image analysis and scientific research, classifying low-quality images presents a significant challenge. Convolutional Neural Networks (CNNs) have demonstrated remarkable success in image classification tasks, yet their "black box" nature often impedes trust and adoption in critical fields such as drug development and biomedical research [89] [90]. This comparative guide objectively analyzes two fundamental CNN architectures—AlexNet and ResNet-50—for low-quality image classification, with particular emphasis on qualitative analysis through feature map visualization and decision pattern interpretation. By examining how these models arrive at their predictions, researchers can make informed decisions about model selection for sensitive applications where interpretability is paramount.
AlexNet Architecture
AlexNet, the 2012 ImageNet competition winner, established the potential of deep convolutional networks for large-scale visual recognition [1]. The architecture consists of eight primary layers: five convolutional layers and three fully-connected layers [3]. AlexNet introduced several groundbreaking innovations including the ReLU activation function to accelerate training, Local Response Normalization (LRN) to encourage lateral inhibition, and overlapping pooling for enhanced feature invariance [1] [3]. The model was split across two GPUs due to computational constraints, with cross-connections between certain layers [1].
ResNet-50 Architecture
ResNet-50 emerged in 2015 to address the vanishing gradient problem that hampered the training of very deep networks [91]. Its core innovation—skip connections—enables the network to learn identity functions by adding the input of a layer directly to its output [91]. This residual learning framework ensures that adding more layers doesn't degrade performance, allowing for networks with substantially greater depth (50 layers in ResNet-50) [91]. The architecture is organized into stages with varying residual block configurations, progressively reducing spatial dimensions while increasing channel depth [91].
Table: Architectural Comparison of AlexNet and ResNet-50
| Feature | AlexNet | ResNet-50 |
|---|---|---|
| Depth | 8 layers | 50 layers |
| Core Innovation | ReLU, LRN, Overlapping Pooling | Skip Connections |
| Key Advantage | Computational efficiency for moderate-depth networks | Solves vanishing gradient for very deep networks |
| Input Size | 227×227×3 | 224×224×3 |
| Parameter Count | 60 million [1] | ~25.6 million |
Quantitative Performance Comparison
Research studies provide quantitative evidence of how these architectures perform across various image classification tasks, including medical and low-quality image scenarios.
Table: Quantitative Performance Metrics Across Different Applications
| Application Domain | AlexNet Performance | ResNet-50 Performance | Experimental Context |
|---|---|---|---|
| COVID-19 CXR Classification | Not in top 4 models (Top model: VGG-16, 94.3% accuracy) [92] | Accuracy >90% (among top 4 models) [92] | 18 CNN models evaluated on chest X-ray images [92] |
| Noisy QR Code Classification | N/A | XceptionNet (architectural relative): 87.48% accuracy [15] | Classification of 80,000 images with 7 noise types [15] |
| General Image Classification | Top-5 error: 15.3% (ImageNet) [1] | Top-5 error: ~5-7% (ImageNet variants) | Standard benchmark performance |
Methodologies for Visualizing Feature Maps and Decision Patterns
Gradient-Weighted Class Activation Mapping (Grad-CAM)
Grad-CAM is an activation-based method that produces visual explanations for decisions from CNN-based models without architectural changes or re-training [90]. The technique uses the gradients of any target concept flowing into the final convolutional layer to produce a coarse localization map highlighting important regions in the image for predicting the concept [90].
Protocol Implementation:
- Forward Pass: Feed the input image through the network to obtain raw class scores.
- Gradient Calculation: Compute gradients of the score for class (c) (before softmax), (Y^c), with respect to feature map activations (A^k) of a convolutional layer: (\frac{\partial Y^c}{\partial A^k}).
- Neuron Importance Weights: Calculate neuron importance weights (\alphak^c) through Global Average Pooling of gradients: [ \alphak^c = \frac{1}{Z}\sumi\sumj \frac{\partial Y^c}{\partial A_{ij}^k} ]
- Heatmap Generation: Combine weighted feature maps and apply ReLU: [ L{\text{Grad-CAM}}^c = \text{ReLU}\left(\sumk \alpha_k^c A^k\right) ]
- Visualization: Overlay the resulting heatmap on the original image to highlight discriminative regions [90].
Feature CAM: Enhanced Visual Interpretability
Feature CAM represents an advancement in activation-based methods that generates fine-grained, class-discriminative visualizations by combining activation maps with perturbed versions of input images [90]. This approach demonstrates 3-4 times better human interpretability compared to Grad-CAM while preserving machine interpretability (classification confidence scores) [90].
Protocol Implementation:
- Feature Map Extraction: Extract feature maps from multiple convolutional layers.
- Input Perturbation: Generate multiple perturbed versions of the input image through controlled variations.
- Activation-Perturbation Fusion: Combine activation maps with perturbed inputs to create fine-grained visualizations.
- Class-Discriminative Weighting: Apply class-specific weighting to highlight discriminative features.
- Visualization Refinement: Refine visualization through multi-scale aggregation and noise reduction techniques [90].
DISCOVER: Generative Latent Space Disentanglement
DISCOVER is a recently developed generative approach that enables visual interpretability by discovering underlying visual properties driving image-based classification models [89]. The method learns disentangled latent representations where each latent feature encodes a unique classification-driving visual property [89].
Protocol Implementation:
- Adversarial Perceptual Autoencoder: Train an autoencoder with perceptual and adversarial losses to enable high-quality image reconstruction from latent space.
- Classification-Oriented Encoding: Minimize discrepancy between the supervised model's intermediate layers and predictions for both input and reconstructed images.
- Latent Space Disentanglement: Apply disentanglement loss terms to force each latent feature to encode exclusive image properties.
- Counterfactual Explanation Generation: Traverse the latent space one feature at a time to generate exaggerated counterfactual examples that highlight discriminative features [89].
Experimental Framework for Qualitative Analysis
Research Reagent Solutions
Table: Essential Research Reagents for Qualitative CNN Analysis
| Reagent Solution | Function | Implementation Example |
|---|---|---|
| Visualization Libraries | Generate saliency maps and heatmaps | Grad-CAM, Feature CAM implementations |
| Model Interpretation Frameworks | Provide unified API for multiple interpretability methods | Captum, iNNvestigate, tf-explain |
| Data Augmentation Tools | Generate perturbed inputs for robustness testing | TensorFlow Image, Torchvision Transforms |
| Quantitative Evaluation Metrics | Measure interpretability quality | Increase in Confidence, Average Drop, Faithfulness |
| Human Evaluation Protocols | Assess human interpretability | Expert annotation, Visual Turing tests |
Qualitative Assessment Workflow
The experimental workflow for qualitative analysis involves both visualization generation and systematic evaluation to compare how AlexNet and ResNet-50 form their decision patterns, particularly for low-quality images.
Comparative Analysis: Decision Patterns in Low-Quality Images
Feature Map Evolution Across Layers
AlexNet demonstrates more localized feature detection in early layers, focusing on edges, colors, and basic patterns [93]. As visualizations progress to deeper layers, AlexNet shows increasingly abstract but sometimes fragmented representations due to its more limited depth and absence of specialized connections [93] [94].
ResNet-50 maintains feature coherence throughout its deeper architecture, with skip connections preserving foundational visual information across layers [91]. When processing low-quality images, ResNet-50's feature maps show more consistent activation patterns despite noise or resolution limitations, as residual connections provide alternative pathways for gradient flow and feature preservation [91].
Attention Localization in Noisy Environments
In studies comparing multiple CNN architectures for noisy image classification, ResNet variants demonstrated superior performance in maintaining attention on semantically relevant regions despite significant noise corruption [15]. The residual learning framework appears to provide inherent robustness to image quality degradation.
AlexNet exhibits more scattered attention patterns when processing low-quality images, with activation maps highlighting both relevant features and noise artifacts [92] [94]. This suggests less effective filtering of irrelevant information in suboptimal imaging conditions.
Interpretability-Architecture Relationship
The qualitative analysis reveals a fundamental relationship between architectural choices and interpretability:
Network Depth vs. Interpretability: While ResNet-50's greater depth generally provides higher classification accuracy, the feature visualizations can become more abstract and challenging to interpret in the deepest layers without specialized visualization techniques [89] [90].
Skip Connections for Transparency: ResNet-50's residual connections create more traceable decision pathways, as fundamental features preserved through identity mappings remain visible in activation visualizations across network depth [91].
Receptive Field Considerations: AlexNet's larger receptive fields in early layers (11×11 filters) can capture broader contextual information but may reduce localization precision in attention maps compared to ResNet-50's predominantly 3×3 filter structure [1] [91].
Qualitative analysis through feature map visualization reveals distinct decision patterns between AlexNet and ResNet-50 architectures for low-quality image classification. AlexNet provides more transparent but less robust visual explanations, making it suitable for applications where moderate accuracy with higher interpretability is preferred. ResNet-50 demonstrates superior performance in maintaining attention on semantically relevant regions despite image quality degradation, though its deeper architecture requires more advanced visualization techniques for meaningful interpretation.
For researchers in drug development and biomedical fields working with low-quality images, ResNet-50 offers superior classification performance, while AlexNet provides more straightforward interpretability. The emerging visualization techniques such as Feature CAM and DISCOVER significantly enhance model transparency for both architectures, enabling more trustworthy deployment in critical research applications. Future work should focus on developing architecture-specific visualization optimizations that leverage the unique characteristics of each network design for enhanced interpretability.
In the field of deep learning for image classification, the selection of an appropriate convolutional neural network (CNN) architecture is a critical decision that balances performance with computational demand. This guide provides an objective comparison between two landmark models: AlexNet, the pioneering deep CNN known for its efficiency, and ResNet50, a deeper network renowned for its high accuracy. Framed within the context of low-quality image classification research, this analysis synthesizes recent experimental data to help researchers and developers make informed choices based on their specific project constraints, whether they are limited by computational resources or driven by the need for maximum predictive power.
AlexNet, introduced in 2012, revolutionized computer vision by demonstrating the potential of deep CNNs on a large scale. Its victory in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) with a top-5 error rate of 15.3% marked a turning point, showing a significant improvement of over 10% from the runner-up [1] [3]. Architecturally, it consists of eight layers—five convolutional and three fully-connected. Its key innovations included the use of the ReLU activation function to speed up training, dropout for regularization, and the utilization of GPUs to make training deep networks feasible [1] [3].
ResNet50, developed by Microsoft Research in 2015, addressed a fundamental problem in training very deep networks: the vanishing gradient. Its core innovation is the "skip connection" or residual block, which allows gradients to flow directly through the network by bypassing one or more layers [95] [9]. This enables the stable training of networks with 50 layers or more, allowing the model to learn more complex features and achieve higher accuracy on challenging tasks.
Performance Comparison: Experimental Data
Direct comparisons in recent research highlight the inherent trade-offs between these two architectures. The following table summarizes quantitative findings from various studies.
Table 1: Comparative Performance of AlexNet and ResNet50 Across Different Tasks
| Application Domain | Dataset | AlexNet Performance | ResNet50 Performance | Key Takeaway | Source |
|---|---|---|---|---|---|
| Traditional Food Classification | 24 categories, >4,000 images | Accuracy: 86% | Accuracy: 92% | ResNet50's deeper architecture is more effective for learning diverse visual patterns. | [13] |
| Pedestrian Crash Diagram Analysis | 5,437 crash diagrams | Highest Accuracy & F1-score; Most computationally efficient | Lower accuracy than AlexNet | AlexNet's simpler architecture is sufficient and more efficient for certain diagrammatic data. | [9] |
| Robustness to Image Blur | ImageNet (Garbage Truck) | N/A | Accuracy drops as blur increases; fails when key features are obscured. | Highlights a general challenge for CNNs, including ResNet50, with low-quality inputs. | [95] |
These studies demonstrate that performance is highly context-dependent. ResNet50 generally achieves higher accuracy on complex, real-world image classification, as seen in the food classification task [13]. However, for specific data types, such as the simpler, diagrammatic representations in crash reports, AlexNet can surprisingly outperform deeper models while also being more computationally efficient [9].
Experimental Protocols for Benchmarking
To ensure fair and reproducible comparison between architectures, researchers should adhere to a standardized experimental protocol. The methodologies below are synthesized from the analyzed studies.
Table 2: Key Research Reagent Solutions for Image Classification Experiments
| Reagent / Resource | Function & Importance | Example Specifications |
|---|---|---|
| Image Datasets | Provides labeled data for training and evaluation. Essential for benchmarking. | ImageNet (1.2M+ images, 1K classes) [1], or domain-specific sets like traditional food images [13]. |
| Deep Learning Framework | Software library for building and training neural networks. | TensorFlow, PyTorch, or Keras. The ResNet50 blur study used Hugging Face's transformers library [95]. |
| GPU Hardware | Accelerates model training through parallel processing, making deep learning feasible. | Modern GPUs (e.g., NVIDIA series). AlexNet was trained on two NVIDIA GTX 580 GPUs [1]. |
| Data Augmentation Pipeline | Artificially expands training data to improve model generalization and prevent overfitting. | Techniques include random cropping, horizontal flipping, and color jittering [1] [13]. |
| Evaluation Metrics | Quantifies model performance objectively and allows for comparison. | Accuracy, Precision, Recall, F1-Score [13] [9]. |
Core Experimental Workflow:
- Data Acquisition and Curation: Gather a relevant dataset, such as the Indonesian traditional food dataset comprising 24 categories and over 4,000 images [13].
- Data Preprocessing and Augmentation:
- Resize all input images to the model's required size (e.g., 224x224 pixels for both AlexNet and ResNet50) [13].
- Apply data augmentation techniques to the training set. This typically includes random cropping (e.g., extracting 224x224 patches from a 256x256 image), horizontal flipping, and color jittering to increase data variety and robustness [1] [13].
- Normalize pixel values using the mean and standard deviation of the training dataset.
- Model Training:
- Initialize the models. This can be done from scratch or using transfer learning with pre-trained weights from a large dataset like ImageNet.
- Train the models using an optimizer like Stochastic Gradient Descent (SGD) with momentum (e.g., momentum of 0.9) and weight decay (e.g., 0.0005) for regularization [1].
- Employ a learning rate schedule, manually reducing the learning rate (e.g., by a factor of 10) when the validation error stops improving [1].
- Model Evaluation:
- Use a rigorous validation method such as 5-fold cross-validation to ensure reliability of results [13].
- Evaluate the trained models on a held-out test set using the predefined metrics (Accuracy, F1-Score, etc.).
- For robustness testing, corrupt test images using techniques like progressive Gaussian blurring to simulate low-quality inputs and observe performance degradation [95].
Figure 1: Experimental Workflow for Model Comparison
Decision Framework: AlexNet vs. ResNet50
The choice between AlexNet and ResNet50 is not about which model is universally better, but which is more suitable for a given set of constraints and objectives. The following diagram provides a logical pathway for making this decision.
Figure 2: Model Selection Decision Framework
Choose AlexNet when:
- Computational Resources are Limited: AlexNet has far fewer parameters and layers than ResNet50, making it faster to train and deploy on hardware with limited memory or processing power [9].
- Inference Speed is Critical: For real-time applications where low latency is essential, AlexNet's simpler architecture can provide quicker predictions.
- The Task is Relatively Simple: For classifying less complex images, such as diagrams or images with clear, distinct features, AlexNet's representational capacity may be sufficient and more efficient [9].
Choose ResNet50 when:
- High Accuracy is the Primary Goal: For most complex, real-world image classification tasks involving natural images, ResNet50's deeper architecture and residual learning will almost certainly deliver superior accuracy [13].
- The Task Involves Fine-Grained Details: ResNet50 is better equipped to learn subtle and complex features due to its depth and the effectiveness of its skip connections in mitigating performance degradation.
A Note on Low-Quality Image Classification: Research indicates that both architectures struggle with significantly degraded inputs, such as heavily blurred images [95]. While deeper models like ResNet50 can be more robust to minor degradations, their performance also drops sharply when key features are obscured. Therefore, in low-quality image research, the choice of model might be secondary to the development and application of specialized pre-processing or robustness-enhancing techniques [96] [95].
In the evolving landscape of deep learning, both AlexNet and ResNet50 hold significant places. AlexNet remains a compelling choice for prototyping, educational purposes, and applications where computational efficiency is paramount. In contrast, ResNet50 represents the state-of-the-art for accuracy-driven tasks and has become a standard backbone for many advanced vision systems. The decision between them hinges on a clear understanding of the project's specific requirements, data characteristics, and operational constraints. By applying the structured comparison and decision framework provided in this guide, researchers and practitioners can navigate this fundamental trade-off with confidence.
Conclusion
The comparative analysis reveals that the choice between AlexNet and ResNet50 for low-quality image classification is not absolute but context-dependent. AlexNet, with its simpler architecture, offers greater computational efficiency and can be sufficient for tasks with less complex features or severe resource constraints. In contrast, ResNet50's deeper architecture and residual connections provide superior representational power for extracting subtle patterns from degraded data, often leading to higher accuracy at the cost of increased computational demand. For biomedical researchers, this implies that AlexNet may be suitable for rapid prototyping or analyzing images with gross morphological changes, while ResNet50 is better suited for fine-grained classification in diagnostics or drug development, such as analyzing low-resolution histopathology slides or noisy microscopy images. Future directions should focus on developing hybrid approaches, architecturally efficient models, and specialized preprocessing techniques tailored to the unique challenges of clinical and biomedical imagery to further enhance the practical application of deep learning in healthcare.
References
- 1. AlexNet [https://en.wikipedia.org/wiki/AlexNet]
- 2. The Story of AlexNet: A Historical Milestone in Deep Learning [https://medium.com/@fahey_james/the-story-of-alexnet-a-historical-milestone-in-deep-learning-79878a707dd5]
- 3. AlexNet: A Revolutionary Deep Learning Architecture [https://viso.ai/deep-learning/alexnet/]
- 4. Introduction to Alexnet Architecture [https://www.analyticsvidhya.com/blog/2021/03/introduction-to-the-architecture-of-alexnet/]
- 5. AlexNet Architecture Explained [https://medium.com/@siddheshb008/alexnet-architecture-explained-b6240c528bd5]
- 6. The Annotated ResNet-50 [https://towardsdatascience.com/the-annotated-resnet-50-a6c536034758/]
- 7. Exploring ResNet50: An In-Depth Look at the Model ... [https://medium.com/@nitishkundu1993/exploring-resnet50-an-in-depth-look-at-the-model-architecture-and-code-implementation-d8d8fa67e46f]
- 8. Understanding ResNet50: A Comprehensive Guide to the ... [https://www.thinkingstack.ai/blog/business-use-cases-11/a-comprehensive-guide-to-resnet50-architecture-and-implementation-56]
- 9. Comparative Analysis of AlexNet, ResNet-50, and VGG-19 ... [https://www.mdpi.com/2076-3417/15/6/2928]
- 10. Comparative analysis of convolutional neural networks and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12209302/]
- 11. Residual Networks (ResNet) - Deep Learning [https://www.geeksforgeeks.org/deep-learning/residual-networks-resnet-deep-learning/]
- 12. What Is ResNet-50? [https://blog.roboflow.com/what-is-resnet-50/]
- 13. Comparison of AlexNet and ResNet50 Model Performance ... [https://newinera.com/index.php/JournalLaMultiapp/article/view/2269]
- 14. LR0.FM: Low-Resolution Zero-Shot Classification ... [https://arxiv.org/html/2502.03950v2]
- 15. Performance comparison of machine learning driven ... [https://www.sciencedirect.com/science/article/pii/S2405844023023150]
- 16. 8.1. Deep Convolutional Neural Networks (AlexNet) [http://d2l.ai/chapter_convolutional-modern/alexnet.html]
- 17. A quality assessment algorithm for no-reference images ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11888849/]
- 18. A Complete Guide to Image Super-Resolution in Deep ... [https://www.digitalocean.com/community/tutorials/image-super-resolution]
- 19. 10 Best AI Image Enhancers for 2025: I Tested Then All & ... [https://medium.com/freelancers-hub/i-tried-7-ai-image-enhancers-heres-my-review-about-what-s-the-best-d4dbba08b6dd]
- 20. Everything You Need to Know About Image Formats In 2025 [https://webdesignerdepot.com/everything-you-need-to-know-about-image-formats-in-2024/]
- 21. How to Optimize Images for Organic Search [2025 Update] [https://www.techwyse.com/blog/digital-marketing-101/how-to-optimize-images-for-organic-search-2025-update]
- 22. A deep image classification model based on prior feature ... [https://www.nature.com/articles/s41598-024-63818-x]
- 23. A comparative analysis of eleven neural networks ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8461289/]
- 24. Resnet Architecture Explained [https://medium.com/@siddheshb008/resnet-architecture-explained-47309ea9283d]
- 25. Effects of Degradations on Deep Neural Network ... [https://arxiv.org/html/1807.10108v6]
- 26. A Data-Centric Perspective on the Influence of Image Data ... [https://arxiv.org/html/2509.24420v1]
- 27. The AlexNet HSD model for industrial heritage damage ... [https://www.nature.com/articles/s41598-025-12257-3]
- 28. Style classification of media painting images by integrating ... [https://www.sciencedirect.com/science/article/pii/S2405844024032092]
- 29. A Comparative Study of GoogleNet, AlexNet, and ResNet-50 [https://www.iieta.org/journals/isi/paper/10.18280/isi.280312]
- 30. Recent Facial Image Preprocessing Techniques: A Review [https://www.mdpi.com/2673-4591/84/1/39]
- 31. Performance evaluation of reduced complexity deep neural ... [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0319859]
- 32. Best Practices for Training Deep Learning Models in AI [https://fonzi.ai/blog/best-practices-deep-learning-models]
- 33. Data Preprocessing in Machine Learning: Steps & Best ... [https://lakefs.io/blog/data-preprocessing-in-machine-learning/]
- 34. PyTorch vs TensorFlow 2025: Which one wins after 72 ... [https://dev.to/dev_tips/pytorch-vs-tensorflow-2025-which-one-wins-after-72-hours-a2b]
- 35. Ultimate guide to the TensorFlow library in Python [https://deepnote.com/blog/ultimate-guide-to-the-tensorflow-library-in-python]
- 36. Data Augmentation: The Ultimate Guide for 2025 [https://www.ultralytics.com/blog/the-ultimate-guide-to-data-augmentation-in-2025]
- 37. Guide To Data Augmentation For Image Classification [https://averroes.ai/blog/guide-to-data-augmentation-for-image-classification]
- 38. Image Classification: State-of-the-Art Models in 2025 [https://madailab.com/image-classification-state-of-the-art-models-in-2025]
- 39. Steps to Build a Data Augmentation Pipeline in 2025 [https://www.unitxlabs.com/resources/data-augmentation-pipeline-2025/]
- 40. Enhancing Image Classification with Augmentation: Data ... [https://arxiv.org/html/2502.18691v1]
- 41. The 2025 Low-Power Computer Vision Challenge [https://www.computer.org/publications/tech-news/insider-membership-news/2025-low-power-computer-vision-challenge]
- 42. Transfer learning for medical image classification: a literature ... [https://bmcmedimaging.biomedcentral.com/articles/10.1186/s12880-022-00793-7]
- 43. AlexNet: The Architecture that Challenged CNNs [https://medium.com/data-science/alexnet-the-architecture-that-challenged-cnns-e406d5297951]
- 44. Supercharge Your AI: ResNet50 Transfer Learning ... [https://medium.com/@paravisionlab/supercharge-your-ai-resnet50-transfer-learning-unleashed-b7c0e40976c4]
- 45. Transfer learning with fine-tuned deep CNN ResNet50 model ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8933872/]
- 46. Improving breast cancer classification in fine-grain ... [https://www.sciencedirect.com/science/article/abs/pii/S1746809425002010]
- 47. Enhanced ResNet-50 with Multi-Feature Fusion for Robust ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12386159/]
- 48. Human Activity Recognition with Noise-Injected Time ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12467874/]
- 49. Ditch the Denoiser: Emergence of Noise Robustness in ... [https://arxiv.org/html/2505.12191v2]
- 50. ResNet and its application to medical image processing [https://www.sciencedirect.com/science/article/abs/pii/S0169260723003255]
- 51. Style classification of media painting images by integrating ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10944206/]
- 52. MedNet: a lightweight attention-augmented CNN for ... [https://www.nature.com/articles/s41598-025-25857-w]
- 53. Development of revised ResNet-50 for diabetic retinopathy ... [https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-023-05293-1]
- 54. The Effect of Image Resolution on Deep Learning in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8017385/]
- 55. The Math Behind Deep CNN - AlexNet [https://towardsdatascience.com/the-math-behind-deep-cnn-alexnet-738d858e5a2f/]
- 56. Vanishing Gradient Problem in Deep Learning [https://medium.com/@amanatulla1606/vanishing-gradient-problem-in-deep-learning-understanding-intuition-and-solutions-da90ef4ecb54]
- 57. Vanishing Gradient Problem in Deep Learning: Explained [https://www.digitalocean.com/community/tutorials/vanishing-gradient-problem]
- 58. Understanding ResNet-50: Solving the Vanishing Gradient ... [https://medium.com/@sandushiw98/understanding-resnet-50-solving-the-vanishing-gradient-problem-with-skip-connections-5591fcb7ff74]
- 59. Why do ResNets avoid the vanishing gradient problem? [https://ai.stackexchange.com/questions/17764/why-do-resnets-avoid-the-vanishing-gradient-problem]
- 60. Vanishing and Exploding Gradients Problems in Deep ... [https://www.geeksforgeeks.org/deep-learning/vanishing-and-exploding-gradients-problems-in-deep-learning/]
- 61. AlexNet: The Breakthrough CNN Model that Transformed ... [https://medium.com/@prakash.arun01/alexnet-the-breakthrough-cnn-model-that-transformed-deep-learning-d50713d09350]
- 62. Comparative Deep Learning Analysis of Regularization ... [https://www.preprints.org/manuscript/202511.0501]
- 63. Casing Collar Identification using AlexNet-based Neural ... [https://arxiv.org/html/2511.00129v1]
- 64. Adding noise to the data to reduce overfitting . . . How does ... [https://statmodeling.stat.columbia.edu/2025/10/03/adding-noise-to-the-data-to-reduce-overfitting-how-does-that-work/]
- 65. Train Neural Networks With Noise to Reduce Overfitting [https://www.geeksforgeeks.org/machine-learning/train-neural-networks-with-noise-to-reduce-overfitting/]
- 66. How do you prevent in deep learning with small datasets? [https://medium.com/@sharetonschool/how-do-you-prevent-in-deep-learning-with-small-datasets-745acb036f71]
- 67. Benchmarking ResNet50 for Image Classification [https://itea.org/journals/volume-45-3/benchmarking-resnet50-for-image-classification/]
- 68. TPU vs GPU: What's the Difference in 2025? [https://www.cloudoptimo.com/blog/tpu-vs-gpu-what-is-the-difference-in-2025/]
- 69. Comparing different deep learning architectures for ... [https://www.nature.com/articles/s41598-020-70479-z]
- 70. ResNet-50 Training Throughput on Integrated, Laptop, and ... [https://arxiv.org/html/2508.18206v1]
- 71. (PDF) Evaluating ResNet for Multi-Class Lung Cancer Detection... 50 [https://www.academia.edu/143228843/Evaluating_ResNet50_for_Multi_Class_Lung_Cancer_Detection_A_Comparative_and_Explainable_AI_Approach_on_CT_Scans_Arif_Barlas_%C3%87%C3%B6lge%C3%A7en_Krti_Tallam]
- 72. Enhanced ResNet50 for Diabetic Retinopathy Classification [https://www.mdpi.com/2227-7390/13/10/1557]
- 73. A improved pooling method for convolutional neural networks [https://www.nature.com/articles/s41598-024-51258-6]
- 74. integrative machine learning models and advanced attention ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11255163/]
- 75. Ensemble genetic and CNN model-based image ... [https://www.nature.com/articles/s41598-024-76178-3]
- 76. A systematic review of hyperparameter optimization ... [https://www.sciencedirect.com/science/article/pii/S2772662224000742]
- 77. A ResNet-50–UNet Hybrid with Whale Optimization ... [https://www.mdpi.com/2075-4418/15/23/2975]
- 78. MSPO: A machine learning hyperparameter optimization ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12277558/]
- 79. Impact of Hyperparameter Optimization on the Accuracy ... [https://arxiv.org/html/2507.23315v1]
- 80. Performance comparison and application of deep-learning- ... [https://www.spiedigitallibrary.org/conference-proceedings-of-spie/13550/135504E/Performance-comparison-and-application-of-deep-learning-based-image-recognition/10.1117/12.3059903.full]
- 81. Evaluation of deep learning models using explainable AI ... [https://www.nature.com/articles/s41598-025-14306-3]
- 82. WEEK 5: TRAININGS RESNET-50, ALEXNET, VGG16 [https://medium.com/bbm406f19/week-5-trainings-resnet-50-alexnet-vgg16-90e79b9f23f3]
- 83. Image Classification Using ResNet-50 Network [https://www.mindspore.cn/tutorial/training/en/r1.1/advanced_use/cv_resnet50.html]
- 84. Training the ResNet50 model on the ImageNet data set [https://www.aime.info/blog/en/resnet50-training-with-imagenet/]
- 85. Research on Image Data Augmentation and Accurate ... [https://www.mdpi.com/2227-9717/13/12/3802]
- 86. Image Classification with ResNet (PyTorch) | by Ang Li-Lian [https://medium.com/@anglilian/image-classification-with-resnet-pytorch-1e48a4c33905]
- 87. Comparison of Full-Reference Image Quality Models for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7817470/]
- 88. VQualA 2025 Challenge on Image Super-Resolution ... [https://arxiv.org/html/2509.06413v1]
- 89. Visual interpretability of image-based classification models ... [https://www.nature.com/articles/s41467-024-51136-9]
- 90. Interpretability in Image Classification with Improved Visual ... [https://arxiv.org/html/2403.05658]
- 91. The Annotated ResNet-50 [https://medium.com/data-science/the-annotated-resnet-50-a6c536034758]
- 92. Quantitative and Qualitative Analysis of 18 Deep ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9813876/]
- 93. CNN Architecture Visualization (AlexNet) [https://toshibakamruzzaman.medium.com/cnn-architecture-part-2-alexnet-38dc1bc97e46]
- 94. Feature Visualization [https://distill.pub/2017/feature-visualization]
- 95. Analyzing the Robustness of Image with Classification - ResNet ... 50 [https://medium.com/@robinsah425/analyzing-the-robustness-of-image-classification-with-resnet-50-how-blur-affects-model-accuracy-471dc3ad5ef1]
- 96. LR0.FM: Low-Res Benchmark and Improving robustness ... [https://openreview.net/forum?id=AsFxRSLtqR]